 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgetttLRM: Test-Time Training for Long Context and Autoregressive 3D Reconstruction
Feb 23, 2026We propose tttLRM, a novel large 3D reconstruction model that leverages a Test-Time Training (TTT) layer to enable long-context, autoregressive 3D reconstruction with linear computational complexity, further scaling the model's capability. Our framework efficiently compresses multiple image observations into the fast weights of the TTT layer, forming an implicit 3D representation in the latent space that can be decoded into various explicit formats, such as Gaussian Splats (GS) for downstream applications. The online learning variant of our model supports progressive 3D reconstruction and refinement from streaming observations. We demonstrate that pretraining on novel view synthesis tasks effectively transfers to explicit 3D modeling, resulting in improved reconstruction quality and faster convergence. Extensive experiments show that our method achieves superior performance in feedforward 3D Gaussian reconstruction compared to state-of-the-art approaches on both objects and scenes.
Residual Primitive Fitting of 3D Shapes with SuperFrusta
Dec 09, 2025We introduce a framework for converting 3D shapes into compact and editable assemblies of analytic primitives, directly addressing the persistent trade-off between reconstruction fidelity and parsimony. Our approach combines two key contributions: a novel primitive, termed SuperFrustum, and an iterative fiting algorithm, Residual Primitive Fitting (ResFit). SuperFrustum is an analytical primitive that is simultaneously (1) expressive, being able to model various common solids such as cylinders, spheres, cones & their tapered and bent forms, (2) editable, being compactly parameterized with 8 parameters, and (3) optimizable, with a sign distance field differentiable w.r.t. its parameters almost everywhere. ResFit is an unsupervised procedure that interleaves global shape analysis with local optimization, iteratively fitting primitives to the unexplained residual of a shape to discover a parsimonious yet accurate decompositions for each input shape. On diverse 3D benchmarks, our method achieves state-of-the-art results, improving IoU by over 9 points while using nearly half as many primitives as prior work. The resulting assemblies bridge the gap between dense 3D data and human-controllable design, producing high-fidelity and editable shape programs.
Reusing Computation in Text-to-Image Diffusion for Efficient Generation of Image Sets
Aug 28, 2025Text-to-image diffusion models enable high-quality image generation but are computationally expensive. While prior work optimizes per-inference efficiency, we explore an orthogonal approach: reducing redundancy across correlated prompts. Our method leverages the coarse-to-fine nature of diffusion models, where early denoising steps capture shared structures among similar prompts. We propose a training-free approach that clusters prompts based on semantic similarity and shares computation in early diffusion steps. Experiments show that for models trained conditioned on image embeddings, our approach significantly reduces compute cost while improving image quality. By leveraging UnClip's text-to-image prior, we enhance diffusion step allocation for greater efficiency. Our method seamlessly integrates with existing pipelines, scales with prompt sets, and reduces the environmental and financial burden of large-scale text-to-image generation. Project page: https://ddecatur.github.io/hierarchical-diffusion/
RigAnything: Template-Free Autoregressive Rigging for Diverse 3D Assets
Feb 13, 2025


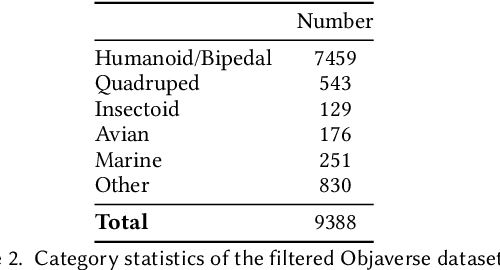
We present RigAnything, a novel autoregressive transformer-based model, which makes 3D assets rig-ready by probabilistically generating joints, skeleton topologies, and assigning skinning weights in a template-free manner. Unlike most existing auto-rigging methods, which rely on predefined skeleton template and are limited to specific categories like humanoid, RigAnything approaches the rigging problem in an autoregressive manner, iteratively predicting the next joint based on the global input shape and the previous prediction. While autoregressive models are typically used to generate sequential data, RigAnything extends their application to effectively learn and represent skeletons, which are inherently tree structures. To achieve this, we organize the joints in a breadth-first search (BFS) order, enabling the skeleton to be defined as a sequence of 3D locations and the parent index. Furthermore, our model improves the accuracy of position prediction by leveraging diffusion modeling, ensuring precise and consistent placement of joints within the hierarchy. This formulation allows the autoregressive model to efficiently capture both spatial and hierarchical relationships within the skeleton. Trained end-to-end on both RigNet and Objaverse datasets, RigAnything demonstrates state-of-the-art performance across diverse object types, including humanoids, quadrupeds, marine creatures, insects, and many more, surpassing prior methods in quality, robustness, generalizability, and efficiency. Please check our website for more details: https://www.liuisabella.com/RigAnything.
ShapeShifter: 3D Variations Using Multiscale and Sparse Point-Voxel Diffusion
Feb 04, 2025



This paper proposes ShapeShifter, a new 3D generative model that learns to synthesize shape variations based on a single reference model. While generative methods for 3D objects have recently attracted much attention, current techniques often lack geometric details and/or require long training times and large resources. Our approach remedies these issues by combining sparse voxel grids and point, normal, and color sampling within a multiscale neural architecture that can be trained efficiently and in parallel. We show that our resulting variations better capture the fine details of their original input and can handle more general types of surfaces than previous SDF-based methods. Moreover, we offer interactive generation of 3D shape variants, allowing more human control in the design loop if needed.
PhysAvatar: Learning the Physics of Dressed 3D Avatars from Visual Observations
Apr 09, 2024



Modeling and rendering photorealistic avatars is of crucial importance in many applications. Existing methods that build a 3D avatar from visual observations, however, struggle to reconstruct clothed humans. We introduce PhysAvatar, a novel framework that combines inverse rendering with inverse physics to automatically estimate the shape and appearance of a human from multi-view video data along with the physical parameters of the fabric of their clothes. For this purpose, we adopt a mesh-aligned 4D Gaussian technique for spatio-temporal mesh tracking as well as a physically based inverse renderer to estimate the intrinsic material properties. PhysAvatar integrates a physics simulator to estimate the physical parameters of the garments using gradient-based optimization in a principled manner. These novel capabilities enable PhysAvatar to create high-quality novel-view renderings of avatars dressed in loose-fitting clothes under motions and lighting conditions not seen in the training data. This marks a significant advancement towards modeling photorealistic digital humans using physically based inverse rendering with physics in the loop. Our project website is at: https://qingqing-zhao.github.io/PhysAvatar
GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation
Mar 21, 2024



We introduce GRM, a large-scale reconstructor capable of recovering a 3D asset from sparse-view images in around 0.1s. GRM is a feed-forward transformer-based model that efficiently incorporates multi-view information to translate the input pixels into pixel-aligned Gaussians, which are unprojected to create a set of densely distributed 3D Gaussians representing a scene. Together, our transformer architecture and the use of 3D Gaussians unlock a scalable and efficient reconstruction framework. Extensive experimental results demonstrate the superiority of our method over alternatives regarding both reconstruction quality and efficiency. We also showcase the potential of GRM in generative tasks, i.e., text-to-3D and image-to-3D, by integrating it with existing multi-view diffusion models. Our project website is at: https://justimyhxu.github.io/projects/grm/.
Gaussian Shell Maps for Efficient 3D Human Generation
Nov 29, 2023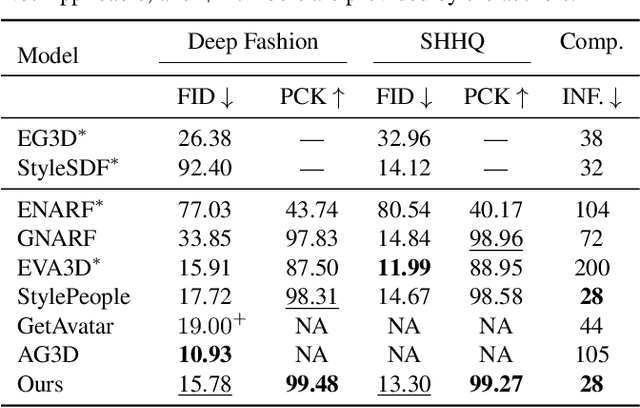



Efficient generation of 3D digital humans is important in several industries, including virtual reality, social media, and cinematic production. 3D generative adversarial networks (GANs) have demonstrated state-of-the-art (SOTA) quality and diversity for generated assets. Current 3D GAN architectures, however, typically rely on volume representations, which are slow to render, thereby hampering the GAN training and requiring multi-view-inconsistent 2D upsamplers. Here, we introduce Gaussian Shell Maps (GSMs) as a framework that connects SOTA generator network architectures with emerging 3D Gaussian rendering primitives using an articulable multi shell--based scaffold. In this setting, a CNN generates a 3D texture stack with features that are mapped to the shells. The latter represent inflated and deflated versions of a template surface of a digital human in a canonical body pose. Instead of rasterizing the shells directly, we sample 3D Gaussians on the shells whose attributes are encoded in the texture features. These Gaussians are efficiently and differentiably rendered. The ability to articulate the shells is important during GAN training and, at inference time, to deform a body into arbitrary user-defined poses. Our efficient rendering scheme bypasses the need for view-inconsistent upsamplers and achieves high-quality multi-view consistent renderings at a native resolution of $512 \times 512$ pixels. We demonstrate that GSMs successfully generate 3D humans when trained on single-view datasets, including SHHQ and DeepFashion.
Pose-to-Motion: Cross-Domain Motion Retargeting with Pose Prior
Oct 31, 2023



Creating believable motions for various characters has long been a goal in computer graphics. Current learning-based motion synthesis methods depend on extensive motion datasets, which are often challenging, if not impossible, to obtain. On the other hand, pose data is more accessible, since static posed characters are easier to create and can even be extracted from images using recent advancements in computer vision. In this paper, we utilize this alternative data source and introduce a neural motion synthesis approach through retargeting. Our method generates plausible motions for characters that have only pose data by transferring motion from an existing motion capture dataset of another character, which can have drastically different skeletons. Our experiments show that our method effectively combines the motion features of the source character with the pose features of the target character, and performs robustly with small or noisy pose data sets, ranging from a few artist-created poses to noisy poses estimated directly from images. Additionally, a conducted user study indicated that a majority of participants found our retargeted motion to be more enjoyable to watch, more lifelike in appearance, and exhibiting fewer artifacts. Project page: https://cyanzhao42.github.io/pose2motion
State of the Art on Diffusion Models for Visual Computing
Oct 11, 2023The field of visual computing is rapidly advancing due to the emergence of generative artificial intelligence (AI), which unlocks unprecedented capabilities for the generation, editing, and reconstruction of images, videos, and 3D scenes. In these domains, diffusion models are the generative AI architecture of choice. Within the last year alone, the literature on diffusion-based tools and applications has seen exponential growth and relevant papers are published across the computer graphics, computer vision, and AI communities with new works appearing daily on arXiv. This rapid growth of the field makes it difficult to keep up with all recent developments. The goal of this state-of-the-art report (STAR) is to introduce the basic mathematical concepts of diffusion models, implementation details and design choices of the popular Stable Diffusion model, as well as overview important aspects of these generative AI tools, including personalization, conditioning, inversion, among others. Moreover, we give a comprehensive overview of the rapidly growing literature on diffusion-based generation and editing, categorized by the type of generated medium, including 2D images, videos, 3D objects, locomotion, and 4D scenes. Finally, we discuss available datasets, metrics, open challenges, and social implications. This STAR provides an intuitive starting point to explore this exciting topic for researchers, artists, and practitioners alike.