 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
Cluster and Predict Latents Patches for Improved Masked Image Modeling
Feb 12, 2025Masked Image Modeling (MIM) offers a promising approach to self-supervised representation learning, however existing MIM models still lag behind the state-of-the-art. In this paper, we systematically analyze target representations, loss functions, and architectures, to introduce CAPI - a novel pure-MIM framework that relies on the prediction of latent clusterings. Our approach leverages a clustering-based loss, which is stable to train, and exhibits promising scaling properties. Our ViT-L backbone, CAPI, achieves 83.8% accuracy on ImageNet and 32.1% mIoU on ADE20K with simple linear probes, substantially outperforming previous MIM methods and approaching the performance of the current state-of-the-art, DINOv2. We release all our code and models.
DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
Dec 20, 2024



Self-supervised visual foundation models produce powerful embeddings that achieve remarkable performance on a wide range of downstream tasks. However, unlike vision-language models such as CLIP, self-supervised visual features are not readily aligned with language, hindering their adoption in open-vocabulary tasks. Our method, named dino.txt, unlocks this new ability for DINOv2, a widely used self-supervised visual encoder. We build upon the LiT training strategy, which trains a text encoder to align with a frozen vision model but leads to unsatisfactory results on dense tasks. We propose several key ingredients to improve performance on both global and dense tasks, such as concatenating the [CLS] token with the patch average to train the alignment and curating data using both text and image modalities. With these, we successfully train a CLIP-like model with only a fraction of the computational cost compared to CLIP while achieving state-of-the-art results in zero-shot classification and open-vocabulary semantic segmentation.
Quantitative Metrics for Evaluating Explanations of Video DeepFake Detectors
Oct 07, 2022
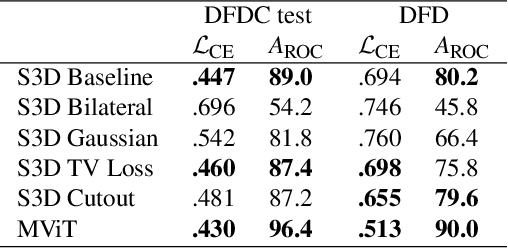
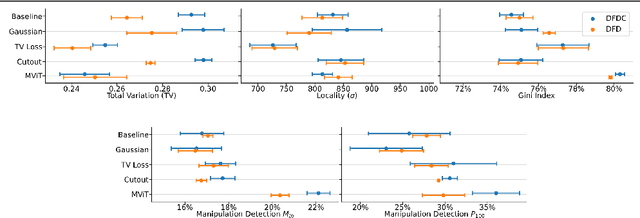
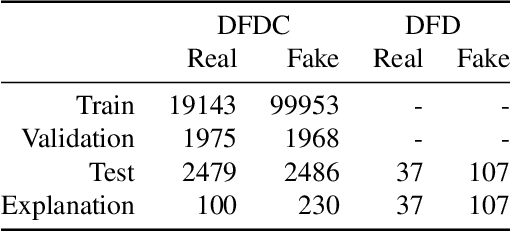
The proliferation of DeepFake technology is a rising challenge in today's society, owing to more powerful and accessible generation methods. To counter this, the research community has developed detectors of ever-increasing accuracy. However, the ability to explain the decisions of such models to users is lacking behind and is considered an accessory in large-scale benchmarks, despite being a crucial requirement for the correct deployment of automated tools for content moderation. We attribute the issue to the reliance on qualitative comparisons and the lack of established metrics. We describe a simple set of metrics to evaluate the visual quality and informativeness of explanations of video DeepFake classifiers from a human-centric perspective. With these metrics, we compare common approaches to improve explanation quality and discuss their effect on both classification and explanation performance on the recent DFDC and DFD datasets.
Towards Self-Supervised Learning of Global and Object-Centric Representations
Mar 11, 2022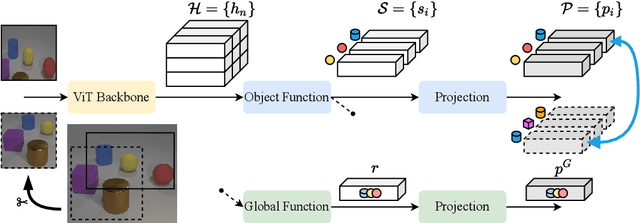



Self-supervision allows learning meaningful representations of natural images which usually contain one central object. How well does it transfer to multi-entity scenes? We discuss key aspects of learning structured object-centric representations with self-supervision and validate our insights through several experiments on the CLEVR dataset. Regarding the architecture, we confirm the importance of competition for attention-based object discovery, where each image patch is exclusively attended by one object. For training, we show that contrastive losses equipped with matching can be applied directly in a latent space, avoiding pixel-based reconstruction. However, such an optimization objective is sensitive to false negatives (recurring objects) and false positives (matching errors). Thus, careful consideration is required around data augmentation and negative sample selection.
Explanation-based Weakly-supervised Learning of Visual Relations with Graph Networks
Jun 16, 2020
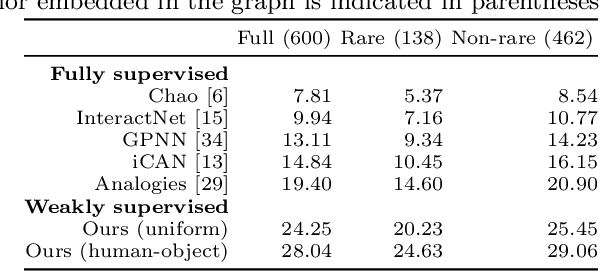
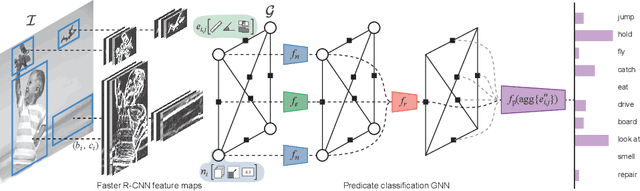
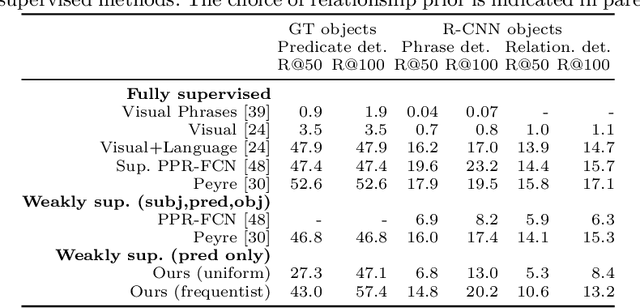
Visual relationship detection is fundamental for holistic image understanding. However, localizing and classifying (subject, predicate, object) triplets constitutes a hard learning objective due to the combinatorial explosion of possible relationships, their long-tail distribution in natural images, and an expensive annotation process. This paper introduces a novel weakly-supervised method for visual relationship detection that relies only on image-level predicate annotations. A graph neural network is trained to classify the predicates in an image from the graph representation of all objects, implicitly encoding an inductive bias for pairwise relationships. We then frame relationship detection as the explanation of such a predicate classifier, i.e. we reconstruct a complete relationship by recovering the subject and the object of a predicted predicate. Using this novel technique and minimal labels, we present comparable results to recent fully-supervised and weakly-supervised methods on three diverse and challenging datasets: HICO-DET for human-object interaction, Visual Relationship Detection for generic object-to-object relationships, and UnRel for unusual relationships.
Explainability Techniques for Graph Convolutional Networks
May 31, 2019
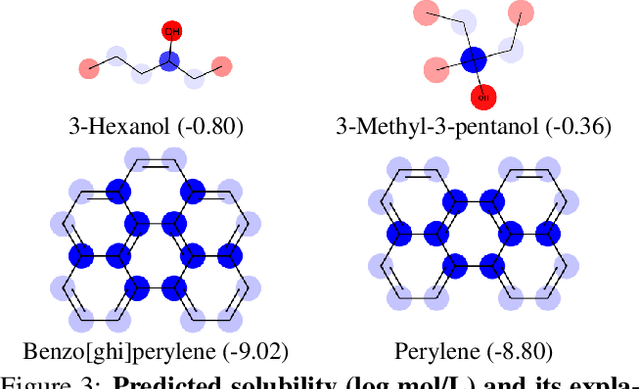
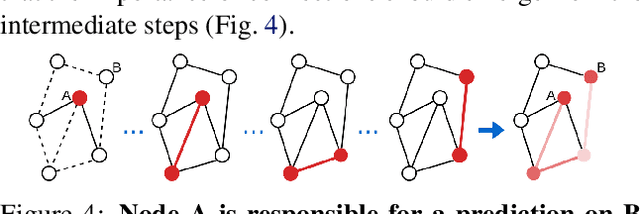

Graph Networks are used to make decisions in potentially complex scenarios but it is usually not obvious how or why they made them. In this work, we study the explainability of Graph Network decisions using two main classes of techniques, gradient-based and decomposition-based, on a toy dataset and a chemistry task. Our study sets the ground for future development as well as application to real-world problems.
Deep Koalarization: Image Colorization using CNNs and Inception-ResNet-v2
Dec 09, 2017

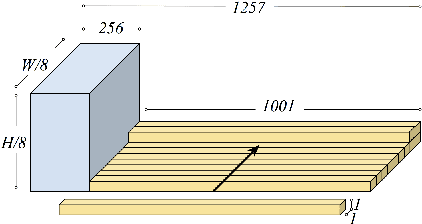

We review some of the most recent approaches to colorize gray-scale images using deep learning methods. Inspired by these, we propose a model which combines a deep Convolutional Neural Network trained from scratch with high-level features extracted from the Inception-ResNet-v2 pre-trained model. Thanks to its fully convolutional architecture, our encoder-decoder model can process images of any size and aspect ratio. Other than presenting the training results, we assess the "public acceptance" of the generated images by means of a user study. Finally, we present a carousel of applications on different types of images, such as historical photographs.