 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYMBOLIZER: Symbolic Model-free Task Planning with VLMs
Apr 20, 2026Traditional Task and Motion Planning (TAMP) systems depend on physics models for motion planning and discrete symbolic models for task planning. Although physics model are often available, symbolic models (consisting of symbolic state interpretation and action models) must be meticulously handcrafted or learned from labeled data. This process is both resource-intensive and constrains the solution to the specific domain, limiting scalability and adaptability. On the other hand, Visual Language Models (VLMs) show desirable zero-shot visual understanding (due to their extensive training on heterogeneous data), but still achieve limited planning capabilities. Therefore, integrating VLMs with classical planning for long-horizon reasoning in TAMP problems offers high potential. Recent works in this direction still lack generality and depend on handcrafted, task-specific solutions, e.g. describing all possible objects in advance, or using symbolic action models. We propose a framework that generalizes well to unseen problem instances. The method requires only lifted predicates describing relations among objects and uses VLMs to ground them from images to obtain the symbolic state. Planning is performed with domain-independent heuristic search using goal-count and width-based heuristics, without need for action models. Symbolic search over VLM-grounded state-space outperforms direct VLM-based planning and performs on par with approaches that use a VLM-derived heuristic. This shows that domain-independent search can effectively solve problems across domains with large combinatorial state spaces. We extensively evaluate on extensively evaluate our method and achieve state-of-the-art results on the ProDG and ViPlan benchmarks.
FunFact: Building Probabilistic Functional 3D Scene Graphs via Factor-Graph Reasoning
Apr 04, 2026Recent work in 3D scene understanding is moving beyond purely spatial analysis toward functional scene understanding. However, existing methods often consider functional relationships between object pairs in isolation, failing to capture the scene-wide interdependence that humans use to resolve ambiguity. We introduce FunFact, a framework for constructing probabilistic open-vocabulary functional 3D scene graphs from posed RGB-D images. FunFact first builds an object- and part-centric 3D map and uses foundation models to propose semantically plausible functional relations. These candidates are converted into factor graph variables and constrained by both LLM-derived common-sense priors and geometric priors. This formulation enables joint probabilistic inference over all functional edges and their marginals, yielding substantially better calibrated confidence scores. To benchmark this setting, we introduce FunThor, a synthetic dataset based on AI2-THOR with part-level geometry and rule-based functional annotations. Experiments on SceneFun3D, FunGraph3D, and FunThor show that FunFact improves node and relation discovery recall and significantly reduces calibration error for ambiguous relations, highlighting the benefits of holistic probabilistic modeling for functional scene understanding. See our project page at https://funfact-scenegraph.github.io/
OpenFrontier: General Navigation with Visual-Language Grounded Frontiers
Mar 05, 2026Open-world navigation requires robots to make decisions in complex everyday environments while adapting to flexible task requirements. Conventional navigation approaches often rely on dense 3D reconstruction and hand-crafted goal metrics, which limits their generalization across tasks and environments. Recent advances in vision--language navigation (VLN) and vision--language--action (VLA) models enable end-to-end policies conditioned on natural language, but typically require interactive training, large-scale data collection, or task-specific fine-tuning with a mobile agent. We formulate navigation as a sparse subgoal identification and reaching problem and observe that providing visual anchoring targets for high-level semantic priors enables highly efficient goal-conditioned navigation. Based on this insight, we select navigation frontiers as semantic anchors and propose OpenFrontier, a training-free navigation framework that seamlessly integrates diverse vision--language prior models. OpenFrontier enables efficient navigation with a lightweight system design, without dense 3D mapping, policy training, or model fine-tuning. We evaluate OpenFrontier across multiple navigation benchmarks and demonstrate strong zero-shot performance, as well as effective real-world deployment on a mobile robot.
Articulated 3D Scene Graphs for Open-World Mobile Manipulation
Feb 18, 2026Semantics has enabled 3D scene understanding and affordance-driven object interaction. However, robots operating in real-world environments face a critical limitation: they cannot anticipate how objects move. Long-horizon mobile manipulation requires closing the gap between semantics, geometry, and kinematics. In this work, we present MoMa-SG, a novel framework for building semantic-kinematic 3D scene graphs of articulated scenes containing a myriad of interactable objects. Given RGB-D sequences containing multiple object articulations, we temporally segment object interactions and infer object motion using occlusion-robust point tracking. We then lift point trajectories into 3D and estimate articulation models using a novel unified twist estimation formulation that robustly estimates revolute and prismatic joint parameters in a single optimization pass. Next, we associate objects with estimated articulations and detect contained objects by reasoning over parent-child relations at identified opening states. We also introduce the novel Arti4D-Semantic dataset, which uniquely combines hierarchical object semantics including parent-child relation labels with object axis annotations across 62 in-the-wild RGB-D sequences containing 600 object interactions and three distinct observation paradigms. We extensively evaluate the performance of MoMa-SG on two datasets and ablate key design choices of our approach. In addition, real-world experiments on both a quadruped and a mobile manipulator demonstrate that our semantic-kinematic scene graphs enable robust manipulation of articulated objects in everyday home environments. We provide code and data at: https://momasg.cs.uni-freiburg.de.
ActLoc: Learning to Localize on the Move via Active Viewpoint Selection
Aug 28, 2025Reliable localization is critical for robot navigation, yet most existing systems implicitly assume that all viewing directions at a location are equally informative. In practice, localization becomes unreliable when the robot observes unmapped, ambiguous, or uninformative regions. To address this, we present ActLoc, an active viewpoint-aware planning framework for enhancing localization accuracy for general robot navigation tasks. At its core, ActLoc employs a largescale trained attention-based model for viewpoint selection. The model encodes a metric map and the camera poses used during map construction, and predicts localization accuracy across yaw and pitch directions at arbitrary 3D locations. These per-point accuracy distributions are incorporated into a path planner, enabling the robot to actively select camera orientations that maximize localization robustness while respecting task and motion constraints. ActLoc achieves stateof-the-art results on single-viewpoint selection and generalizes effectively to fulltrajectory planning. Its modular design makes it readily applicable to diverse robot navigation and inspection tasks.
Spot-On: A Mixed Reality Interface for Multi-Robot Cooperation
May 28, 2025

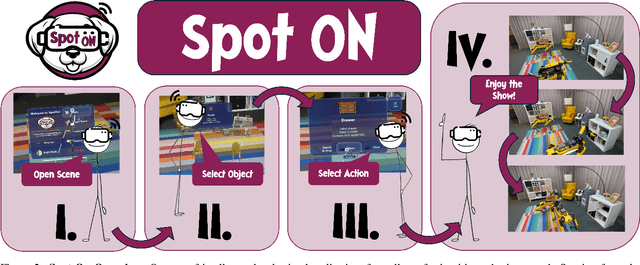

Recent progress in mixed reality (MR) and robotics is enabling increasingly sophisticated forms of human-robot collaboration. Building on these developments, we introduce a novel MR framework that allows multiple quadruped robots to operate in semantically diverse environments via a MR interface. Our system supports collaborative tasks involving drawers, swing doors, and higher-level infrastructure such as light switches. A comprehensive user study verifies both the design and usability of our app, with participants giving a "good" or "very good" rating in almost all cases. Overall, our approach provides an effective and intuitive framework for MR-based multi-robot collaboration in complex, real-world scenarios.
Loop Closure from Two Views: Revisiting PGO for Scalable Trajectory Estimation through Monocular Priors
Mar 20, 2025



(Visual) Simultaneous Localization and Mapping (SLAM) remains a fundamental challenge in enabling autonomous systems to navigate and understand large-scale environments. Traditional SLAM approaches struggle to balance efficiency and accuracy, particularly in large-scale settings where extensive computational resources are required for scene reconstruction and Bundle Adjustment (BA). However, this scene reconstruction, in the form of sparse pointclouds of visual landmarks, is often only used within the SLAM system because navigation and planning methods require different map representations. In this work, we therefore investigate a more scalable Visual SLAM (VSLAM) approach without reconstruction, mainly based on approaches for two-view loop closures. By restricting the map to a sparse keyframed pose graph without dense geometry representations, our '2GO' system achieves efficient optimization with competitive absolute trajectory accuracy. In particular, we find that recent advancements in image matching and monocular depth priors enable very accurate trajectory optimization from two-view edges. We conduct extensive experiments on diverse datasets, including large-scale scenarios, and provide a detailed analysis of the trade-offs between runtime, accuracy, and map size. Our results demonstrate that this streamlined approach supports real-time performance, scales well in map size and trajectory duration, and effectively broadens the capabilities of VSLAM for long-duration deployments to large environments.
FunGraph: Functionality Aware 3D Scene Graphs for Language-Prompted Scene Interaction
Mar 10, 2025The concept of 3D scene graphs is increasingly recognized as a powerful semantic and hierarchical representation of the environment. Current approaches often address this at a coarse, object-level resolution. In contrast, our goal is to develop a representation that enables robots to directly interact with their environment by identifying both the location of functional interactive elements and how these can be used. To achieve this, we focus on detecting and storing objects at a finer resolution, focusing on affordance-relevant parts. The primary challenge lies in the scarcity of data that extends beyond instance-level detection and the inherent difficulty of capturing detailed object features using robotic sensors. We leverage currently available 3D resources to generate 2D data and train a detector, which is then used to augment the standard 3D scene graph generation pipeline. Through our experiments, we demonstrate that our approach achieves functional element segmentation comparable to state-of-the-art 3D models and that our augmentation enables task-driven affordance grounding with higher accuracy than the current solutions.
FrontierNet: Learning Visual Cues to Explore
Jan 08, 2025



Exploration of unknown environments is crucial for autonomous robots; it allows them to actively reason and decide on what new data to acquire for tasks such as mapping, object discovery, and environmental assessment. Existing methods, such as frontier-based methods, rely heavily on 3D map operations, which are limited by map quality and often overlook valuable context from visual cues. This work aims at leveraging 2D visual cues for efficient autonomous exploration, addressing the limitations of extracting goal poses from a 3D map. We propose a image-only frontier-based exploration system, with FrontierNet as a core component developed in this work. FrontierNet is a learning-based model that (i) detects frontiers, and (ii) predicts their information gain, from posed RGB images enhanced by monocular depth priors. Our approach provides an alternative to existing 3D-dependent exploration systems, achieving a 16% improvement in early-stage exploration efficiency, as validated through extensive simulations and real-world experiments.
Lost & Found: Updating Dynamic 3D Scene Graphs from Egocentric Observations
Nov 28, 2024



Recent approaches have successfully focused on the segmentation of static reconstructions, thereby equipping downstream applications with semantic 3D understanding. However, the world in which we live is dynamic, characterized by numerous interactions between the environment and humans or robotic agents. Static semantic maps are unable to capture this information, and the naive solution of rescanning the environment after every change is both costly and ineffective in tracking e.g. objects being stored away in drawers. With Lost & Found we present an approach that addresses this limitation. Based solely on egocentric recordings with corresponding hand position and camera pose estimates, we are able to track the 6DoF poses of the moving object within the detected interaction interval. These changes are applied online to a transformable scene graph that captures object-level relations. Compared to state-of-the-art object pose trackers, our approach is more reliable in handling the challenging egocentric viewpoint and the lack of depth information. It outperforms the second-best approach by 34% and 56% for translational and orientational error, respectively, and produces visibly smoother 6DoF object trajectories. In addition, we illustrate how the acquired interaction information in the dynamic scene graph can be employed in the context of robotic applications that would otherwise be unfeasible: We show how our method allows to command a mobile manipulator through teach & repeat, and how information about prior interaction allows a mobile manipulator to retrieve an object hidden in a drawer. Code, videos and corresponding data are accessible at https://behretj.github.io/LostAndFound.