 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Artificial Intelligence-based Assistant for the Visually Impaired
Nov 11, 2025


This paper describes an artificial intelligence-based assistant application, AIDEN, developed during 2023 and 2024, aimed at improving the quality of life for visually impaired individuals. Visually impaired individuals face challenges in identifying objects, reading text, and navigating unfamiliar environments, which can limit their independence and reduce their quality of life. Although solutions such as Braille, audio books, and screen readers exist, they may not be effective in all situations. This application leverages state-of-the-art machine learning algorithms to identify and describe objects, read text, and answer questions about the environment. Specifically, it uses You Only Look Once architectures and a Large Language and Vision Assistant. The system incorporates several methods to facilitate the user's interaction with the system and access to textual and visual information in an appropriate manner. AIDEN aims to enhance user autonomy and access to information, contributing to an improved perception of daily usability, as supported by user feedback.
Video Perception Models for 3D Scene Synthesis
Jun 25, 2025



Traditionally, 3D scene synthesis requires expert knowledge and significant manual effort. Automating this process could greatly benefit fields such as architectural design, robotics simulation, virtual reality, and gaming. Recent approaches to 3D scene synthesis often rely on the commonsense reasoning of large language models (LLMs) or strong visual priors of modern image generation models. However, current LLMs demonstrate limited 3D spatial reasoning ability, which restricts their ability to generate realistic and coherent 3D scenes. Meanwhile, image generation-based methods often suffer from constraints in viewpoint selection and multi-view inconsistencies. In this work, we present Video Perception models for 3D Scene synthesis (VIPScene), a novel framework that exploits the encoded commonsense knowledge of the 3D physical world in video generation models to ensure coherent scene layouts and consistent object placements across views. VIPScene accepts both text and image prompts and seamlessly integrates video generation, feedforward 3D reconstruction, and open-vocabulary perception models to semantically and geometrically analyze each object in a scene. This enables flexible scene synthesis with high realism and structural consistency. For more precise analysis, we further introduce First-Person View Score (FPVScore) for coherence and plausibility evaluation, utilizing continuous first-person perspective to capitalize on the reasoning ability of multimodal large language models. Extensive experiments show that VIPScene significantly outperforms existing methods and generalizes well across diverse scenarios. The code will be released.
Spot-On: A Mixed Reality Interface for Multi-Robot Cooperation
May 28, 2025

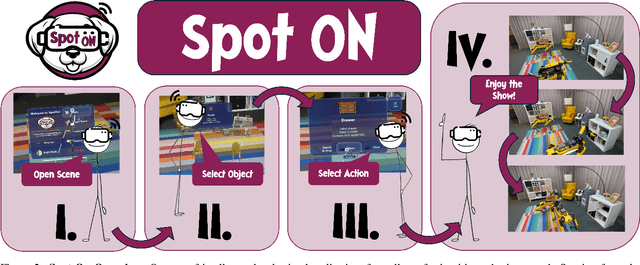

Recent progress in mixed reality (MR) and robotics is enabling increasingly sophisticated forms of human-robot collaboration. Building on these developments, we introduce a novel MR framework that allows multiple quadruped robots to operate in semantically diverse environments via a MR interface. Our system supports collaborative tasks involving drawers, swing doors, and higher-level infrastructure such as light switches. A comprehensive user study verifies both the design and usability of our app, with participants giving a "good" or "very good" rating in almost all cases. Overall, our approach provides an effective and intuitive framework for MR-based multi-robot collaboration in complex, real-world scenarios.
Lost & Found: Updating Dynamic 3D Scene Graphs from Egocentric Observations
Nov 28, 2024



Recent approaches have successfully focused on the segmentation of static reconstructions, thereby equipping downstream applications with semantic 3D understanding. However, the world in which we live is dynamic, characterized by numerous interactions between the environment and humans or robotic agents. Static semantic maps are unable to capture this information, and the naive solution of rescanning the environment after every change is both costly and ineffective in tracking e.g. objects being stored away in drawers. With Lost & Found we present an approach that addresses this limitation. Based solely on egocentric recordings with corresponding hand position and camera pose estimates, we are able to track the 6DoF poses of the moving object within the detected interaction interval. These changes are applied online to a transformable scene graph that captures object-level relations. Compared to state-of-the-art object pose trackers, our approach is more reliable in handling the challenging egocentric viewpoint and the lack of depth information. It outperforms the second-best approach by 34% and 56% for translational and orientational error, respectively, and produces visibly smoother 6DoF object trajectories. In addition, we illustrate how the acquired interaction information in the dynamic scene graph can be employed in the context of robotic applications that would otherwise be unfeasible: We show how our method allows to command a mobile manipulator through teach & repeat, and how information about prior interaction allows a mobile manipulator to retrieve an object hidden in a drawer. Code, videos and corresponding data are accessible at https://behretj.github.io/LostAndFound.
HoloSpot: Intuitive Object Manipulation via Mixed Reality Drag-and-Drop
Oct 14, 2024Human-robot interaction through mixed reality (MR) technologies enables novel, intuitive interfaces to control robots in remote operations. Such interfaces facilitate operations in hazardous environments, where human presence is risky, yet human oversight remains crucial. Potential environments include disaster response scenarios and areas with high radiation or toxic chemicals. In this paper we present an interface system projecting a 3D representation of a scanned room as a scaled-down 'dollhouse' hologram, allowing users to select and manipulate objects using a straightforward drag-and-drop interface. We then translate these drag-and-drop user commands into real-time robot actions based on the recent Spot-Compose framework. The Unity-based application provides an interactive tutorial and a user-friendly experience, ensuring ease of use. Through comprehensive end-to-end testing, we validate the system's capability in executing pick-and-place tasks and a complementary user study affirms the interface's intuitive controls. Our findings highlight the advantages of this interface in improving user experience and operational efficiency. This work lays the groundwork for a robust framework that advances the potential for seamless human-robot collaboration in diverse applications. Paper website: https://holospot.github.io/
SpotLight: Robotic Scene Understanding through Interaction and Affordance Detection
Sep 18, 2024Despite increasing research efforts on household robotics, robots intended for deployment in domestic settings still struggle with more complex tasks such as interacting with functional elements like drawers or light switches, largely due to limited task-specific understanding and interaction capabilities. These tasks require not only detection and pose estimation but also an understanding of the affordances these elements provide. To address these challenges and enhance robotic scene understanding, we introduce SpotLight: A comprehensive framework for robotic interaction with functional elements, specifically light switches. Furthermore, this framework enables robots to improve their environmental understanding through interaction. Leveraging VLM-based affordance prediction to estimate motion primitives for light switch interaction, we achieve up to 84% operation success in real world experiments. We further introduce a specialized dataset containing 715 images as well as a custom detection model for light switch detection. We demonstrate how the framework can facilitate robot learning through physical interaction by having the robot explore the environment and discover previously unknown relationships in a scene graph representation. Lastly, we propose an extension to the framework to accommodate other functional interactions such as swing doors, showcasing its flexibility. Videos and Code: timengelbracht.github.io/SpotLight/
MaRINeR: Enhancing Novel Views by Matching Rendered Images with Nearby References
Jul 18, 2024



Rendering realistic images from 3D reconstruction is an essential task of many Computer Vision and Robotics pipelines, notably for mixed-reality applications as well as training autonomous agents in simulated environments. However, the quality of novel views heavily depends of the source reconstruction which is often imperfect due to noisy or missing geometry and appearance. Inspired by the recent success of reference-based super-resolution networks, we propose MaRINeR, a refinement method that leverages information of a nearby mapping image to improve the rendering of a target viewpoint. We first establish matches between the raw rendered image of the scene geometry from the target viewpoint and the nearby reference based on deep features, followed by hierarchical detail transfer. We show improved renderings in quantitative metrics and qualitative examples from both explicit and implicit scene representations. We further employ our method on the downstream tasks of pseudo-ground-truth validation, synthetic data enhancement and detail recovery for renderings of reduced 3D reconstructions.
Spot-Compose: A Framework for Open-Vocabulary Object Retrieval and Drawer Manipulation in Point Clouds
Apr 18, 2024In recent years, modern techniques in deep learning and large-scale datasets have led to impressive progress in 3D instance segmentation, grasp pose estimation, and robotics. This allows for accurate detection directly in 3D scenes, object- and environment-aware grasp prediction, as well as robust and repeatable robotic manipulation. This work aims to integrate these recent methods into a comprehensive framework for robotic interaction and manipulation in human-centric environments. Specifically, we leverage 3D reconstructions from a commodity 3D scanner for open-vocabulary instance segmentation, alongside grasp pose estimation, to demonstrate dynamic picking of objects, and opening of drawers. We show the performance and robustness of our model in two sets of real-world experiments including dynamic object retrieval and drawer opening, reporting a 51% and 82% success rate respectively. Code of our framework as well as videos are available on: https://spot-compose.github.io/.
NeRFmentation: NeRF-based Augmentation for Monocular Depth Estimation
Jan 08, 2024The capabilities of monocular depth estimation (MDE) models are limited by the availability of sufficient and diverse datasets. In the case of MDE models for autonomous driving, this issue is exacerbated by the linearity of the captured data trajectories. We propose a NeRF-based data augmentation pipeline to introduce synthetic data with more diverse viewing directions into training datasets and demonstrate the benefits of our approach to model performance and robustness. Our data augmentation pipeline, which we call "NeRFmentation", trains NeRFs on each scene in the dataset, filters out subpar NeRFs based on relevant metrics, and uses them to generate synthetic RGB-D images captured from new viewing directions. In this work, we apply our technique in conjunction with three state-of-the-art MDE architectures on the popular autonomous driving dataset KITTI, augmenting its training set of the Eigen split. We evaluate the resulting performance gain on the original test set, a separate popular driving set, and our own synthetic test set.
NVS-MonoDepth: Improving Monocular Depth Prediction with Novel View Synthesis
Dec 22, 2021
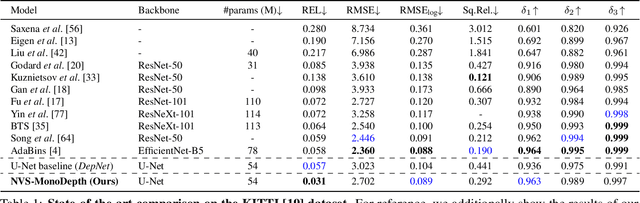
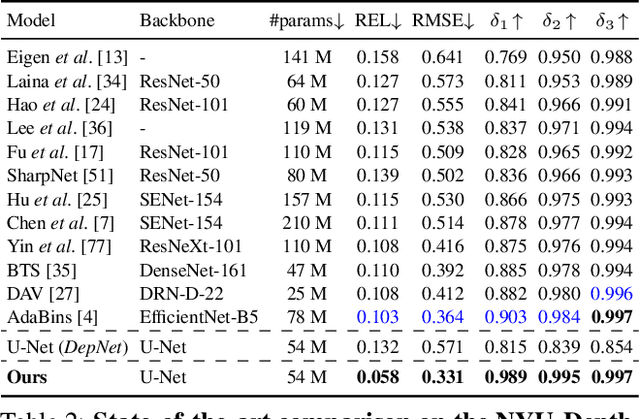
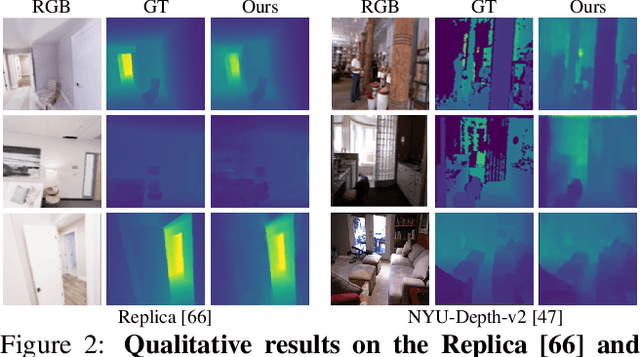
Building upon the recent progress in novel view synthesis, we propose its application to improve monocular depth estimation. In particular, we propose a novel training method split in three main steps. First, the prediction results of a monocular depth network are warped to an additional view point. Second, we apply an additional image synthesis network, which corrects and improves the quality of the warped RGB image. The output of this network is required to look as similar as possible to the ground-truth view by minimizing the pixel-wise RGB reconstruction error. Third, we reapply the same monocular depth estimation onto the synthesized second view point and ensure that the depth predictions are consistent with the associated ground truth depth. Experimental results prove that our method achieves state-of-the-art or comparable performance on the KITTI and NYU-Depth-v2 datasets with a lightweight and simple vanilla U-Net architecture.
* 8 pages (main paper), 9 pages (supplementary material), 14 figures, 4 tables