 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLN-Pilot: Large Vision-Language Model as an Autonomous Indoor Drone Operator
Feb 05, 2026This paper introduces VLN-Pilot, a novel framework in which a large Vision-and-Language Model (VLLM) assumes the role of a human pilot for indoor drone navigation. By leveraging the multimodal reasoning abilities of VLLMs, VLN-Pilot interprets free-form natural language instructions and grounds them in visual observations to plan and execute drone trajectories in GPS-denied indoor environments. Unlike traditional rule-based or geometric path-planning approaches, our framework integrates language-driven semantic understanding with visual perception, enabling context-aware, high-level flight behaviors with minimal task-specific engineering. VLN-Pilot supports fully autonomous instruction-following for drones by reasoning about spatial relationships, obstacle avoidance, and dynamic reactivity to unforeseen events. We validate our framework on a custom photorealistic indoor simulation benchmark and demonstrate the ability of the VLLM-driven agent to achieve high success rates on complex instruction-following tasks, including long-horizon navigation with multiple semantic targets. Experimental results highlight the promise of replacing remote drone pilots with a language-guided autonomous agent, opening avenues for scalable, human-friendly control of indoor UAVs in tasks such as inspection, search-and-rescue, and facility monitoring. Our results suggest that VLLM-based pilots may dramatically reduce operator workload while improving safety and mission flexibility in constrained indoor environments.
Planning as Descent: Goal-Conditioned Latent Trajectory Synthesis in Learned Energy Landscapes
Dec 19, 2025We present Planning as Descent (PaD), a framework for offline goal-conditioned reinforcement learning that grounds trajectory synthesis in verification. Instead of learning a policy or explicit planner, PaD learns a goal-conditioned energy function over entire latent trajectories, assigning low energy to feasible, goal-consistent futures. Planning is realized as gradient-based refinement in this energy landscape, using identical computation during training and inference to reduce train-test mismatch common in decoupled modeling pipelines. PaD is trained via self-supervised hindsight goal relabeling, shaping the energy landscape around the planning dynamics. At inference, multiple trajectory candidates are refined under different temporal hypotheses, and low-energy plans balancing feasibility and efficiency are selected. We evaluate PaD on OGBench cube manipulation tasks. When trained on narrow expert demonstrations, PaD achieves state-of-the-art 95\% success, strongly outperforming prior methods that peak at 68\%. Remarkably, training on noisy, suboptimal data further improves success and plan efficiency, highlighting the benefits of verification-driven planning. Our results suggest learning to evaluate and refine trajectories provides a robust alternative to direct policy learning for offline, reward-free planning.
An Artificial Intelligence-based Assistant for the Visually Impaired
Nov 11, 2025

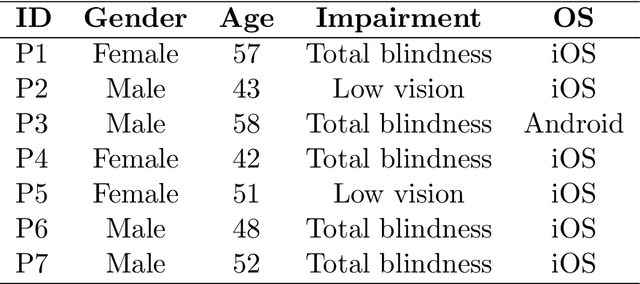

This paper describes an artificial intelligence-based assistant application, AIDEN, developed during 2023 and 2024, aimed at improving the quality of life for visually impaired individuals. Visually impaired individuals face challenges in identifying objects, reading text, and navigating unfamiliar environments, which can limit their independence and reduce their quality of life. Although solutions such as Braille, audio books, and screen readers exist, they may not be effective in all situations. This application leverages state-of-the-art machine learning algorithms to identify and describe objects, read text, and answer questions about the environment. Specifically, it uses You Only Look Once architectures and a Large Language and Vision Assistant. The system incorporates several methods to facilitate the user's interaction with the system and access to textual and visual information in an appropriate manner. AIDEN aims to enhance user autonomy and access to information, contributing to an improved perception of daily usability, as supported by user feedback.
Simulating Students with Large Language Models: A Review of Architecture, Mechanisms, and Role Modelling in Education with Generative AI
Nov 08, 2025



Simulated Students offer a valuable methodological framework for evaluating pedagogical approaches and modelling diverse learner profiles, tasks which are otherwise challenging to undertake systematically in real-world settings. Recent research has increasingly focused on developing such simulated agents to capture a range of learning styles, cognitive development pathways, and social behaviours. Among contemporary simulation techniques, the integration of large language models (LLMs) into educational research has emerged as a particularly versatile and scalable paradigm. LLMs afford a high degree of linguistic realism and behavioural adaptability, enabling agents to approximate cognitive processes and engage in contextually appropriate pedagogical dialogues. This paper presents a thematic review of empirical and methodological studies utilising LLMs to simulate student behaviour across educational environments. We synthesise current evidence on the capacity of LLM-based agents to emulate learner archetypes, respond to instructional inputs, and interact within multi-agent classroom scenarios. Furthermore, we examine the implications of such systems for curriculum development, instructional evaluation, and teacher training. While LLMs surpass rule-based systems in natural language generation and situational flexibility, ongoing concerns persist regarding algorithmic bias, evaluation reliability, and alignment with educational objectives. The review identifies existing technological and methodological gaps and proposes future research directions for integrating generative AI into adaptive learning systems and instructional design.
Autonomous Legged Mobile Manipulation for Lunar Surface Operations via Constrained Reinforcement Learning
Oct 14, 2025Robotics plays a pivotal role in planetary science and exploration, where autonomous and reliable systems are crucial due to the risks and challenges inherent to space environments. The establishment of permanent lunar bases demands robotic platforms capable of navigating and manipulating in the harsh lunar terrain. While wheeled rovers have been the mainstay for planetary exploration, their limitations in unstructured and steep terrains motivate the adoption of legged robots, which offer superior mobility and adaptability. This paper introduces a constrained reinforcement learning framework designed for autonomous quadrupedal mobile manipulators operating in lunar environments. The proposed framework integrates whole-body locomotion and manipulation capabilities while explicitly addressing critical safety constraints, including collision avoidance, dynamic stability, and power efficiency, in order to ensure robust performance under lunar-specific conditions, such as reduced gravity and irregular terrain. Experimental results demonstrate the framework's effectiveness in achieving precise 6D task-space end-effector pose tracking, achieving an average positional accuracy of 4 cm and orientation accuracy of 8.1 degrees. The system consistently respects both soft and hard constraints, exhibiting adaptive behaviors optimized for lunar gravity conditions. This work effectively bridges adaptive learning with essential mission-critical safety requirements, paving the way for advanced autonomous robotic explorers for future lunar missions.
UKDM: Underwater keypoint detection and matching using underwater image enhancement techniques
Apr 15, 2025The purpose of this paper is to explore the use of underwater image enhancement techniques to improve keypoint detection and matching. By applying advanced deep learning models, including generative adversarial networks and convolutional neural networks, we aim to find the best method which improves the accuracy of keypoint detection and the robustness of matching algorithms. We evaluate the performance of these techniques on various underwater datasets, demonstrating significant improvements over traditional methods.
CADDI: An in-Class Activity Detection Dataset using IMU data from low-cost sensors
Mar 04, 2025The monitoring and prediction of in-class student activities is of paramount importance for the comprehension of engagement and the enhancement of pedagogical efficacy. The accurate detection of these activities enables educators to modify their lessons in real time, thereby reducing negative emotional states and enhancing the overall learning experience. To this end, the use of non-intrusive devices, such as inertial measurement units (IMUs) embedded in smartwatches, represents a viable solution. The development of reliable predictive systems has been limited by the lack of large, labeled datasets in education. To bridge this gap, we present a novel dataset for in-class activity detection using affordable IMU sensors. The dataset comprises 19 diverse activities, both instantaneous and continuous, performed by 12 participants in typical classroom scenarios. It includes accelerometer, gyroscope, rotation vector data, and synchronized stereo images, offering a comprehensive resource for developing multimodal algorithms using sensor and visual data. This dataset represents a key step toward scalable solutions for activity recognition in educational settings.
DIPSER: A Dataset for In-Person Student1 Engagement Recognition in the Wild
Feb 27, 2025In this paper, a novel dataset is introduced, designed to assess student attention within in-person classroom settings. This dataset encompasses RGB camera data, featuring multiple cameras per student to capture both posture and facial expressions, in addition to smartwatch sensor data for each individual. This dataset allows machine learning algorithms to be trained to predict attention and correlate it with emotion. A comprehensive suite of attention and emotion labels for each student is provided, generated through self-reporting as well as evaluations by four different experts. Our dataset uniquely combines facial and environmental camera data, smartwatch metrics, and includes underrepresented ethnicities in similar datasets, all within in-the-wild, in-person settings, making it the most comprehensive dataset of its kind currently available. The dataset presented offers an extensive and diverse collection of data pertaining to student interactions across different educational contexts, augmented with additional metadata from other tools. This initiative addresses existing deficiencies by offering a valuable resource for the analysis of student attention and emotion in face-to-face lessons.
Escaping The Big Data Paradigm in Self-Supervised Representation Learning
Feb 25, 2025The reliance on large-scale datasets and extensive computational resources has become a major barrier to advancing representation learning in vision, especially in data-scarce domains. In this paper, we address the critical question: Can we escape the big data paradigm in self-supervised representation learning from images? We introduce SCOTT (Sparse Convolutional Tokenizer for Transformers), a shallow tokenization architecture that is compatible with Masked Image Modeling (MIM) tasks. SCOTT injects convolutional inductive biases into Vision Transformers (ViTs), enhancing their efficacy in small-scale data regimes. Alongside, we propose to train on a Joint-Embedding Predictive Architecture within a MIM framework (MIM-JEPA), operating in latent representation space to capture more semantic features. Our approach enables ViTs to be trained from scratch on datasets orders of magnitude smaller than traditionally required --without relying on massive external datasets for pretraining. We validate our method on three small-size, standard-resoultion, fine-grained datasets: Oxford Flowers-102, Oxford IIIT Pets-37, and ImageNet-100. Despite the challenges of limited data and high intra-class similarity, frozen SCOTT models pretrained with MIM-JEPA significantly outperform fully supervised methods and achieve competitive results with SOTA approaches that rely on large-scale pretraining, complex image augmentations and bigger model sizes. By demonstrating that robust off-the-shelf representations can be learned with limited data, compute, and model sizes, our work paves the way for computer applications in resource constrained environments such as medical imaging or robotics. Our findings challenge the prevailing notion that vast amounts of data are indispensable for effective representation learning in vision, offering a new pathway toward more accessible and inclusive advancements in the field.
CHIRLA: Comprehensive High-resolution Identification and Re-identification for Large-scale Analysis
Feb 10, 2025Person re-identification (Re-ID) is a key challenge in computer vision, requiring the matching of individuals across different cameras, locations, and time periods. While most research focuses on short-term scenarios with minimal appearance changes, real-world applications demand robust Re-ID systems capable of handling long-term scenarios, where persons' appearances can change significantly due to variations in clothing and physical characteristics. In this paper, we present CHIRLA, Comprehensive High-resolution Identification and Re-identification for Large-scale Analysis, a novel dataset specifically designed for long-term person Re-ID. CHIRLA consists of recordings from strategically placed cameras over a seven-month period, capturing significant variations in both temporal and appearance attributes, including controlled changes in participants' clothing and physical features. The dataset includes 22 individuals, four connected indoor environments, and seven cameras. We collected more than five hours of video that we semi-automatically labeled to generate around one million bounding boxes with identity annotations. By introducing this comprehensive benchmark, we aim to facilitate the development and evaluation of Re-ID algorithms that can reliably perform in challenging, long-term real-world scenarios.