 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochasticSplats: Stochastic Rasterization for Sorting-Free 3D Gaussian Splatting
Mar 31, 20253D Gaussian splatting (3DGS) is a popular radiance field method, with many application-specific extensions. Most variants rely on the same core algorithm: depth-sorting of Gaussian splats then rasterizing in primitive order. This ensures correct alpha compositing, but can cause rendering artifacts due to built-in approximations. Moreover, for a fixed representation, sorted rendering offers little control over render cost and visual fidelity. For example, and counter-intuitively, rendering a lower-resolution image is not necessarily faster. In this work, we address the above limitations by combining 3D Gaussian splatting with stochastic rasterization. Concretely, we leverage an unbiased Monte Carlo estimator of the volume rendering equation. This removes the need for sorting, and allows for accurate 3D blending of overlapping Gaussians. The number of Monte Carlo samples further imbues 3DGS with a way to trade off computation time and quality. We implement our method using OpenGL shaders, enabling efficient rendering on modern GPU hardware. At a reasonable visual quality, our method renders more than four times faster than sorted rasterization.
RoMo: Robust Motion Segmentation Improves Structure from Motion
Nov 27, 2024
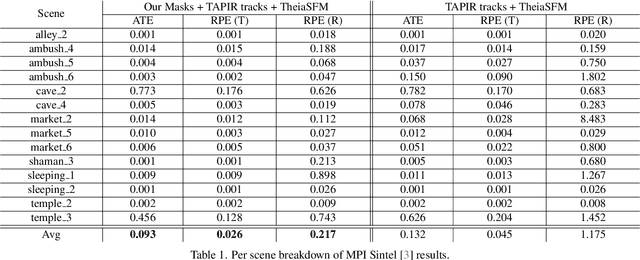


There has been extensive progress in the reconstruction and generation of 4D scenes from monocular casually-captured video. While these tasks rely heavily on known camera poses, the problem of finding such poses using structure-from-motion (SfM) often depends on robustly separating static from dynamic parts of a video. The lack of a robust solution to this problem limits the performance of SfM camera-calibration pipelines. We propose a novel approach to video-based motion segmentation to identify the components of a scene that are moving w.r.t. a fixed world frame. Our simple but effective iterative method, RoMo, combines optical flow and epipolar cues with a pre-trained video segmentation model. It outperforms unsupervised baselines for motion segmentation as well as supervised baselines trained from synthetic data. More importantly, the combination of an off-the-shelf SfM pipeline with our segmentation masks establishes a new state-of-the-art on camera calibration for scenes with dynamic content, outperforming existing methods by a substantial margin.
Cafca: High-quality Novel View Synthesis of Expressive Faces from Casual Few-shot Captures
Oct 01, 2024
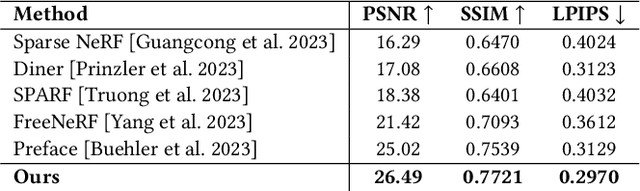

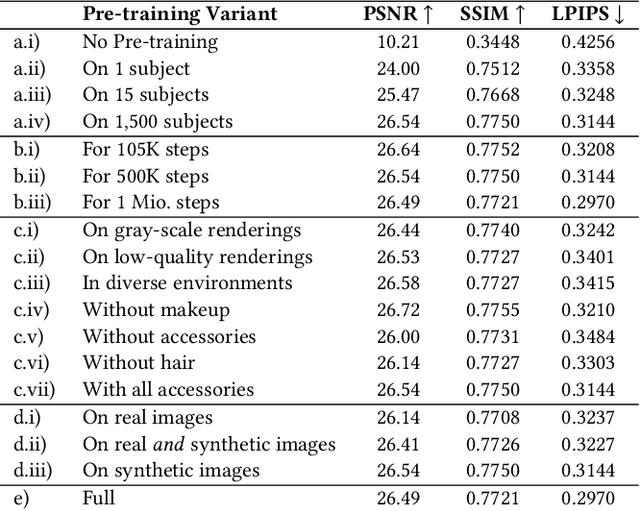
Volumetric modeling and neural radiance field representations have revolutionized 3D face capture and photorealistic novel view synthesis. However, these methods often require hundreds of multi-view input images and are thus inapplicable to cases with less than a handful of inputs. We present a novel volumetric prior on human faces that allows for high-fidelity expressive face modeling from as few as three input views captured in the wild. Our key insight is that an implicit prior trained on synthetic data alone can generalize to extremely challenging real-world identities and expressions and render novel views with fine idiosyncratic details like wrinkles and eyelashes. We leverage a 3D Morphable Face Model to synthesize a large training set, rendering each identity with different expressions, hair, clothing, and other assets. We then train a conditional Neural Radiance Field prior on this synthetic dataset and, at inference time, fine-tune the model on a very sparse set of real images of a single subject. On average, the fine-tuning requires only three inputs to cross the synthetic-to-real domain gap. The resulting personalized 3D model reconstructs strong idiosyncratic facial expressions and outperforms the state-of-the-art in high-quality novel view synthesis of faces from sparse inputs in terms of perceptual and photo-metric quality.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
SpotlessSplats: Ignoring Distractors in 3D Gaussian Splatting
Jun 28, 2024
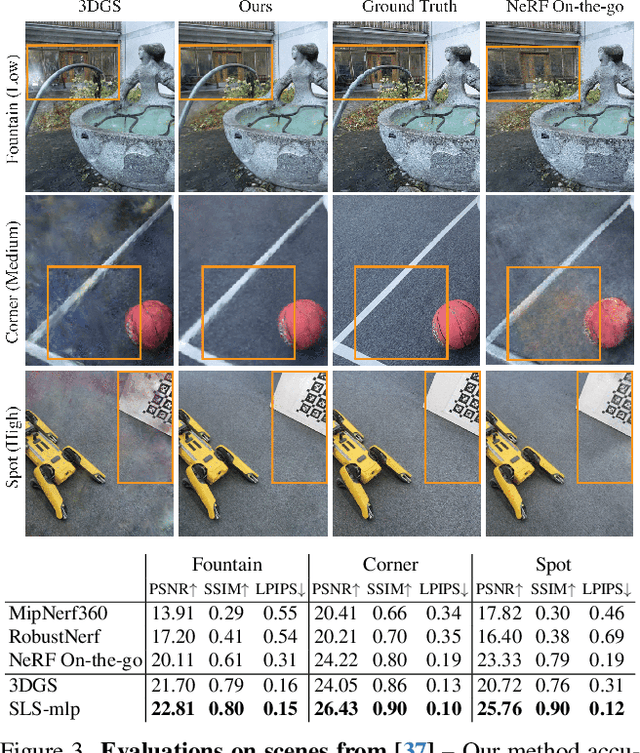

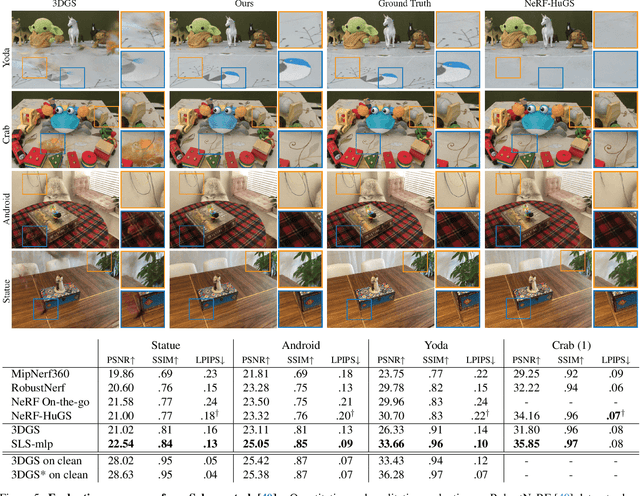
3D Gaussian Splatting (3DGS) is a promising technique for 3D reconstruction, offering efficient training and rendering speeds, making it suitable for real-time applications.However, current methods require highly controlled environments (no moving people or wind-blown elements, and consistent lighting) to meet the inter-view consistency assumption of 3DGS. This makes reconstruction of real-world captures problematic. We present SpotlessSplats, an approach that leverages pre-trained and general-purpose features coupled with robust optimization to effectively ignore transient distractors. Our method achieves state-of-the-art reconstruction quality both visually and quantitatively, on casual captures.
PhysAvatar: Learning the Physics of Dressed 3D Avatars from Visual Observations
Apr 09, 2024



Modeling and rendering photorealistic avatars is of crucial importance in many applications. Existing methods that build a 3D avatar from visual observations, however, struggle to reconstruct clothed humans. We introduce PhysAvatar, a novel framework that combines inverse rendering with inverse physics to automatically estimate the shape and appearance of a human from multi-view video data along with the physical parameters of the fabric of their clothes. For this purpose, we adopt a mesh-aligned 4D Gaussian technique for spatio-temporal mesh tracking as well as a physically based inverse renderer to estimate the intrinsic material properties. PhysAvatar integrates a physics simulator to estimate the physical parameters of the garments using gradient-based optimization in a principled manner. These novel capabilities enable PhysAvatar to create high-quality novel-view renderings of avatars dressed in loose-fitting clothes under motions and lighting conditions not seen in the training data. This marks a significant advancement towards modeling photorealistic digital humans using physically based inverse rendering with physics in the loop. Our project website is at: https://qingqing-zhao.github.io/PhysAvatar
Alchemist: Parametric Control of Material Properties with Diffusion Models
Dec 05, 2023
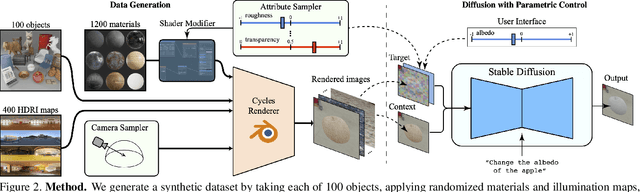


We propose a method to control material attributes of objects like roughness, metallic, albedo, and transparency in real images. Our method capitalizes on the generative prior of text-to-image models known for photorealism, employing a scalar value and instructions to alter low-level material properties. Addressing the lack of datasets with controlled material attributes, we generated an object-centric synthetic dataset with physically-based materials. Fine-tuning a modified pre-trained text-to-image model on this synthetic dataset enables us to edit material properties in real-world images while preserving all other attributes. We show the potential application of our model to material edited NeRFs.
ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Real Image
Oct 27, 2023


We introduce a 3D-aware diffusion model, ZeroNVS, for single-image novel view synthesis for in-the-wild scenes. While existing methods are designed for single objects with masked backgrounds, we propose new techniques to address challenges introduced by in-the-wild multi-object scenes with complex backgrounds. Specifically, we train a generative prior on a mixture of data sources that capture object-centric, indoor, and outdoor scenes. To address issues from data mixture such as depth-scale ambiguity, we propose a novel camera conditioning parameterization and normalization scheme. Further, we observe that Score Distillation Sampling (SDS) tends to truncate the distribution of complex backgrounds during distillation of 360-degree scenes, and propose "SDS anchoring" to improve the diversity of synthesized novel views. Our model sets a new state-of-the-art result in LPIPS on the DTU dataset in the zero-shot setting, even outperforming methods specifically trained on DTU. We further adapt the challenging Mip-NeRF 360 dataset as a new benchmark for single-image novel view synthesis, and demonstrate strong performance in this setting. Our code and data are at http://kylesargent.github.io/zeronvs/
Preface: A Data-driven Volumetric Prior for Few-shot Ultra High-resolution Face Synthesis
Sep 28, 2023NeRFs have enabled highly realistic synthesis of human faces including complex appearance and reflectance effects of hair and skin. These methods typically require a large number of multi-view input images, making the process hardware intensive and cumbersome, limiting applicability to unconstrained settings. We propose a novel volumetric human face prior that enables the synthesis of ultra high-resolution novel views of subjects that are not part of the prior's training distribution. This prior model consists of an identity-conditioned NeRF, trained on a dataset of low-resolution multi-view images of diverse humans with known camera calibration. A simple sparse landmark-based 3D alignment of the training dataset allows our model to learn a smooth latent space of geometry and appearance despite a limited number of training identities. A high-quality volumetric representation of a novel subject can be obtained by model fitting to 2 or 3 camera views of arbitrary resolution. Importantly, our method requires as few as two views of casually captured images as input at inference time.
ITI-GEN: Inclusive Text-to-Image Generation
Sep 11, 2023



Text-to-image generative models often reflect the biases of the training data, leading to unequal representations of underrepresented groups. This study investigates inclusive text-to-image generative models that generate images based on human-written prompts and ensure the resulting images are uniformly distributed across attributes of interest. Unfortunately, directly expressing the desired attributes in the prompt often leads to sub-optimal results due to linguistic ambiguity or model misrepresentation. Hence, this paper proposes a drastically different approach that adheres to the maxim that "a picture is worth a thousand words". We show that, for some attributes, images can represent concepts more expressively than text. For instance, categories of skin tones are typically hard to specify by text but can be easily represented by example images. Building upon these insights, we propose a novel approach, ITI-GEN, that leverages readily available reference images for Inclusive Text-to-Image GENeration. The key idea is learning a set of prompt embeddings to generate images that can effectively represent all desired attribute categories. More importantly, ITI-GEN requires no model fine-tuning, making it computationally efficient to augment existing text-to-image models. Extensive experiments demonstrate that ITI-GEN largely improves over state-of-the-art models to generate inclusive images from a prompt. Project page: https://czhang0528.github.io/iti-gen.