 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVS-MonoDepth: Improving Monocular Depth Prediction with Novel View Synthesis
Paper and Code
Dec 22, 2021
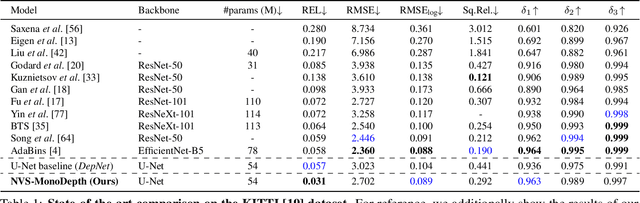
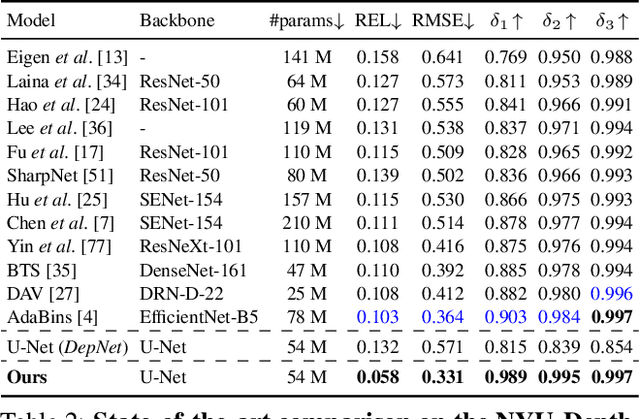
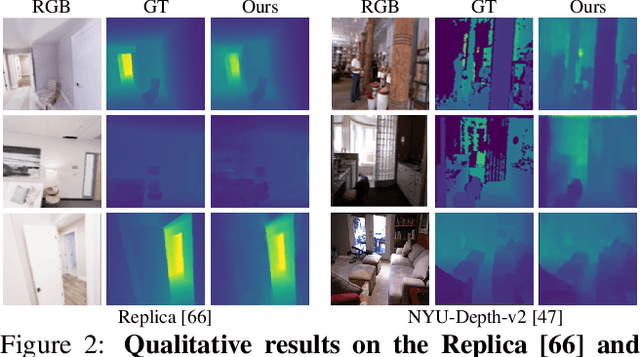
Building upon the recent progress in novel view synthesis, we propose its application to improve monocular depth estimation. In particular, we propose a novel training method split in three main steps. First, the prediction results of a monocular depth network are warped to an additional view point. Second, we apply an additional image synthesis network, which corrects and improves the quality of the warped RGB image. The output of this network is required to look as similar as possible to the ground-truth view by minimizing the pixel-wise RGB reconstruction error. Third, we reapply the same monocular depth estimation onto the synthesized second view point and ensure that the depth predictions are consistent with the associated ground truth depth. Experimental results prove that our method achieves state-of-the-art or comparable performance on the KITTI and NYU-Depth-v2 datasets with a lightweight and simple vanilla U-Net architecture.