 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARKit LabelMaker: A New Scale for Indoor 3D Scene Understanding
Paper and Code
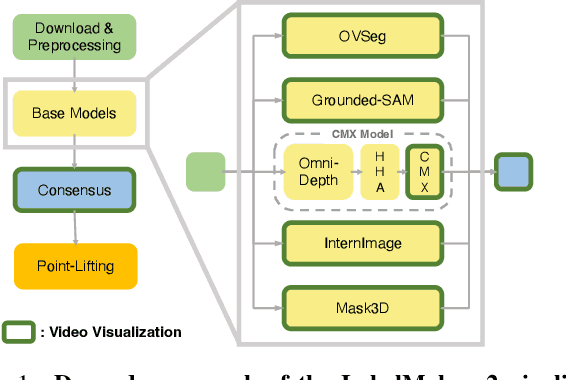
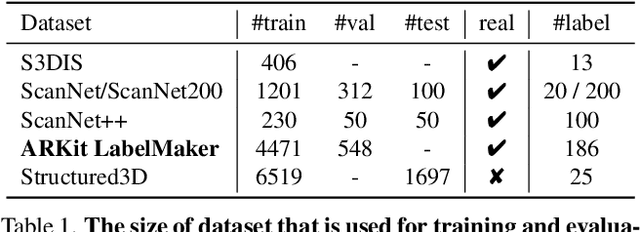


The performance of neural networks scales with both their size and the amount of data they have been trained on. This is shown in both language and image generation. However, this requires scaling-friendly network architectures as well as large-scale datasets. Even though scaling-friendly architectures like transformers have emerged for 3D vision tasks, the GPT-moment of 3D vision remains distant due to the lack of training data. In this paper, we introduce ARKit LabelMaker, the first large-scale, real-world 3D dataset with dense semantic annotations. Specifically, we complement ARKitScenes dataset with dense semantic annotations that are automatically generated at scale. To this end, we extend LabelMaker, a recent automatic annotation pipeline, to serve the needs of large-scale pre-training. This involves extending the pipeline with cutting-edge segmentation models as well as making it robust to the challenges of large-scale processing. Further, we push forward the state-of-the-art performance on ScanNet and ScanNet200 dataset with prevalent 3D semantic segmentation models, demonstrating the efficacy of our generated dataset.