 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARKit LabelMaker: A New Scale for Indoor 3D Scene Understanding
Oct 17, 2024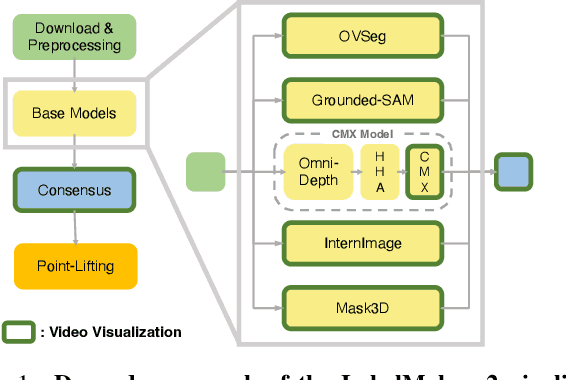
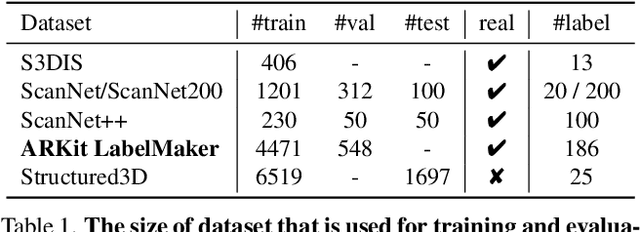


The performance of neural networks scales with both their size and the amount of data they have been trained on. This is shown in both language and image generation. However, this requires scaling-friendly network architectures as well as large-scale datasets. Even though scaling-friendly architectures like transformers have emerged for 3D vision tasks, the GPT-moment of 3D vision remains distant due to the lack of training data. In this paper, we introduce ARKit LabelMaker, the first large-scale, real-world 3D dataset with dense semantic annotations. Specifically, we complement ARKitScenes dataset with dense semantic annotations that are automatically generated at scale. To this end, we extend LabelMaker, a recent automatic annotation pipeline, to serve the needs of large-scale pre-training. This involves extending the pipeline with cutting-edge segmentation models as well as making it robust to the challenges of large-scale processing. Further, we push forward the state-of-the-art performance on ScanNet and ScanNet200 dataset with prevalent 3D semantic segmentation models, demonstrating the efficacy of our generated dataset.
ALSTER: A Local Spatio-Temporal Expert for Online 3D Semantic Reconstruction
Dec 03, 2023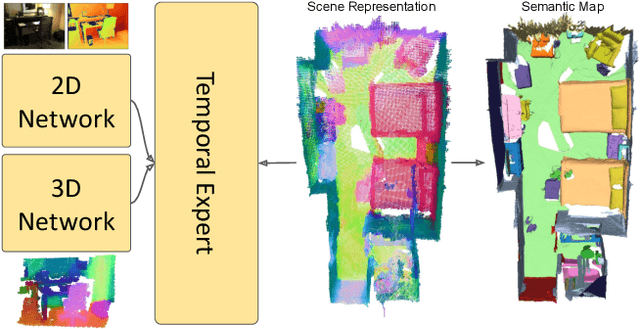
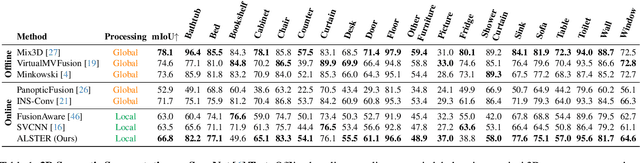
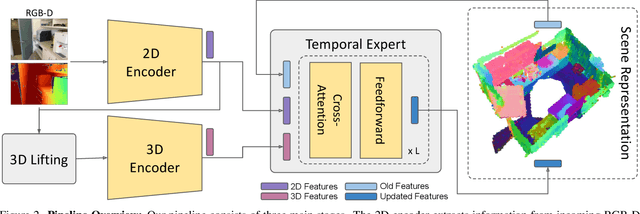
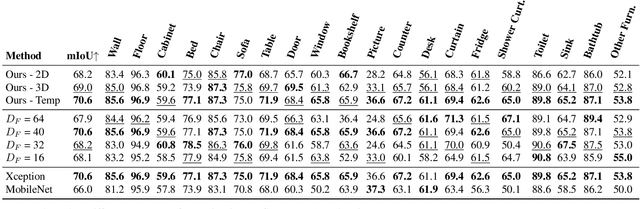
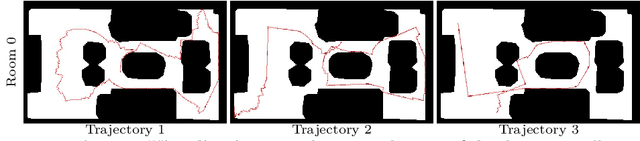
We propose an online 3D semantic segmentation method that incrementally reconstructs a 3D semantic map from a stream of RGB-D frames. Unlike offline methods, ours is directly applicable to scenarios with real-time constraints, such as robotics or mixed reality. To overcome the inherent challenges of online methods, we make two main contributions. First, to effectively extract information from the input RGB-D video stream, we jointly estimate geometry and semantic labels per frame in 3D. A key focus of our approach is to reason about semantic entities both in the 2D input and the local 3D domain to leverage differences in spatial context and network architectures. Our method predicts 2D features using an off-the-shelf segmentation network. The extracted 2D features are refined by a lightweight 3D network to enable reasoning about the local 3D structure. Second, to efficiently deal with an infinite stream of input RGB-D frames, a subsequent network serves as a temporal expert predicting the incremental scene updates by leveraging 2D, 3D, and past information in a learned manner. These updates are then integrated into a global scene representation. Using these main contributions, our method can enable scenarios with real-time constraints and can scale to arbitrary scene sizes by processing and updating the scene only in a local region defined by the new measurement. Our experiments demonstrate improved results compared to existing online methods that purely operate in local regions and show that complementary sources of information can boost the performance. We provide a thorough ablation study on the benefits of different architectural as well as algorithmic design decisions. Our method yields competitive results on the popular ScanNet benchmark and SceneNN dataset.
LABELMAKER: Automatic Semantic Label Generation from RGB-D Trajectories
Nov 20, 2023Semantic annotations are indispensable to train or evaluate perception models, yet very costly to acquire. This work introduces a fully automated 2D/3D labeling framework that, without any human intervention, can generate labels for RGB-D scans at equal (or better) level of accuracy than comparable manually annotated datasets such as ScanNet. Our approach is based on an ensemble of state-of-the-art segmentation models and 3D lifting through neural rendering. We demonstrate the effectiveness of our LabelMaker pipeline by generating significantly better labels for the ScanNet datasets and automatically labelling the previously unlabeled ARKitScenes dataset. Code and models are available at https://labelmaker.org
Removing Objects From Neural Radiance Fields
Dec 22, 2022Neural Radiance Fields (NeRFs) are emerging as a ubiquitous scene representation that allows for novel view synthesis. Increasingly, NeRFs will be shareable with other people. Before sharing a NeRF, though, it might be desirable to remove personal information or unsightly objects. Such removal is not easily achieved with the current NeRF editing frameworks. We propose a framework to remove objects from a NeRF representation created from an RGB-D sequence. Our NeRF inpainting method leverages recent work in 2D image inpainting and is guided by a user-provided mask. Our algorithm is underpinned by a confidence based view selection procedure. It chooses which of the individual 2D inpainted images to use in the creation of the NeRF, so that the resulting inpainted NeRF is 3D consistent. We show that our method for NeRF editing is effective for synthesizing plausible inpaintings in a multi-view coherent manner. We validate our approach using a new and still-challenging dataset for the task of NeRF inpainting.
Learning Online Multi-Sensor Depth Fusion
Apr 07, 2022

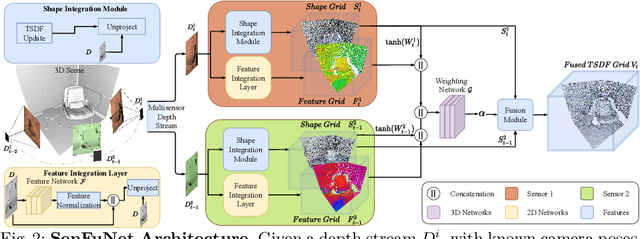
Many hand-held or mixed reality devices are used with a single sensor for 3D reconstruction, although they often comprise multiple sensors. Multi-sensor depth fusion is able to substantially improve the robustness and accuracy of 3D reconstruction methods, but existing techniques are not robust enough to handle sensors which operate with diverse value ranges as well as noise and outlier statistics. To this end, we introduce SenFuNet, a depth fusion approach that learns sensor-specific noise and outlier statistics and combines the data streams of depth frames from different sensors in an online fashion. Our method fuses multi-sensor depth streams regardless of time synchronization and calibration and generalizes well with little training data. We conduct experiments with various sensor combinations on the real-world CoRBS and Scene3D datasets, as well as the Replica dataset. Experiments demonstrate that our fusion strategy outperforms traditional and recent online depth fusion approaches. In addition, the combination of multiple sensors yields more robust outlier handling and precise surface reconstruction than the use of a single sensor.
DeepSurfels: Learning Online Appearance Fusion
Dec 28, 2020



We present DeepSurfels, a novel hybrid scene representation for geometry and appearance information. DeepSurfels combines explicit and neural building blocks to jointly encode geometry and appearance information. In contrast to established representations, DeepSurfels better represents high-frequency textures, is well-suited for online updates of appearance information, and can be easily combined with machine learning methods. We further present an end-to-end trainable online appearance fusion pipeline that fuses information provided by RGB images into the proposed scene representation and is trained using self-supervision imposed by the reprojection error with respect to the input images. Our method compares favorably to classical texture mapping approaches as well as recently proposed learning-based techniques. Moreover, we demonstrate lower runtime, improved generalization capabilities, and better scalability to larger scenes compared to existing methods.
NeuralFusion: Online Depth Fusion in Latent Space
Nov 30, 2020
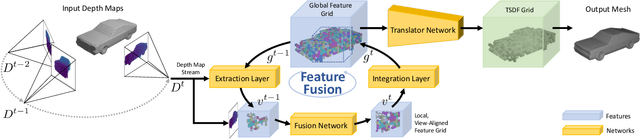
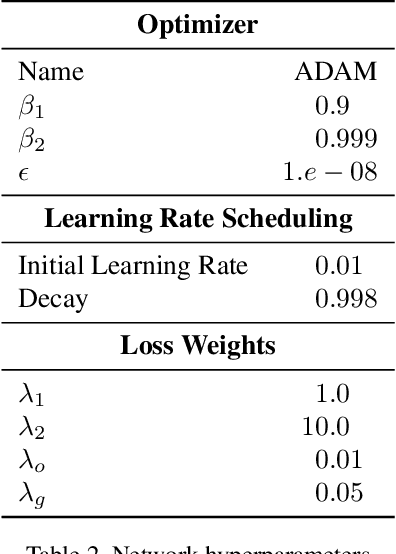
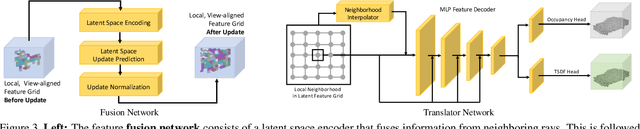
We present a novel online depth map fusion approach that learns depth map aggregation in a latent feature space. While previous fusion methods use an explicit scene representation like signed distance functions (SDFs), we propose a learned feature representation for the fusion. The key idea is a separation between the scene representation used for the fusion and the output scene representation, via an additional translator network. Our neural network architecture consists of two main parts: a depth and feature fusion sub-network, which is followed by a translator sub-network to produce the final surface representation (e.g. TSDF) for visualization or other tasks. Our approach is real-time capable, handles high noise levels, and is particularly able to deal with gross outliers common for photometric stereo-based depth maps. Experiments on real and synthetic data demonstrate improved results compared to the state of the art, especially in challenging scenarios with large amounts of noise and outliers.
RoutedFusion: Learning Real-time Depth Map Fusion
Jan 13, 2020


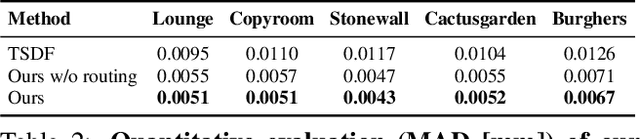
The efficient fusion of depth maps is a key part of most state-of-the-art 3D reconstruction methods. Besides requiring high accuracy, these depth fusion methods need to be scalable and real-time capable. To this end, we present a novel real-time capable machine learning-based method for depth map fusion. Similar to the seminal depth map fusion approach by Curless and Levoy, we only update a local group of voxels to ensure real-time capability. Instead of a simple linear fusion of depth information, we propose a neural network that predicts non-linear updates to better account for typical fusion errors. Our network is composed of a 2D depth routing network and a 3D depth fusion network which efficiently handle sensor-specific noise and outliers. This is especially useful for surface edges and thin objects for which the original approach suffers from thickening artifacts. Our method outperforms the traditional fusion approach and related learned approaches on both synthetic and real data. We demonstrate the performance of our method in reconstructing fine geometric details from noise and outlier contaminated data on various scenes