 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText To 3D Object Generation For Scalable Room Assembly
Apr 12, 2025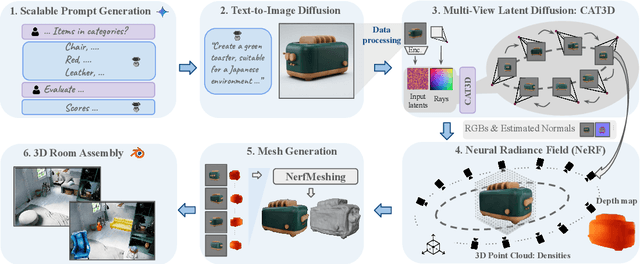



Modern machine learning models for scene understanding, such as depth estimation and object tracking, rely on large, high-quality datasets that mimic real-world deployment scenarios. To address data scarcity, we propose an end-to-end system for synthetic data generation for scalable, high-quality, and customizable 3D indoor scenes. By integrating and adapting text-to-image and multi-view diffusion models with Neural Radiance Field-based meshing, this system generates highfidelity 3D object assets from text prompts and incorporates them into pre-defined floor plans using a rendering tool. By introducing novel loss functions and training strategies into existing methods, the system supports on-demand scene generation, aiming to alleviate the scarcity of current available data, generally manually crafted by artists. This system advances the role of synthetic data in addressing machine learning training limitations, enabling more robust and generalizable models for real-world applications.
Cafca: High-quality Novel View Synthesis of Expressive Faces from Casual Few-shot Captures
Oct 01, 2024
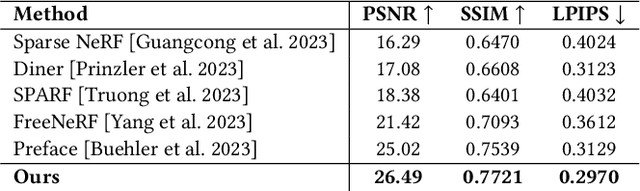

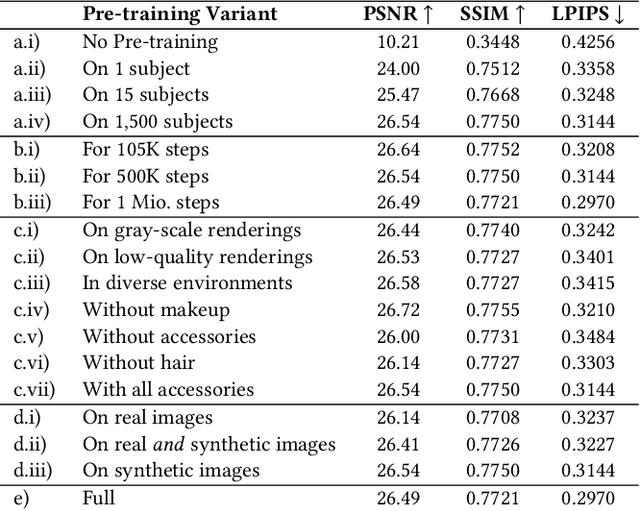
Volumetric modeling and neural radiance field representations have revolutionized 3D face capture and photorealistic novel view synthesis. However, these methods often require hundreds of multi-view input images and are thus inapplicable to cases with less than a handful of inputs. We present a novel volumetric prior on human faces that allows for high-fidelity expressive face modeling from as few as three input views captured in the wild. Our key insight is that an implicit prior trained on synthetic data alone can generalize to extremely challenging real-world identities and expressions and render novel views with fine idiosyncratic details like wrinkles and eyelashes. We leverage a 3D Morphable Face Model to synthesize a large training set, rendering each identity with different expressions, hair, clothing, and other assets. We then train a conditional Neural Radiance Field prior on this synthetic dataset and, at inference time, fine-tune the model on a very sparse set of real images of a single subject. On average, the fine-tuning requires only three inputs to cross the synthetic-to-real domain gap. The resulting personalized 3D model reconstructs strong idiosyncratic facial expressions and outperforms the state-of-the-art in high-quality novel view synthesis of faces from sparse inputs in terms of perceptual and photo-metric quality.
MagicMirror: Fast and High-Quality Avatar Generation with a Constrained Search Space
Apr 01, 2024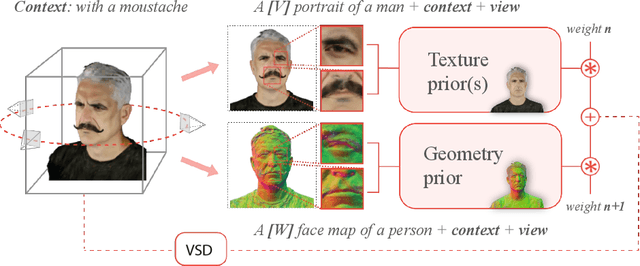



We introduce a novel framework for 3D human avatar generation and personalization, leveraging text prompts to enhance user engagement and customization. Central to our approach are key innovations aimed at overcoming the challenges in photo-realistic avatar synthesis. Firstly, we utilize a conditional Neural Radiance Fields (NeRF) model, trained on a large-scale unannotated multi-view dataset, to create a versatile initial solution space that accelerates and diversifies avatar generation. Secondly, we develop a geometric prior, leveraging the capabilities of Text-to-Image Diffusion Models, to ensure superior view invariance and enable direct optimization of avatar geometry. These foundational ideas are complemented by our optimization pipeline built on Variational Score Distillation (VSD), which mitigates texture loss and over-saturation issues. As supported by our extensive experiments, these strategies collectively enable the creation of custom avatars with unparalleled visual quality and better adherence to input text prompts. You can find more results and videos in our website: https://syntec-research.github.io/MagicMirror
Preface: A Data-driven Volumetric Prior for Few-shot Ultra High-resolution Face Synthesis
Sep 28, 2023NeRFs have enabled highly realistic synthesis of human faces including complex appearance and reflectance effects of hair and skin. These methods typically require a large number of multi-view input images, making the process hardware intensive and cumbersome, limiting applicability to unconstrained settings. We propose a novel volumetric human face prior that enables the synthesis of ultra high-resolution novel views of subjects that are not part of the prior's training distribution. This prior model consists of an identity-conditioned NeRF, trained on a dataset of low-resolution multi-view images of diverse humans with known camera calibration. A simple sparse landmark-based 3D alignment of the training dataset allows our model to learn a smooth latent space of geometry and appearance despite a limited number of training identities. A high-quality volumetric representation of a novel subject can be obtained by model fitting to 2 or 3 camera views of arbitrary resolution. Importantly, our method requires as few as two views of casually captured images as input at inference time.
Controllable Light Diffusion for Portraits
May 08, 2023



We introduce light diffusion, a novel method to improve lighting in portraits, softening harsh shadows and specular highlights while preserving overall scene illumination. Inspired by professional photographers' diffusers and scrims, our method softens lighting given only a single portrait photo. Previous portrait relighting approaches focus on changing the entire lighting environment, removing shadows (ignoring strong specular highlights), or removing shading entirely. In contrast, we propose a learning based method that allows us to control the amount of light diffusion and apply it on in-the-wild portraits. Additionally, we design a method to synthetically generate plausible external shadows with sub-surface scattering effects while conforming to the shape of the subject's face. Finally, we show how our approach can increase the robustness of higher level vision applications, such as albedo estimation, geometry estimation and semantic segmentation.
Learning Personalized High Quality Volumetric Head Avatars from Monocular RGB Videos
Apr 04, 2023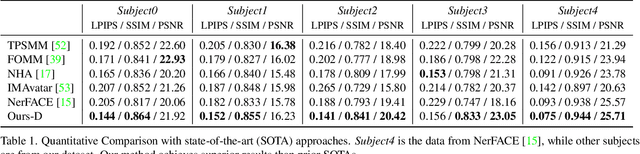
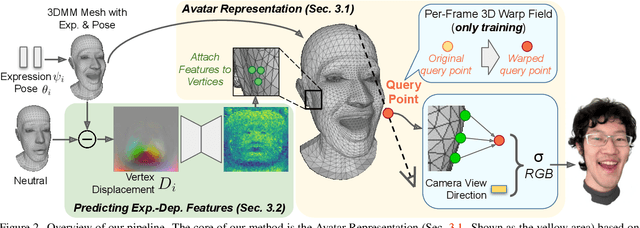
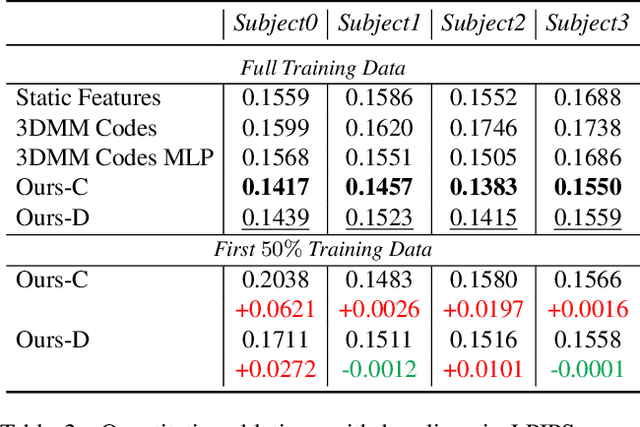
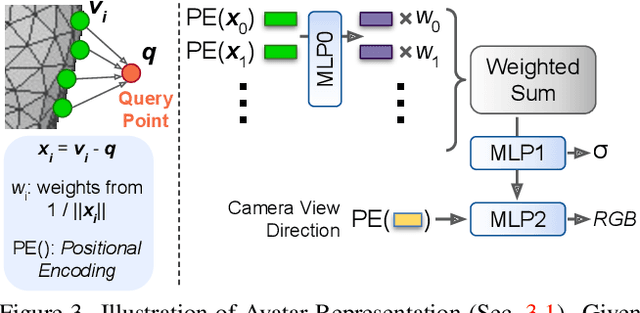
We propose a method to learn a high-quality implicit 3D head avatar from a monocular RGB video captured in the wild. The learnt avatar is driven by a parametric face model to achieve user-controlled facial expressions and head poses. Our hybrid pipeline combines the geometry prior and dynamic tracking of a 3DMM with a neural radiance field to achieve fine-grained control and photorealism. To reduce over-smoothing and improve out-of-model expressions synthesis, we propose to predict local features anchored on the 3DMM geometry. These learnt features are driven by 3DMM deformation and interpolated in 3D space to yield the volumetric radiance at a designated query point. We further show that using a Convolutional Neural Network in the UV space is critical in incorporating spatial context and producing representative local features. Extensive experiments show that we are able to reconstruct high-quality avatars, with more accurate expression-dependent details, good generalization to out-of-training expressions, and quantitatively superior renderings compared to other state-of-the-art approaches.
VoLux-GAN: A Generative Model for 3D Face Synthesis with HDRI Relighting
Jan 13, 2022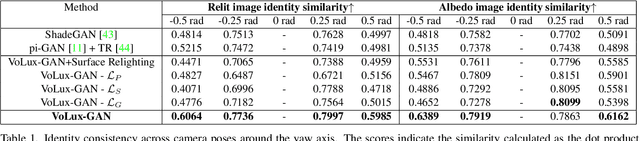
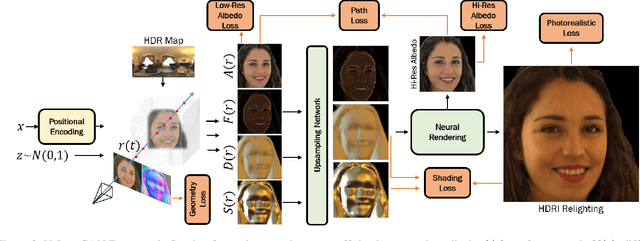
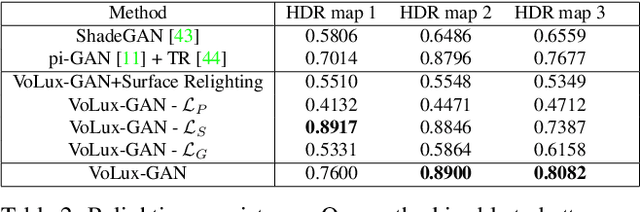

We propose VoLux-GAN, a generative framework to synthesize 3D-aware faces with convincing relighting. Our main contribution is a volumetric HDRI relighting method that can efficiently accumulate albedo, diffuse and specular lighting contributions along each 3D ray for any desired HDR environmental map. Additionally, we show the importance of supervising the image decomposition process using multiple discriminators. In particular, we propose a data augmentation technique that leverages recent advances in single image portrait relighting to enforce consistent geometry, albedo, diffuse and specular components. Multiple experiments and comparisons with other generative frameworks show how our model is a step forward towards photorealistic relightable 3D generative models.
NVS-MonoDepth: Improving Monocular Depth Prediction with Novel View Synthesis
Dec 22, 2021
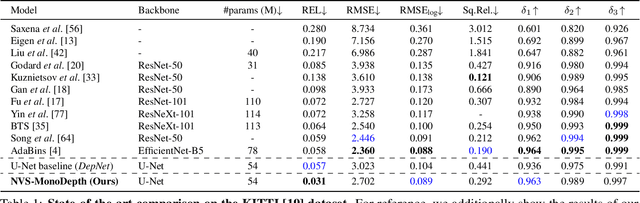
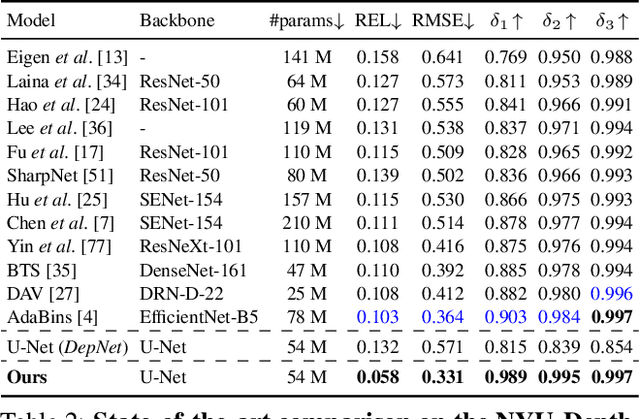
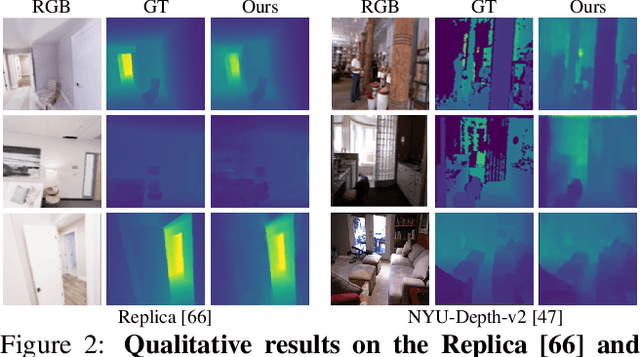
Building upon the recent progress in novel view synthesis, we propose its application to improve monocular depth estimation. In particular, we propose a novel training method split in three main steps. First, the prediction results of a monocular depth network are warped to an additional view point. Second, we apply an additional image synthesis network, which corrects and improves the quality of the warped RGB image. The output of this network is required to look as similar as possible to the ground-truth view by minimizing the pixel-wise RGB reconstruction error. Third, we reapply the same monocular depth estimation onto the synthesized second view point and ensure that the depth predictions are consistent with the associated ground truth depth. Experimental results prove that our method achieves state-of-the-art or comparable performance on the KITTI and NYU-Depth-v2 datasets with a lightweight and simple vanilla U-Net architecture.
* 8 pages (main paper), 9 pages (supplementary material), 14 figures, 4 tables
UnrealROX+: An Improved Tool for Acquiring Synthetic Data from Virtual 3D Environments
Apr 23, 2021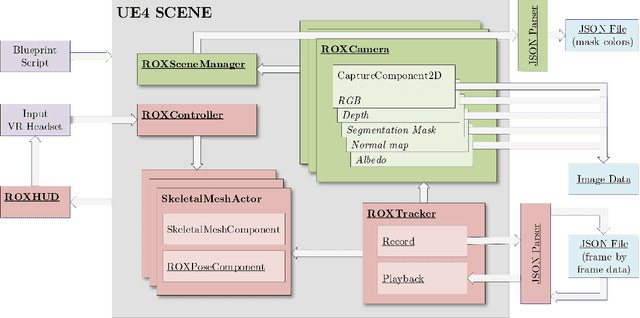



Synthetic data generation has become essential in last years for feeding data-driven algorithms, which surpassed traditional techniques performance in almost every computer vision problem. Gathering and labelling the amount of data needed for these data-hungry models in the real world may become unfeasible and error-prone, while synthetic data give us the possibility of generating huge amounts of data with pixel-perfect annotations. However, most synthetic datasets lack from enough realism in their rendered images. In that context UnrealROX generation tool was presented in 2019, allowing to generate highly realistic data, at high resolutions and framerates, with an efficient pipeline based on Unreal Engine, a cutting-edge videogame engine. UnrealROX enabled robotic vision researchers to generate realistic and visually plausible data with full ground truth for a wide variety of problems such as class and instance semantic segmentation, object detection, depth estimation, visual grasping, and navigation. Nevertheless, its workflow was very tied to generate image sequences from a robotic on-board camera, making hard to generate data for other purposes. In this work, we present UnrealROX+, an improved version of UnrealROX where its decoupled and easy-to-use data acquisition system allows to quickly design and generate data in a much more flexible and customizable way. Moreover, it is packaged as an Unreal plug-in, which makes it more comfortable to use with already existing Unreal projects, and it also includes new features such as generating albedo or a Python API for interacting with the virtual environment from Deep Learning frameworks.
H-GAN: the power of GANs in your Hands
Apr 21, 2021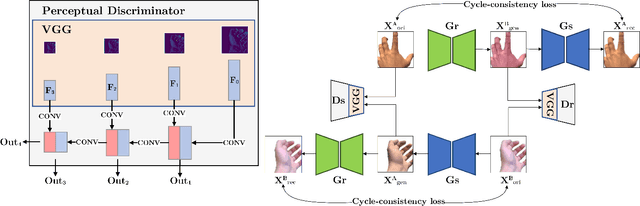
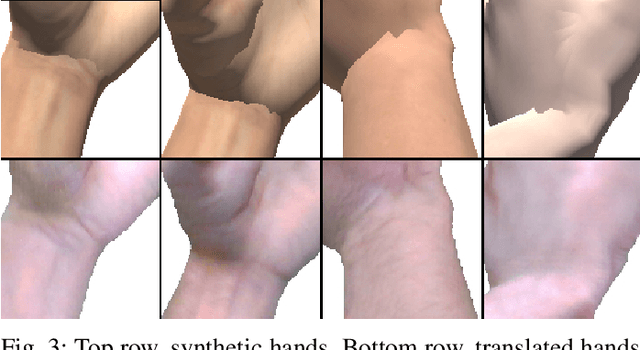
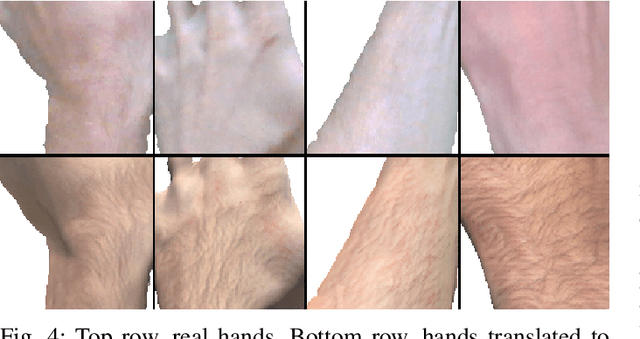
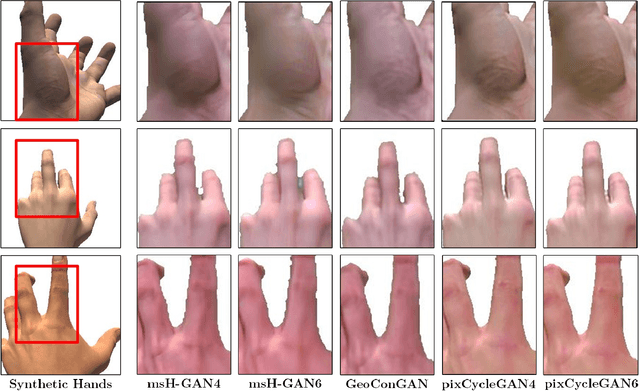
We present HandGAN (H-GAN), a cycle-consistent adversarial learning approach implementing multi-scale perceptual discriminators. It is designed to translate synthetic images of hands to the real domain. Synthetic hands provide complete ground-truth annotations, yet they are not representative of the target distribution of real-world data. We strive to provide the perfect blend of a realistic hand appearance with synthetic annotations. Relying on image-to-image translation, we improve the appearance of synthetic hands to approximate the statistical distribution underlying a collection of real images of hands. H-GAN tackles not only the cross-domain tone mapping but also structural differences in localized areas such as shading discontinuities. Results are evaluated on a qualitative and quantitative basis improving previous works. Furthermore, we relied on the hand classification task to claim our generated hands are statistically similar to the real domain of hands.