 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplete Gaussian Splats from a Single Image with Denoising Diffusion Models
Aug 29, 2025Gaussian splatting typically requires dense observations of the scene and can fail to reconstruct occluded and unobserved areas. We propose a latent diffusion model to reconstruct a complete 3D scene with Gaussian splats, including the occluded parts, from only a single image during inference. Completing the unobserved surfaces of a scene is challenging due to the ambiguity of the plausible surfaces. Conventional methods use a regression-based formulation to predict a single "mode" for occluded and out-of-frustum surfaces, leading to blurriness, implausibility, and failure to capture multiple possible explanations. Thus, they often address this problem partially, focusing either on objects isolated from the background, reconstructing only visible surfaces, or failing to extrapolate far from the input views. In contrast, we propose a generative formulation to learn a distribution of 3D representations of Gaussian splats conditioned on a single input image. To address the lack of ground-truth training data, we propose a Variational AutoReconstructor to learn a latent space only from 2D images in a self-supervised manner, over which a diffusion model is trained. Our method generates faithful reconstructions and diverse samples with the ability to complete the occluded surfaces for high-quality 360-degree renderings.
MVSAnywhere: Zero-Shot Multi-View Stereo
Mar 28, 2025Computing accurate depth from multiple views is a fundamental and longstanding challenge in computer vision. However, most existing approaches do not generalize well across different domains and scene types (e.g. indoor vs. outdoor). Training a general-purpose multi-view stereo model is challenging and raises several questions, e.g. how to best make use of transformer-based architectures, how to incorporate additional metadata when there is a variable number of input views, and how to estimate the range of valid depths which can vary considerably across different scenes and is typically not known a priori? To address these issues, we introduce MVSA, a novel and versatile Multi-View Stereo architecture that aims to work Anywhere by generalizing across diverse domains and depth ranges. MVSA combines monocular and multi-view cues with an adaptive cost volume to deal with scale-related issues. We demonstrate state-of-the-art zero-shot depth estimation on the Robust Multi-View Depth Benchmark, surpassing existing multi-view stereo and monocular baselines.
DoubleTake: Geometry Guided Depth Estimation
Jun 26, 2024
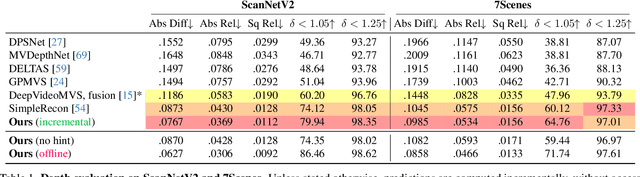
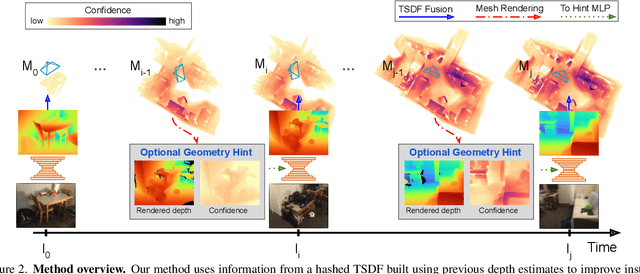
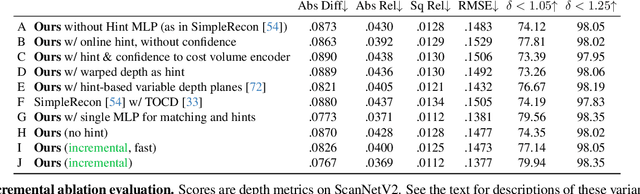
Estimating depth from a sequence of posed RGB images is a fundamental computer vision task, with applications in augmented reality, path planning etc. Prior work typically makes use of previous frames in a multi view stereo framework, relying on matching textures in a local neighborhood. In contrast, our model leverages historical predictions by giving the latest 3D geometry data as an extra input to our network. This self-generated geometric hint can encode information from areas of the scene not covered by the keyframes and it is more regularized when compared to individual predicted depth maps for previous frames. We introduce a Hint MLP which combines cost volume features with a hint of the prior geometry, rendered as a depth map from the current camera location, together with a measure of the confidence in the prior geometry. We demonstrate that our method, which can run at interactive speeds, achieves state-of-the-art estimates of depth and 3D scene reconstruction in both offline and incremental evaluation scenarios.
AirPlanes: Accurate Plane Estimation via 3D-Consistent Embeddings
Jun 13, 2024Extracting planes from a 3D scene is useful for downstream tasks in robotics and augmented reality. In this paper we tackle the problem of estimating the planar surfaces in a scene from posed images. Our first finding is that a surprisingly competitive baseline results from combining popular clustering algorithms with recent improvements in 3D geometry estimation. However, such purely geometric methods are understandably oblivious to plane semantics, which are crucial to discerning distinct planes. To overcome this limitation, we propose a method that predicts multi-view consistent plane embeddings that complement geometry when clustering points into planes. We show through extensive evaluation on the ScanNetV2 dataset that our new method outperforms existing approaches and our strong geometric baseline for the task of plane estimation.
Virtual Occlusions Through Implicit Depth
May 11, 2023



For augmented reality (AR), it is important that virtual assets appear to `sit among' real world objects. The virtual element should variously occlude and be occluded by real matter, based on a plausible depth ordering. This occlusion should be consistent over time as the viewer's camera moves. Unfortunately, small mistakes in the estimated scene depth can ruin the downstream occlusion mask, and thereby the AR illusion. Especially in real-time settings, depths inferred near boundaries or across time can be inconsistent. In this paper, we challenge the need for depth-regression as an intermediate step. We instead propose an implicit model for depth and use that to predict the occlusion mask directly. The inputs to our network are one or more color images, plus the known depths of any virtual geometry. We show how our occlusion predictions are more accurate and more temporally stable than predictions derived from traditional depth-estimation models. We obtain state-of-the-art occlusion results on the challenging ScanNetv2 dataset and superior qualitative results on real scenes.
Removing Objects From Neural Radiance Fields
Dec 22, 2022Neural Radiance Fields (NeRFs) are emerging as a ubiquitous scene representation that allows for novel view synthesis. Increasingly, NeRFs will be shareable with other people. Before sharing a NeRF, though, it might be desirable to remove personal information or unsightly objects. Such removal is not easily achieved with the current NeRF editing frameworks. We propose a framework to remove objects from a NeRF representation created from an RGB-D sequence. Our NeRF inpainting method leverages recent work in 2D image inpainting and is guided by a user-provided mask. Our algorithm is underpinned by a confidence based view selection procedure. It chooses which of the individual 2D inpainted images to use in the creation of the NeRF, so that the resulting inpainted NeRF is 3D consistent. We show that our method for NeRF editing is effective for synthesizing plausible inpaintings in a multi-view coherent manner. We validate our approach using a new and still-challenging dataset for the task of NeRF inpainting.
SimpleRecon: 3D Reconstruction Without 3D Convolutions
Aug 31, 2022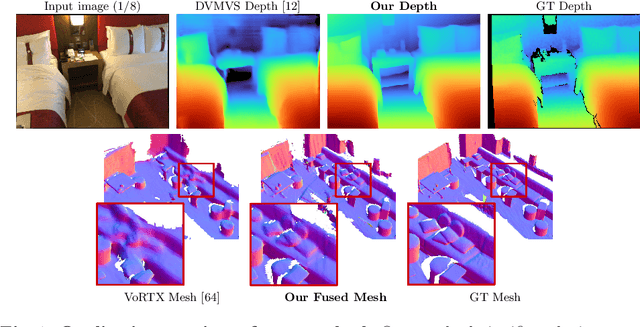
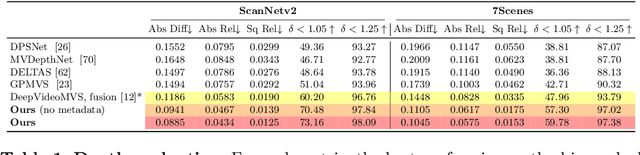
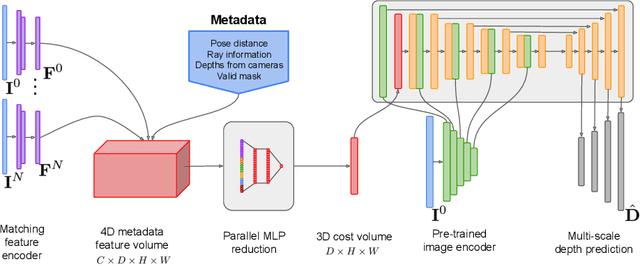
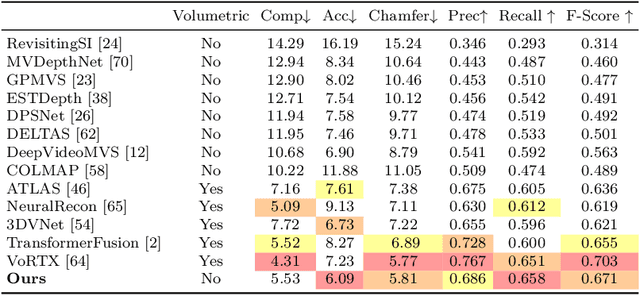
Traditionally, 3D indoor scene reconstruction from posed images happens in two phases: per-image depth estimation, followed by depth merging and surface reconstruction. Recently, a family of methods have emerged that perform reconstruction directly in final 3D volumetric feature space. While these methods have shown impressive reconstruction results, they rely on expensive 3D convolutional layers, limiting their application in resource-constrained environments. In this work, we instead go back to the traditional route, and show how focusing on high quality multi-view depth prediction leads to highly accurate 3D reconstructions using simple off-the-shelf depth fusion. We propose a simple state-of-the-art multi-view depth estimator with two main contributions: 1) a carefully-designed 2D CNN which utilizes strong image priors alongside a plane-sweep feature volume and geometric losses, combined with 2) the integration of keyframe and geometric metadata into the cost volume which allows informed depth plane scoring. Our method achieves a significant lead over the current state-of-the-art for depth estimation and close or better for 3D reconstruction on ScanNet and 7-Scenes, yet still allows for online real-time low-memory reconstruction. Code, models and results are available at https://nianticlabs.github.io/simplerecon
Single Image Depth Estimation using Wavelet Decomposition
Jun 03, 2021
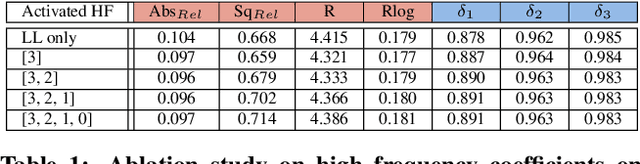
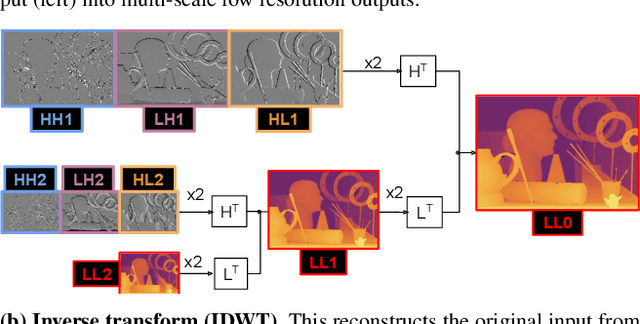
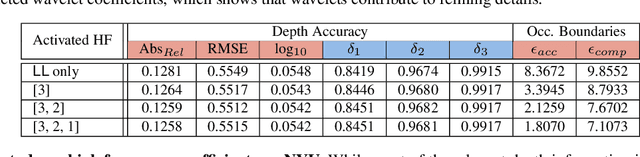
We present a novel method for predicting accurate depths from monocular images with high efficiency. This optimal efficiency is achieved by exploiting wavelet decomposition, which is integrated in a fully differentiable encoder-decoder architecture. We demonstrate that we can reconstruct high-fidelity depth maps by predicting sparse wavelet coefficients. In contrast with previous works, we show that wavelet coefficients can be learned without direct supervision on coefficients. Instead we supervise only the final depth image that is reconstructed through the inverse wavelet transform. We additionally show that wavelet coefficients can be learned in fully self-supervised scenarios, without access to ground-truth depth. Finally, we apply our method to different state-of-the-art monocular depth estimation models, in each case giving similar or better results compared to the original model, while requiring less than half the multiply-adds in the decoder network. Code at https://github.com/nianticlabs/wavelet-monodepth
The Temporal Opportunist: Self-Supervised Multi-Frame Monocular Depth
Apr 29, 2021
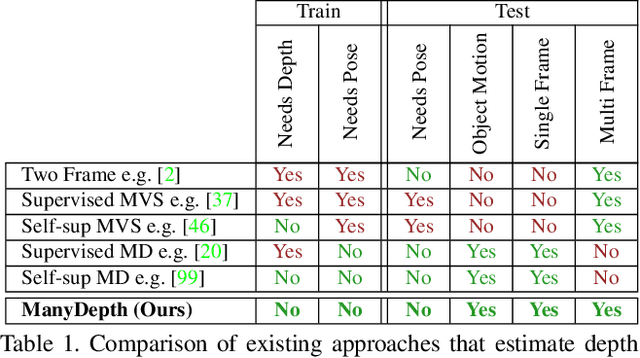
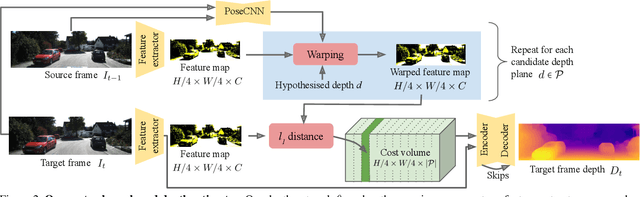
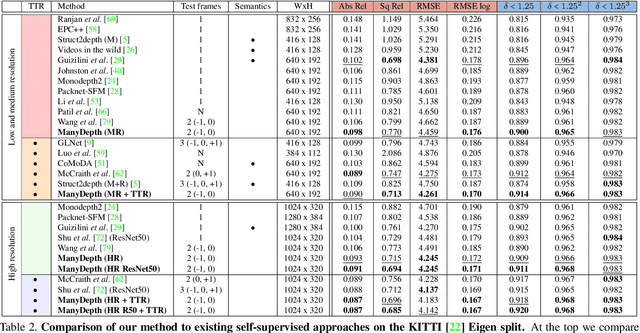
Self-supervised monocular depth estimation networks are trained to predict scene depth using nearby frames as a supervision signal during training. However, for many applications, sequence information in the form of video frames is also available at test time. The vast majority of monocular networks do not make use of this extra signal, thus ignoring valuable information that could be used to improve the predicted depth. Those that do, either use computationally expensive test-time refinement techniques or off-the-shelf recurrent networks, which only indirectly make use of the geometric information that is inherently available. We propose ManyDepth, an adaptive approach to dense depth estimation that can make use of sequence information at test time, when it is available. Taking inspiration from multi-view stereo, we propose a deep end-to-end cost volume based approach that is trained using self-supervision only. We present a novel consistency loss that encourages the network to ignore the cost volume when it is deemed unreliable, e.g. in the case of moving objects, and an augmentation scheme to cope with static cameras. Our detailed experiments on both KITTI and Cityscapes show that we outperform all published self-supervised baselines, including those that use single or multiple frames at test time.
Panoptic Segmentation Forecasting
Apr 08, 2021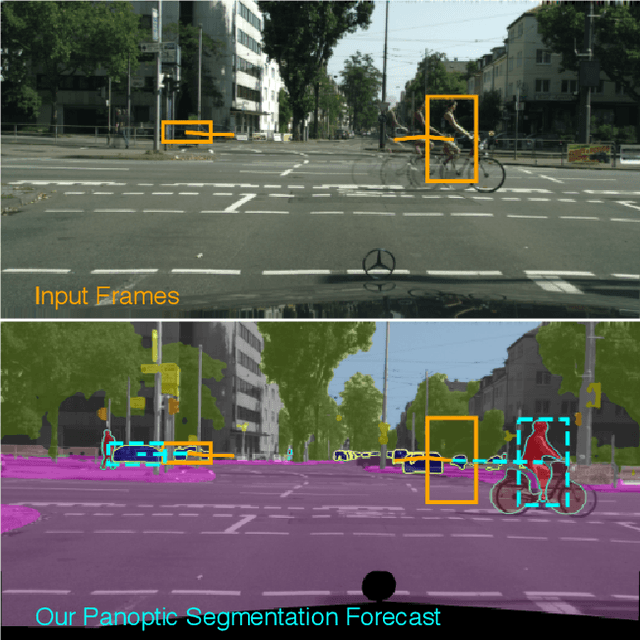

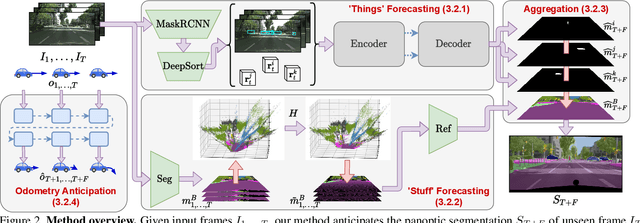
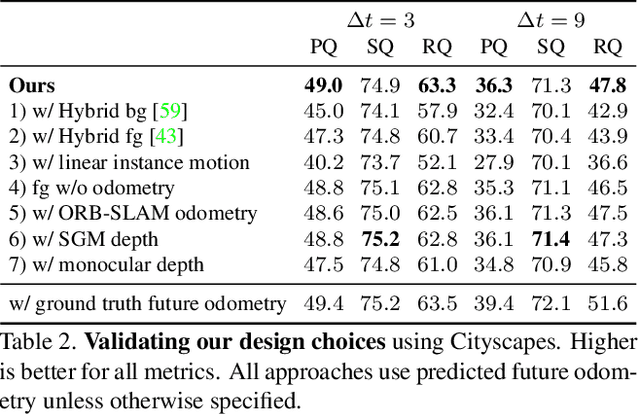
Our goal is to forecast the near future given a set of recent observations. We think this ability to forecast, i.e., to anticipate, is integral for the success of autonomous agents which need not only passively analyze an observation but also must react to it in real-time. Importantly, accurate forecasting hinges upon the chosen scene decomposition. We think that superior forecasting can be achieved by decomposing a dynamic scene into individual 'things' and background 'stuff'. Background 'stuff' largely moves because of camera motion, while foreground 'things' move because of both camera and individual object motion. Following this decomposition, we introduce panoptic segmentation forecasting. Panoptic segmentation forecasting opens up a middle-ground between existing extremes, which either forecast instance trajectories or predict the appearance of future image frames. To address this task we develop a two-component model: one component learns the dynamics of the background stuff by anticipating odometry, the other one anticipates the dynamics of detected things. We establish a leaderboard for this novel task, and validate a state-of-the-art model that outperforms available baselines.