 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
Dec 20, 2024



Self-supervised visual foundation models produce powerful embeddings that achieve remarkable performance on a wide range of downstream tasks. However, unlike vision-language models such as CLIP, self-supervised visual features are not readily aligned with language, hindering their adoption in open-vocabulary tasks. Our method, named dino.txt, unlocks this new ability for DINOv2, a widely used self-supervised visual encoder. We build upon the LiT training strategy, which trains a text encoder to align with a frozen vision model but leads to unsatisfactory results on dense tasks. We propose several key ingredients to improve performance on both global and dense tasks, such as concatenating the [CLS] token with the patch average to train the alignment and curating data using both text and image modalities. With these, we successfully train a CLIP-like model with only a fraction of the computational cost compared to CLIP while achieving state-of-the-art results in zero-shot classification and open-vocabulary semantic segmentation.
CLIP-DINOiser: Teaching CLIP a few DINO tricks
Dec 19, 2023



The popular CLIP model displays impressive zero-shot capabilities thanks to its seamless interaction with arbitrary text prompts. However, its lack of spatial awareness makes it unsuitable for dense computer vision tasks, e.g., semantic segmentation, without an additional fine-tuning step that often uses annotations and can potentially suppress its original open-vocabulary properties. Meanwhile, self-supervised representation methods have demonstrated good localization properties without human-made annotations nor explicit supervision. In this work, we take the best of both worlds and propose a zero-shot open-vocabulary semantic segmentation method, which does not require any annotations. We propose to locally improve dense MaskCLIP features, computed with a simple modification of CLIP's last pooling layer, by integrating localization priors extracted from self-supervised features. By doing so, we greatly improve the performance of MaskCLIP and produce smooth outputs. Moreover, we show that the used self-supervised feature properties can directly be learnt from CLIP features therefore allowing us to obtain the best results with a single pass through CLIP model. Our method CLIP-DINOiser needs only a single forward pass of CLIP and two light convolutional layers at inference, no extra supervision nor extra memory and reaches state-of-the-art results on challenging and fine-grained benchmarks such as COCO, Pascal Context, Cityscapes and ADE20k. The code to reproduce our results is available at https://github.com/wysoczanska/clip_dinoiser.
CLIP-DIY: CLIP Dense Inference Yields Open-Vocabulary Semantic Segmentation For-Free
Sep 25, 2023The emergence of CLIP has opened the way for open-world image perception. The zero-shot classification capabilities of the model are impressive but are harder to use for dense tasks such as image segmentation. Several methods have proposed different modifications and learning schemes to produce dense output. Instead, we propose in this work an open-vocabulary semantic segmentation method, dubbed CLIP-DIY, which does not require any additional training or annotations, but instead leverages existing unsupervised object localization approaches. In particular, CLIP-DIY is a multi-scale approach that directly exploits CLIP classification abilities on patches of different sizes and aggregates the decision in a single map. We further guide the segmentation using foreground/background scores obtained using unsupervised object localization methods. With our method, we obtain state-of-the-art zero-shot semantic segmentation results on PASCAL VOC and perform on par with the best methods on COCO.
MonteBoxFinder: Detecting and Filtering Primitives to Fit a Noisy Point Cloud
Jul 28, 2022
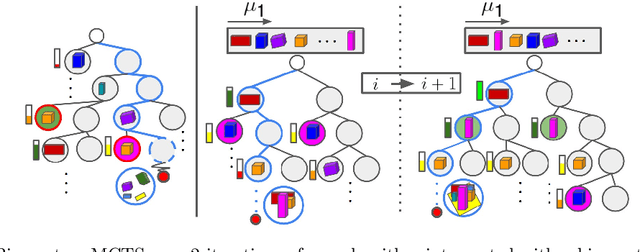
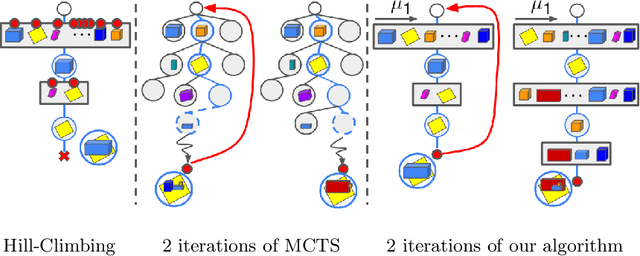
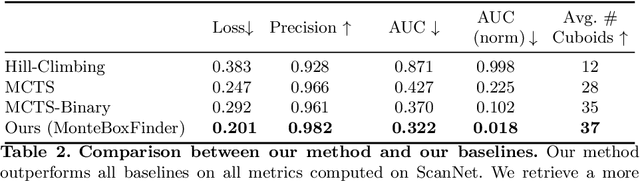
We present MonteBoxFinder, a method that, given a noisy input point cloud, fits cuboids to the input scene. Our primary contribution is a discrete optimization algorithm that, from a dense set of initially detected cuboids, is able to efficiently filter good boxes from the noisy ones. Inspired by recent applications of MCTS to scene understanding problems, we develop a stochastic algorithm that is, by design, more efficient for our task. Indeed, the quality of a fit for a cuboid arrangement is invariant to the order in which the cuboids are added into the scene. We develop several search baselines for our problem and demonstrate, on the ScanNet dataset, that our approach is more efficient and precise. Finally, we strongly believe that our core algorithm is very general and that it could be extended to many other problems in 3D scene understanding.
Single Image Depth Estimation using Wavelet Decomposition
Jun 03, 2021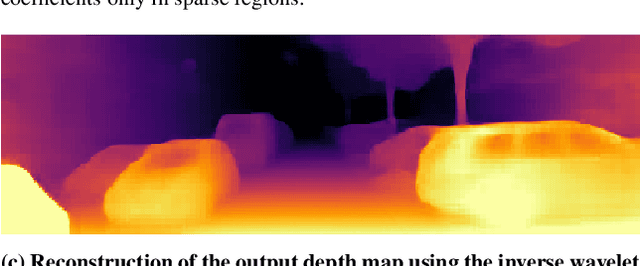
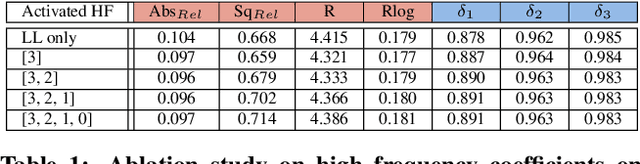
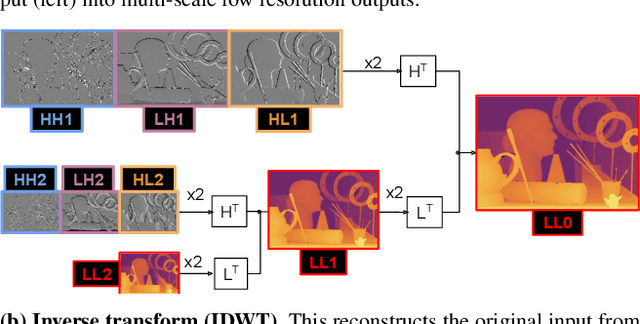
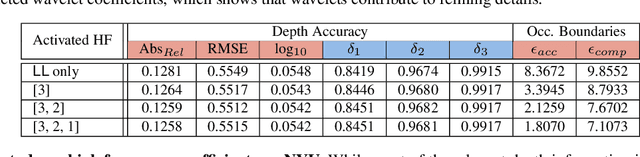
We present a novel method for predicting accurate depths from monocular images with high efficiency. This optimal efficiency is achieved by exploiting wavelet decomposition, which is integrated in a fully differentiable encoder-decoder architecture. We demonstrate that we can reconstruct high-fidelity depth maps by predicting sparse wavelet coefficients. In contrast with previous works, we show that wavelet coefficients can be learned without direct supervision on coefficients. Instead we supervise only the final depth image that is reconstructed through the inverse wavelet transform. We additionally show that wavelet coefficients can be learned in fully self-supervised scenarios, without access to ground-truth depth. Finally, we apply our method to different state-of-the-art monocular depth estimation models, in each case giving similar or better results compared to the original model, while requiring less than half the multiply-adds in the decoder network. Code at https://github.com/nianticlabs/wavelet-monodepth
On Object Symmetries and 6D Pose Estimation from Images
Aug 20, 2019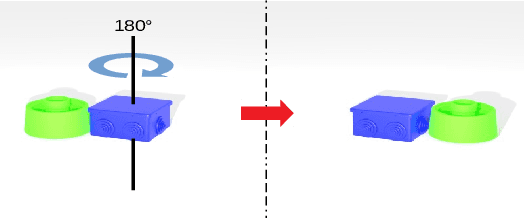
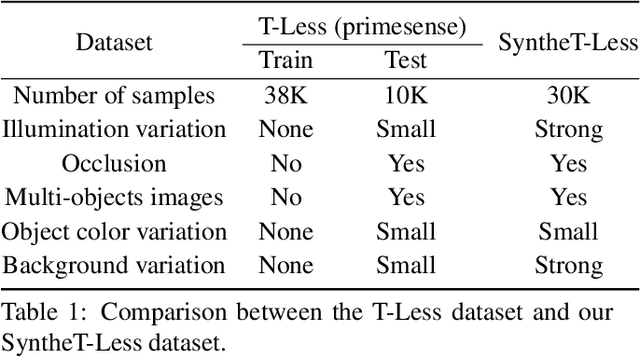
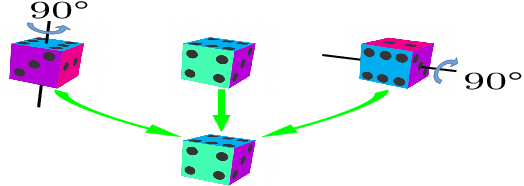
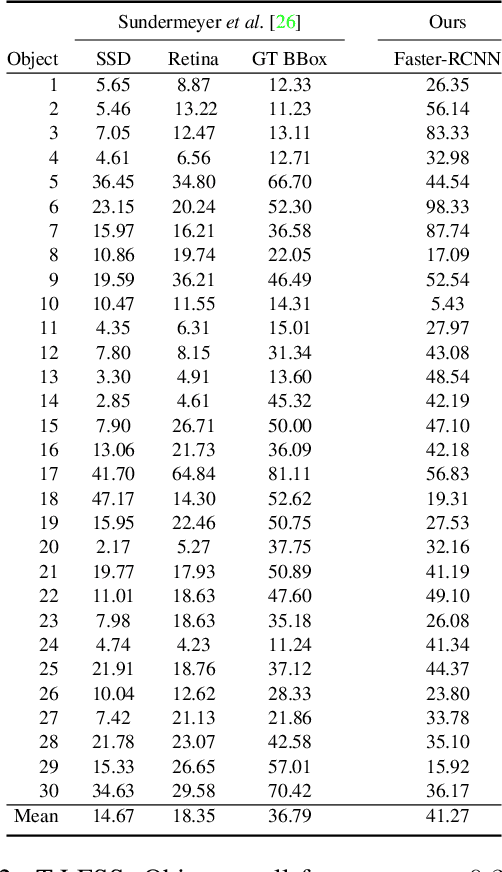
Objects with symmetries are common in our daily life and in industrial contexts, but are often ignored in the recent literature on 6D pose estimation from images. In this paper, we study in an analytical way the link between the symmetries of a 3D object and its appearance in images. We explain why symmetrical objects can be a challenge when training machine learning algorithms that aim at estimating their 6D pose from images. We propose an efficient and simple solution that relies on the normalization of the pose rotation. Our approach is general and can be used with any 6D pose estimation algorithm. Moreover, our method is also beneficial for objects that are 'almost symmetrical', i.e. objects for which only a detail breaks the symmetry. We validate our approach within a Faster-RCNN framework on a synthetic dataset made with objects from the T-Less dataset, which exhibit various types of symmetries, as well as real sequences from T-Less.
SharpNet: Fast and Accurate Recovery of Occluding Contours in Monocular Depth Estimation
May 21, 2019

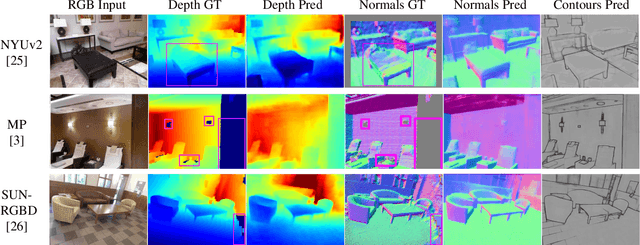

We introduce SharpNet, a method that predicts an accurate depth map for an input color image, with a particular attention to the reconstruction of occluding contours: Occluding contours are an important cue for object recognition, and for realistic integration of virtual objects in Augmented Reality, but they are also notoriously difficult to reconstruct accurately. For example, they are a challenge for stereo-based reconstruction methods, as points around an occluding contour are visible in only one image. Inspired by recent methods that introduce normal estimation to improve depth prediction, we introduce a novel term that constrains depth and occluding contours predictions. Since ground truth depth is difficult to obtain with pixel-perfect accuracy along occluding contours, we use synthetic images for training, followed by fine-tuning on real data. We demonstrate our approach on the challenging NYUv2-Depth dataset, and show that our method outperforms the state-of-the-art along occluding contours, while performing on par with the best recent methods for the rest of the images. Its accuracy along the occluding contours is actually better than the `ground truth' acquired by a depth camera based on structured light. We show this by introducing a new benchmark based on NYUv2-Depth for evaluating occluding contours in monocular reconstruction, which is our second contribution.