 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Objects From Neural Radiance Fields
Dec 22, 2022Neural Radiance Fields (NeRFs) are emerging as a ubiquitous scene representation that allows for novel view synthesis. Increasingly, NeRFs will be shareable with other people. Before sharing a NeRF, though, it might be desirable to remove personal information or unsightly objects. Such removal is not easily achieved with the current NeRF editing frameworks. We propose a framework to remove objects from a NeRF representation created from an RGB-D sequence. Our NeRF inpainting method leverages recent work in 2D image inpainting and is guided by a user-provided mask. Our algorithm is underpinned by a confidence based view selection procedure. It chooses which of the individual 2D inpainted images to use in the creation of the NeRF, so that the resulting inpainted NeRF is 3D consistent. We show that our method for NeRF editing is effective for synthesizing plausible inpaintings in a multi-view coherent manner. We validate our approach using a new and still-challenging dataset for the task of NeRF inpainting.
Visual Camera Re-Localization Using Graph Neural Networks and Relative Pose Supervision
Apr 12, 2021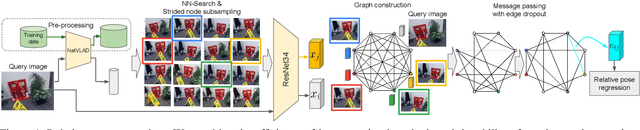
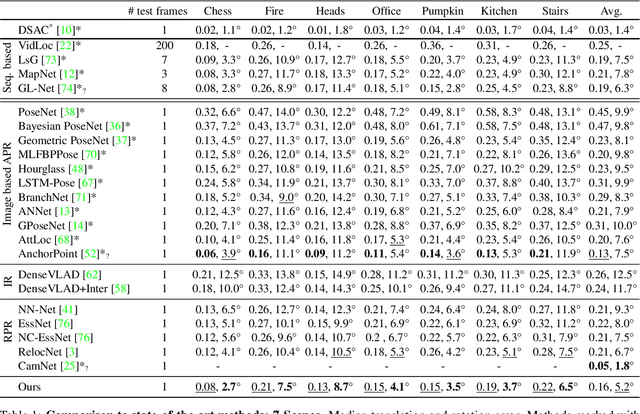
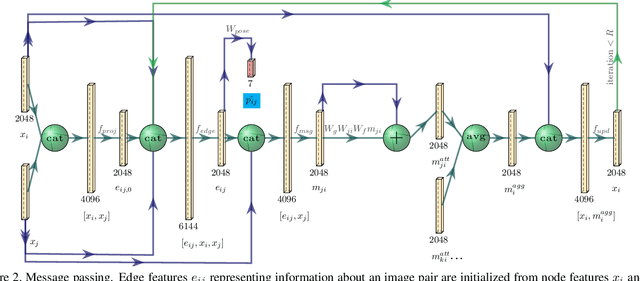

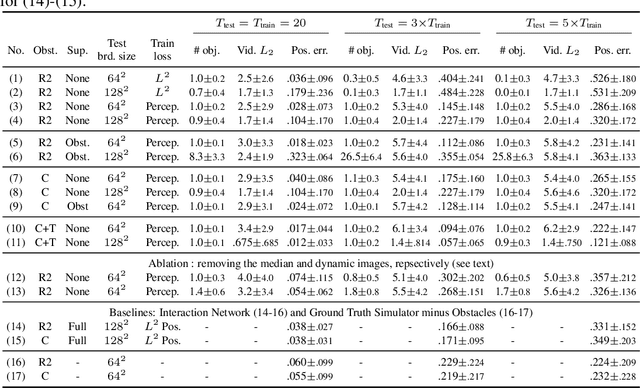
Visual re-localization means using a single image as input to estimate the camera's location and orientation relative to a pre-recorded environment. The highest-scoring methods are "structure based," and need the query camera's intrinsics as an input to the model, with careful geometric optimization. When intrinsics are absent, methods vie for accuracy by making various other assumptions. This yields fairly good localization scores, but the models are "narrow" in some way, eg., requiring costly test-time computations, or depth sensors, or multiple query frames. In contrast, our proposed method makes few special assumptions, and is fairly lightweight in training and testing. Our pose regression network learns from only relative poses of training scenes. For inference, it builds a graph connecting the query image to training counterparts and uses a graph neural network (GNN) with image representations on nodes and image-pair representations on edges. By efficiently passing messages between them, both representation types are refined to produce a consistent camera pose estimate. We validate the effectiveness of our approach on both standard indoor (7-Scenes) and outdoor (Cambridge Landmarks) camera re-localization benchmarks. Our relative pose regression method matches the accuracy of absolute pose regression networks, while retaining the relative-pose models' test-time speed and ability to generalize to non-training scenes.
RELATE: Physically Plausible Multi-Object Scene Synthesis Using Structured Latent Spaces
Jul 02, 2020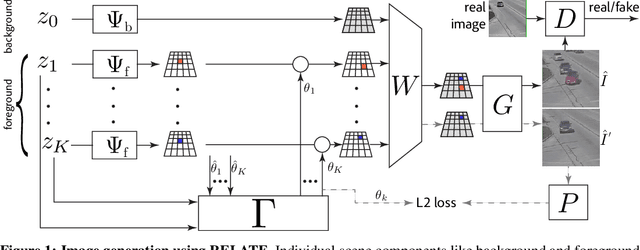

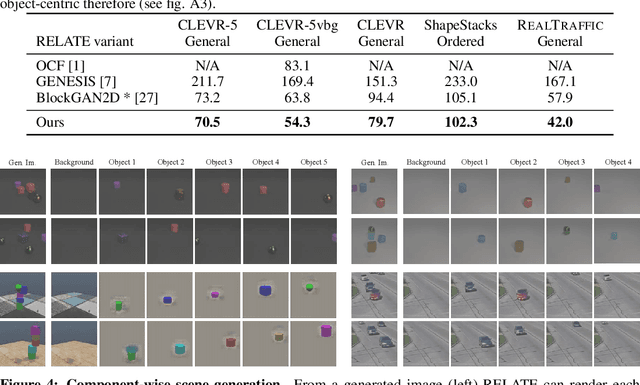

We present RELATE, a model that learns to generate physically plausible scenes and videos of multiple interacting objects. Similar to other generative approaches, RELATE is trained end-to-end on raw, unlabeled data. RELATE combines an object-centric GAN formulation with a model that explicitly accounts for correlations between individual objects. This allows the model to generate realistic scenes and videos from a physically-interpretable parameterization. Furthermore, we show that modeling the object correlation is necessary to learn to disentangle object positions and identity. We find that RELATE is also amenable to physically realistic scene editing and that it significantly outperforms prior art in object-centric scene generation in both synthetic (CLEVR, ShapeStacks) and real-world data (street traffic scenes). In addition, in contrast to state-of-the-art methods in object-centric generative modeling, RELATE also extends naturally to dynamic scenes and generates videos of high visual fidelity
Footprints and Free Space from a Single Color Image
Apr 14, 2020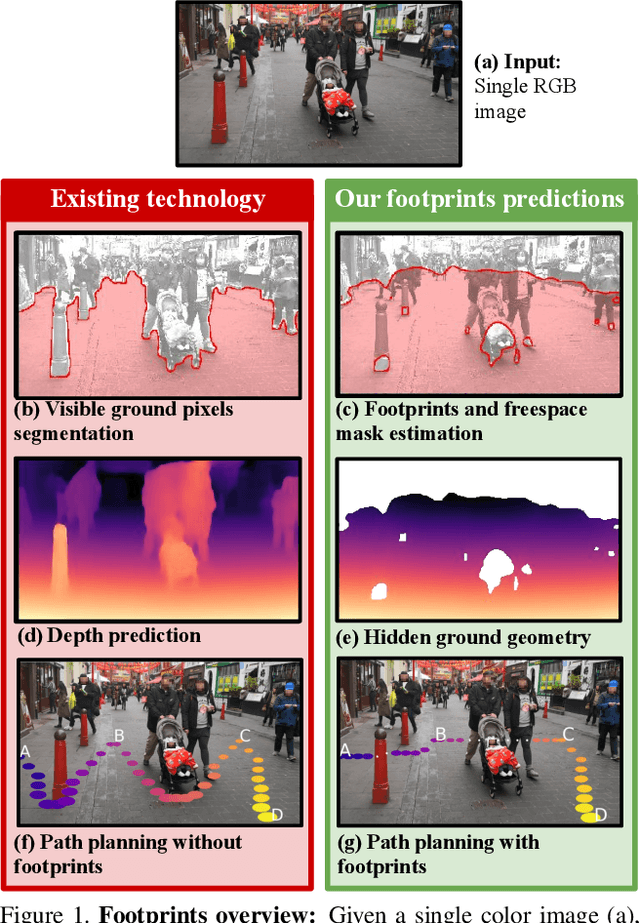

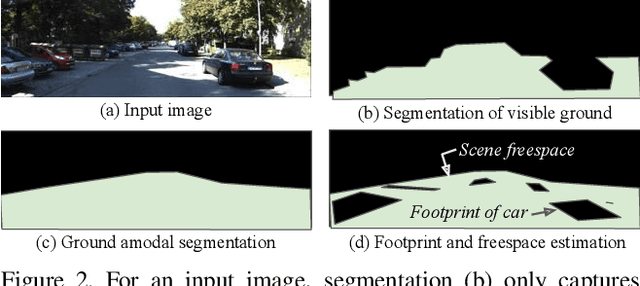

Understanding the shape of a scene from a single color image is a formidable computer vision task. However, most methods aim to predict the geometry of surfaces that are visible to the camera, which is of limited use when planning paths for robots or augmented reality agents. Such agents can only move when grounded on a traversable surface, which we define as the set of classes which humans can also walk over, such as grass, footpaths and pavement. Models which predict beyond the line of sight often parameterize the scene with voxels or meshes, which can be expensive to use in machine learning frameworks. We introduce a model to predict the geometry of both visible and occluded traversable surfaces, given a single RGB image as input. We learn from stereo video sequences, using camera poses, per-frame depth and semantic segmentation to form training data, which is used to supervise an image-to-image network. We train models from the KITTI driving dataset, the indoor Matterport dataset, and from our own casually captured stereo footage. We find that a surprisingly low bar for spatial coverage of training scenes is required. We validate our algorithm against a range of strong baselines, and include an assessment of our predictions for a path-planning task.
Unsupervised Intuitive Physics from Past Experiences
May 26, 2019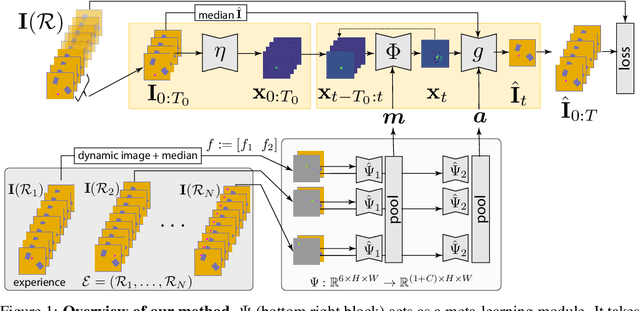


We are interested in learning models of intuitive physics similar to the ones that animals use for navigation, manipulation and planning. In addition to learning general physical principles, however, we are also interested in learning ``on the fly'', from a few experiences, physical properties specific to new environments. We do all this in an unsupervised manner, using a meta-learning formulation where the goal is to predict videos containing demonstrations of physical phenomena, such as objects moving and colliding with a complex background. We introduce the idea of summarizing past experiences in a very compact manner, in our case using dynamic images, and show that this can be used to solve the problem well and efficiently. Empirically, we show via extensive experiments and ablation studies, that our model learns to perform physical predictions that generalize well in time and space, as well as to a variable number of interacting physical objects.
iMapper: Interaction-guided Joint Scene and Human Motion Mapping from Monocular Videos
Jun 20, 2018
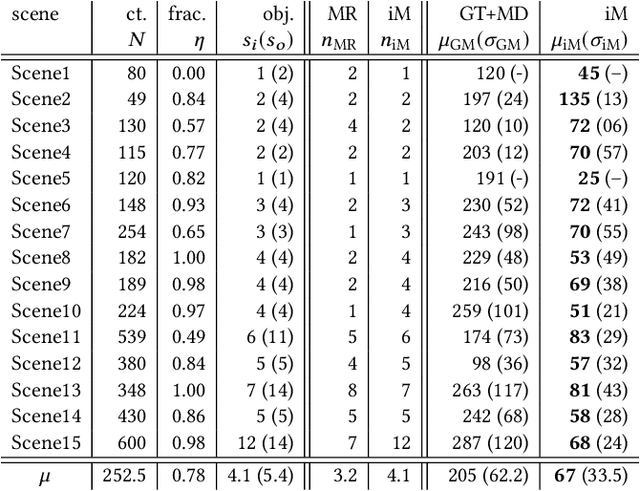

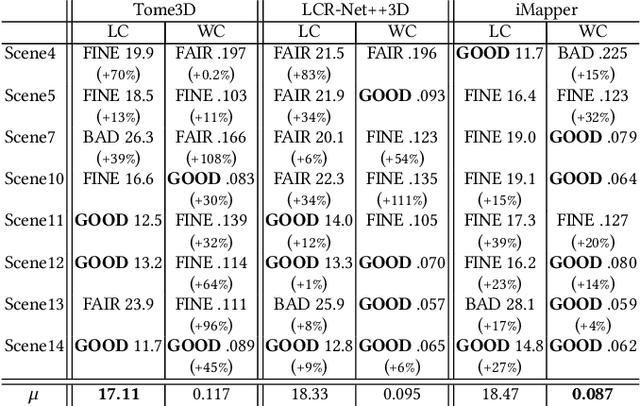
A long-standing challenge in scene analysis is the recovery of scene arrangements under moderate to heavy occlusion, directly from monocular video. While the problem remains a subject of active research, concurrent advances have been made in the context of human pose reconstruction from monocular video, including image-space feature point detection and 3D pose recovery. These methods, however, start to fail under moderate to heavy occlusion as the problem becomes severely under-constrained. We approach the problems differently. We observe that people interact similarly in similar scenes. Hence, we exploit the correlation between scene object arrangement and motions performed in that scene in both directions: first, typical motions performed when interacting with objects inform us about possible object arrangements; and second, object arrangements, in turn, constrain the possible motions. We present iMapper, a data-driven method that focuses on identifying human-object interactions, and jointly reasons about objects and human movement over space-time to recover both a plausible scene arrangement and consistent human interactions. We first introduce the notion of characteristic interactions as regions in space-time when an informative human-object interaction happens. This is followed by a novel occlusion-aware matching procedure that searches and aligns such characteristic snapshots from an interaction database to best explain the input monocular video. Through extensive evaluations, both quantitative and qualitative, we demonstrate that iMapper significantly improves performance over both dedicated state-of-the-art scene analysis and 3D human pose recovery approaches, especially under medium to heavy occlusion.
Unsupervised Intuitive Physics from Visual Observations
May 14, 2018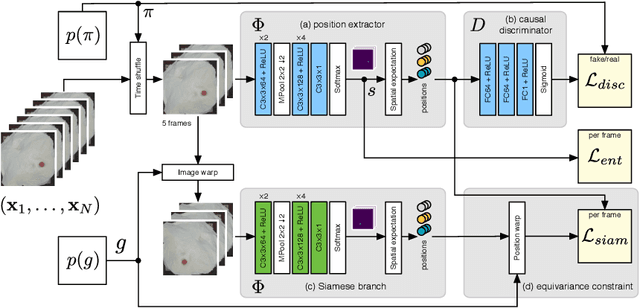
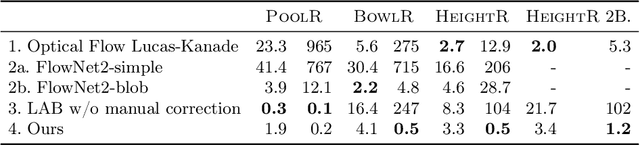
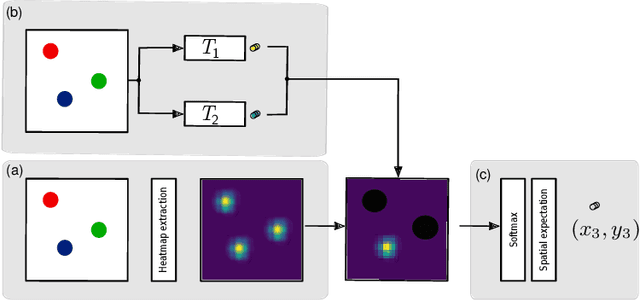
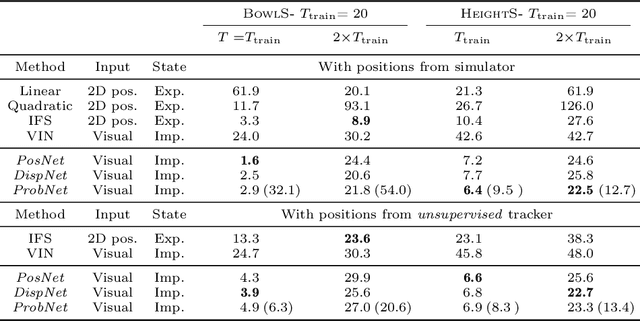
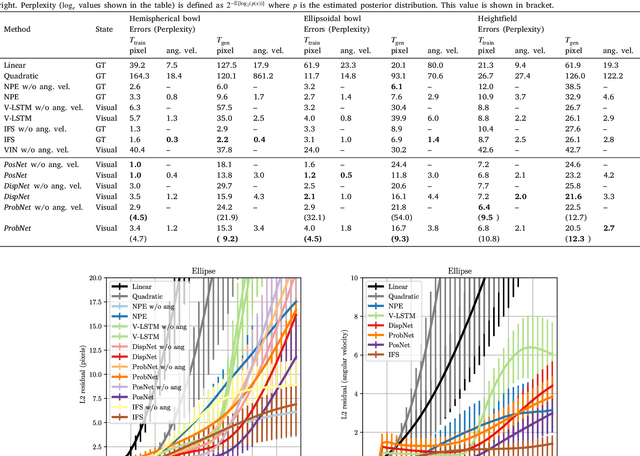
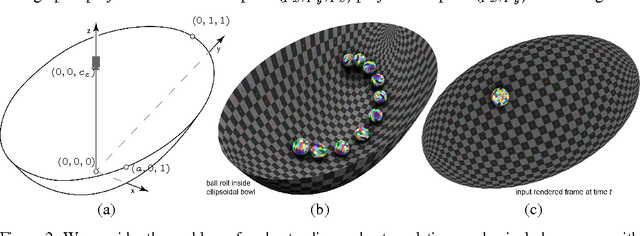
While learning models of intuitive physics is an increasingly active area of research, current approaches still fall short of natural intelligences in one important regard: they require external supervision, such as explicit access to physical states, at training and sometimes even at test times. Some authors have relaxed such requirements by supplementing the model with an handcrafted physical simulator. Still, the resulting methods are unable to automatically learn new complex environments and to understand physical interactions within them. In this work, we demonstrated for the first time learning such predictors directly from raw visual observations and without relying on simulators. We do so in two steps: first, we learn to track mechanically-salient objects in videos using causality and equivariance, two unsupervised learning principles that do not require auto-encoding. Second, we demonstrate that the extracted positions are sufficient to successfully train visual motion predictors that can take the underlying environment into account. We validate our predictors on synthetic datasets; then, we introduce a new dataset, ROLL4REAL, consisting of real objects rolling on complex terrains (pool table, elliptical bowl, and random height-field). We show that in all such cases it is possible to learn reliable extrapolators of the object trajectories from raw videos alone, without any form of external supervision and with no more prior knowledge than the choice of a convolutional neural network architecture.
Taking Visual Motion Prediction To New Heightfields
Dec 22, 2017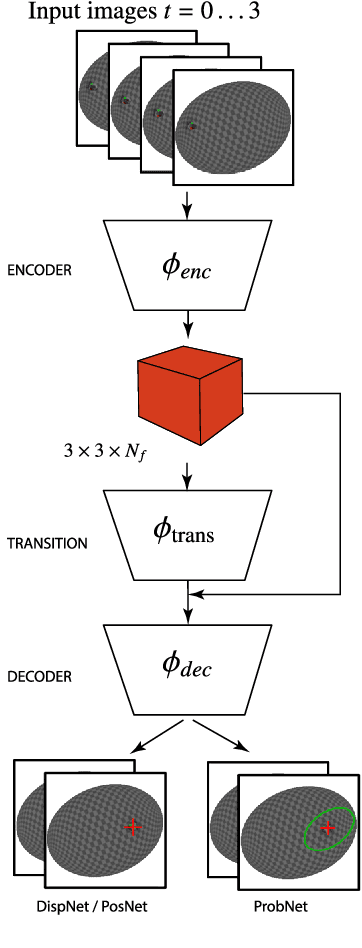

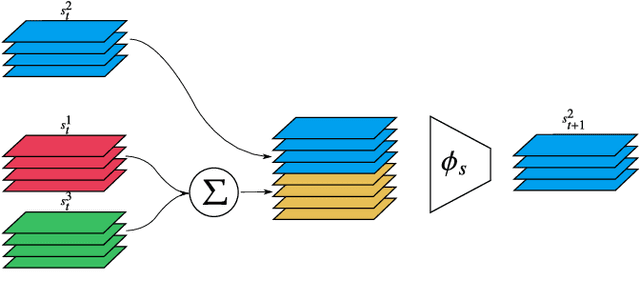
While the basic laws of Newtonian mechanics are well understood, explaining a physical scenario still requires manually modeling the problem with suitable equations and estimating the associated parameters. In order to be able to leverage the approximation capabilities of artificial intelligence techniques in such physics related contexts, researchers have handcrafted the relevant states, and then used neural networks to learn the state transitions using simulation runs as training data. Unfortunately, such approaches are unsuited for modeling complex real-world scenarios, where manually authoring relevant state spaces tend to be tedious and challenging. In this work, we investigate if neural networks can implicitly learn physical states of real-world mechanical processes only based on visual data while internally modeling non-homogeneous environment and in the process enable long-term physical extrapolation. We develop a recurrent neural network architecture for this task and also characterize resultant uncertainties in the form of evolving variance estimates. We evaluate our setup to extrapolate motion of rolling ball(s) on bowls of varying shape and orientation, and on arbitrary heightfields using only images as input. We report significant improvements over existing image-based methods both in terms of accuracy of predictions and complexity of scenarios; and report competitive performance with approaches that, unlike us, assume access to internal physical states.
Learning to Represent Mechanics via Long-term Extrapolation and Interpolation
Jun 08, 2017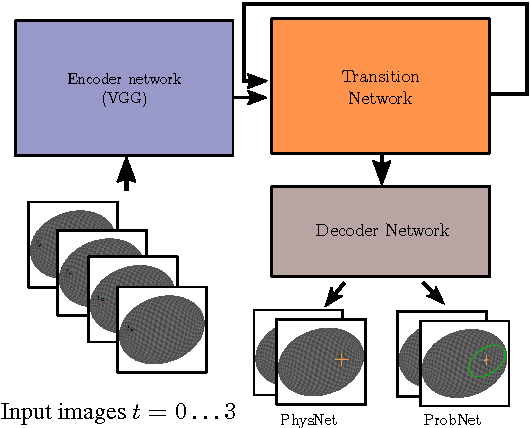

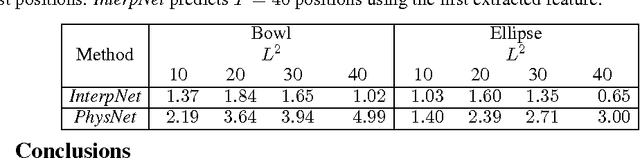
While the basic laws of Newtonian mechanics are well understood, explaining a physical scenario still requires manually modeling the problem with suitable equations and associated parameters. In order to adopt such models for artificial intelligence, researchers have handcrafted the relevant states, and then used neural networks to learn the state transitions using simulation runs as training data. Unfortunately, such approaches can be unsuitable for modeling complex real-world scenarios, where manually authoring relevant state spaces tend to be challenging. In this work, we investigate if neural networks can implicitly learn physical states of real-world mechanical processes only based on visual data, and thus enable long-term physical extrapolation. We develop a recurrent neural network architecture for this task and also characterize resultant uncertainties in the form of evolving variance estimates. We evaluate our setup to extrapolate motion of a rolling ball on bowl of varying shape and orientation using only images as input, and report competitive results with approaches that assume access to internal physics models and parameters.
SMASH: Physics-guided Reconstruction of Collisions from Videos
Apr 10, 2017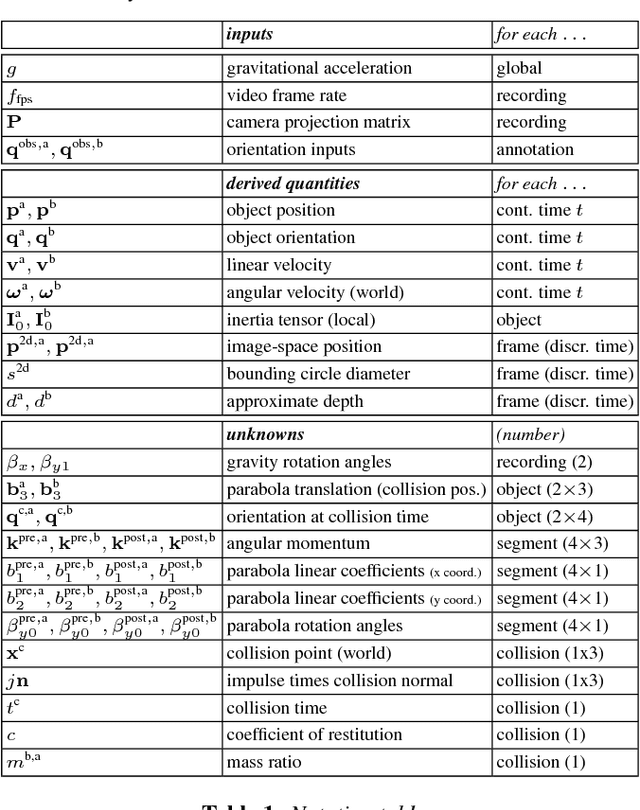

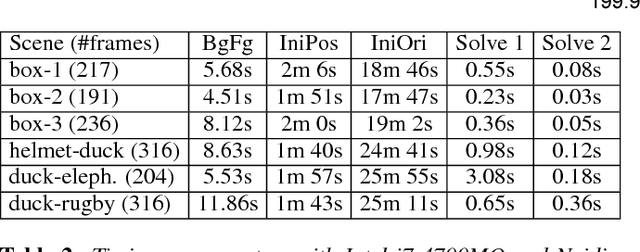
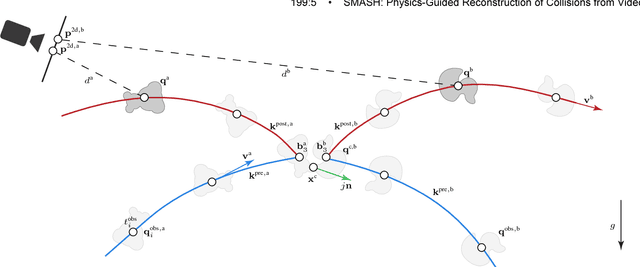
Collision sequences are commonly used in games and entertainment to add drama and excitement. Authoring even two body collisions in the real world can be difficult, as one has to get timing and the object trajectories to be correctly synchronized. After tedious trial-and-error iterations, when objects can actually be made to collide, then they are difficult to capture in 3D. In contrast, synthetically generating plausible collisions is difficult as it requires adjusting different collision parameters (e.g., object mass ratio, coefficient of restitution, etc.) and appropriate initial parameters. We present SMASH to directly read off appropriate collision parameters directly from raw input video recordings. Technically we enable this by utilizing laws of rigid body collision to regularize the problem of lifting 2D trajectories to a physically valid 3D reconstruction of the collision. The reconstructed sequences can then be modified and combined to easily author novel and plausible collisions. We evaluate our system on a range of synthetic scenes and demonstrate the effectiveness of our method by accurately reconstructing several complex real world collision events.
* SIGGRAPH Asia 2016