 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymTRELLIS: Symmetry-Enforced Voxel Latents for 3D Generation
Jun 02, 2026Single-view 3D generative models have achieved impressive visual quality, yet they are not designed to satisfy structural or functional requirements, and in practice, often fall short. Symmetry is one such requirement: violations, even subtle ones, on symmetry can render a model physically unusable. We present SymTRELLIS, a method that enforces arbitrary finite point group symmetries (rotational, reflectional, and polyhedral) during the flow-based 3D generation of TRELLIS.2, without retraining the underlying VAE or flow model. Our key idea is to approximate the latent-space action of spatial transformations as a learned linear operator on voxel latents, implemented as a lightweight spatial-transform latent mapper trained on generic, non-symmetric 3D data. At generation time, we enforce symmetry by averaging predicted flow velocities across all symmetry-equivalent transformations at each ODE step, a process we call velocity symmetrization. The symmetry specification can be estimated automatically from an initial TRELLIS.2 generation or supplied by the user, enabling deliberate fold manipulation beyond what the input image suggests. On a curated benchmark of 266 strictly symmetric objects spanning 2- to 20-fold rotations and polyhedral symmetry groups, SymTRELLIS substantially reduces all symmetry error metrics compared to TRELLIS.2, Hunyuan3D-2.1, and TripoSG, while maintaining reconstruction accuracy comparable to the base model.
Advances in 4D Representation: Geometry, Motion, and Interaction
Oct 22, 2025We present a survey on 4D generation and reconstruction, a fast-evolving subfield of computer graphics whose developments have been propelled by recent advances in neural fields, geometric and motion deep learning, as well 3D generative artificial intelligence (GenAI). While our survey is not the first of its kind, we build our coverage of the domain from a unique and distinctive perspective of 4D representations\/}, to model 3D geometry evolving over time while exhibiting motion and interaction. Specifically, instead of offering an exhaustive enumeration of many works, we take a more selective approach by focusing on representative works to highlight both the desirable properties and ensuing challenges of each representation under different computation, application, and data scenarios. The main take-away message we aim to convey to the readers is on how to select and then customize the appropriate 4D representations for their tasks. Organizationally, we separate the 4D representations based on three key pillars: geometry, motion, and interaction. Our discourse will not only encompass the most popular representations of today, such as neural radiance fields (NeRFs) and 3D Gaussian Splatting (3DGS), but also bring attention to relatively under-explored representations in the 4D context, such as structured models and long-range motions. Throughout our survey, we will reprise the role of large language models (LLMs) and video foundational models (VFMs) in a variety of 4D applications, while steering our discussion towards their current limitations and how they can be addressed. We also provide a dedicated coverage on what 4D datasets are currently available, as well as what is lacking, in driving the subfield forward. Project page:https://mingrui-zhao.github.io/4DRep-GMI/
ARKit LabelMaker: A New Scale for Indoor 3D Scene Understanding
Oct 17, 2024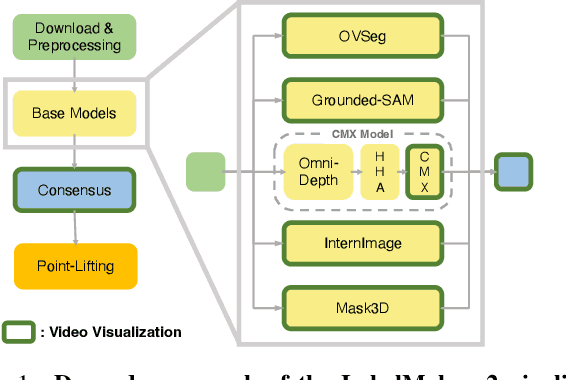
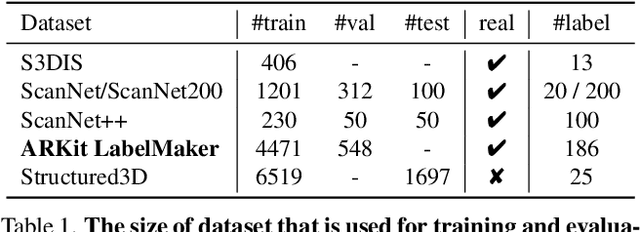


The performance of neural networks scales with both their size and the amount of data they have been trained on. This is shown in both language and image generation. However, this requires scaling-friendly network architectures as well as large-scale datasets. Even though scaling-friendly architectures like transformers have emerged for 3D vision tasks, the GPT-moment of 3D vision remains distant due to the lack of training data. In this paper, we introduce ARKit LabelMaker, the first large-scale, real-world 3D dataset with dense semantic annotations. Specifically, we complement ARKitScenes dataset with dense semantic annotations that are automatically generated at scale. To this end, we extend LabelMaker, a recent automatic annotation pipeline, to serve the needs of large-scale pre-training. This involves extending the pipeline with cutting-edge segmentation models as well as making it robust to the challenges of large-scale processing. Further, we push forward the state-of-the-art performance on ScanNet and ScanNet200 dataset with prevalent 3D semantic segmentation models, demonstrating the efficacy of our generated dataset.
Knowledge Distillation in Wide Neural Networks: Risk Bound, Data Efficiency and Imperfect Teacher
Oct 20, 2020



Knowledge distillation is a strategy of training a student network with guide of the soft output from a teacher network. It has been a successful method of model compression and knowledge transfer. However, currently knowledge distillation lacks a convincing theoretical understanding. On the other hand, recent finding on neural tangent kernel enables us to approximate a wide neural network with a linear model of the network's random features. In this paper, we theoretically analyze the knowledge distillation of a wide neural network. First we provide a transfer risk bound for the linearized model of the network. Then we propose a metric of the task's training difficulty, called data inefficiency. Based on this metric, we show that for a perfect teacher, a high ratio of teacher's soft labels can be beneficial. Finally, for the case of imperfect teacher, we find that hard labels can correct teacher's wrong prediction, which explains the practice of mixing hard and soft labels.