 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Adversarial Robustness of Attribution via Implicit Regularization
May 28, 2026The adversarial robustness of attributions is a fundamental requirement for reliable explainability in deep learning, yet existing approaches typically rely on computationally expensive explicit regularization. In this work, we show that attribution robustness can arise implicitly from the learning dynamics of standard stochastic gradient descent. We theoretically motivate this effect through connections between parameter-space and input-space curvature, and validate it across architectures, datasets, and attribution methods, with negligible computational overhead. In contrast, we prove that such robustness gains often does not transfer to attention-based attribution under softmax normalization, due to inherent entropy constraints, and we validate this limitation experimentally. Finally, we show that replacing softmax attention with kernel-based attention restores the robustness gains in transformer models. Our results highlight learning dynamics as a principled and practical mechanism for robust explainability, and reveal fundamental limitations of attention-based attribution under normalization.
Earth Embeddings as Products: Taxonomy, Ecosystem, and Standardized Access
Jan 19, 2026Geospatial Foundation Models (GFMs) provide powerful representations, but high compute costs hinder their widespread use. Pre-computed embedding data products offer a practical "frozen" alternative, yet they currently exist in a fragmented ecosystem of incompatible formats and resolutions. This lack of standardization creates an engineering bottleneck that prevents meaningful model comparison and reproducibility. We formalize this landscape through a three-layer taxonomy: Data, Tools, and Value. We survey existing products to identify interoperability barriers. To bridge this gap, we extend TorchGeo with a unified API that standardizes the loading and querying of diverse embedding products. By treating embeddings as first-class geospatial datasets, we decouple downstream analysis from model-specific engineering, providing a roadmap for more transparent and accessible Earth observation workflows.
Mode-Seeking for Inverse Problems with Diffusion Models
Dec 11, 2025A pre-trained unconditional diffusion model, combined with posterior sampling or maximum a posteriori (MAP) estimation techniques, can solve arbitrary inverse problems without task-specific training or fine-tuning. However, existing posterior sampling and MAP estimation methods often rely on modeling approximations and can be computationally demanding. In this work, we propose the variational mode-seeking loss (VML), which, when minimized during each reverse diffusion step, guides the generated sample towards the MAP estimate. VML arises from a novel perspective of minimizing the Kullback-Leibler (KL) divergence between the diffusion posterior $p(\mathbf{x}_0|\mathbf{x}_t)$ and the measurement posterior $p(\mathbf{x}_0|\mathbf{y})$, where $\mathbf{y}$ denotes the measurement. Importantly, for linear inverse problems, VML can be analytically derived and need not be approximated. Based on further theoretical insights, we propose VML-MAP, an empirically effective algorithm for solving inverse problems, and validate its efficacy over existing methods in both performance and computational time, through extensive experiments on diverse image-restoration tasks across multiple datasets.
Energy-Based Flow Matching for Generating 3D Molecular Structure
Aug 26, 2025Molecular structure generation is a fundamental problem that involves determining the 3D positions of molecules' constituents. It has crucial biological applications, such as molecular docking, protein folding, and molecular design. Recent advances in generative modeling, such as diffusion models and flow matching, have made great progress on these tasks by modeling molecular conformations as a distribution. In this work, we focus on flow matching and adopt an energy-based perspective to improve training and inference of structure generation models. Our view results in a mapping function, represented by a deep network, that is directly learned to \textit{iteratively} map random configurations, i.e. samples from the source distribution, to target structures, i.e. points in the data manifold. This yields a conceptually simple and empirically effective flow matching setup that is theoretically justified and has interesting connections to fundamental properties such as idempotency and stability, as well as the empirically useful techniques such as structure refinement in AlphaFold. Experiments on protein docking as well as protein backbone generation consistently demonstrate the method's effectiveness, where it outperforms recent baselines of task-associated flow matching and diffusion models, using a similar computational budget.
Leveraging Satellite Image Time Series for Accurate Extreme Event Detection
Jun 13, 2025Climate change is leading to an increase in extreme weather events, causing significant environmental damage and loss of life. Early detection of such events is essential for improving disaster response. In this work, we propose SITS-Extreme, a novel framework that leverages satellite image time series to detect extreme events by incorporating multiple pre-disaster observations. This approach effectively filters out irrelevant changes while isolating disaster-relevant signals, enabling more accurate detection. Extensive experiments on both real-world and synthetic datasets validate the effectiveness of SITS-Extreme, demonstrating substantial improvements over widely used strong bi-temporal baselines. Additionally, we examine the impact of incorporating more timesteps, analyze the contribution of key components in our framework, and evaluate its performance across different disaster types, offering valuable insights into its scalability and applicability for large-scale disaster monitoring.
Hessian-Informed Flow Matching
Oct 15, 2024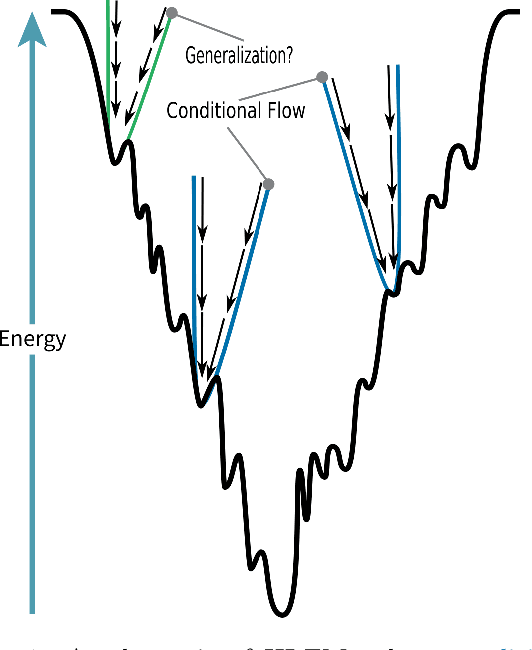

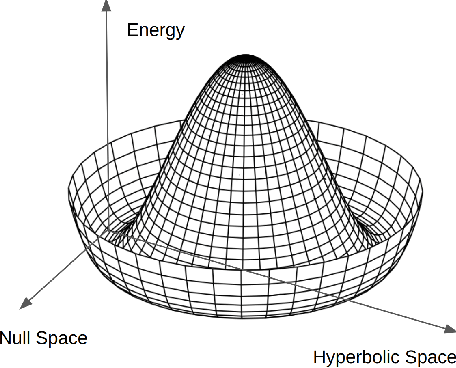

Modeling complex systems that evolve toward equilibrium distributions is important in various physical applications, including molecular dynamics and robotic control. These systems often follow the stochastic gradient descent of an underlying energy function, converging to stationary distributions around energy minima. The local covariance of these distributions is shaped by the energy landscape's curvature, often resulting in anisotropic characteristics. While flow-based generative models have gained traction in generating samples from equilibrium distributions in such applications, they predominately employ isotropic conditional probability paths, limiting their ability to capture such covariance structures. In this paper, we introduce Hessian-Informed Flow Matching (HI-FM), a novel approach that integrates the Hessian of an energy function into conditional flows within the flow matching framework. This integration allows HI-FM to account for local curvature and anisotropic covariance structures. Our approach leverages the linearization theorem from dynamical systems and incorporates additional considerations such as time transformations and equivariance. Empirical evaluations on the MNIST and Lennard-Jones particles datasets demonstrate that HI-FM improves the likelihood of test samples.
Medical Image Segmentation with SAM-generated Annotations
Sep 30, 2024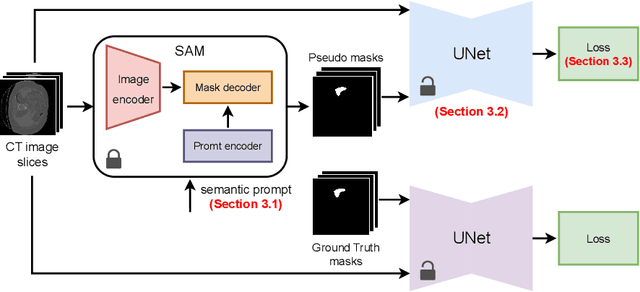

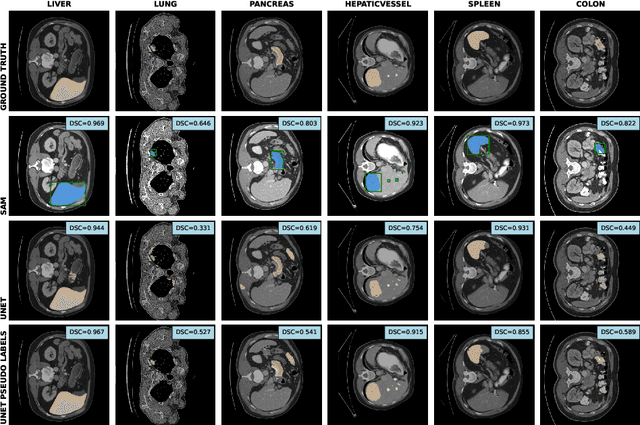
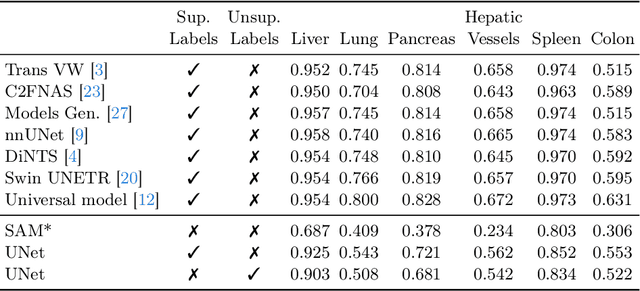
The field of medical image segmentation is hindered by the scarcity of large, publicly available annotated datasets. Not all datasets are made public for privacy reasons, and creating annotations for a large dataset is time-consuming and expensive, as it requires specialized expertise to accurately identify regions of interest (ROIs) within the images. To address these challenges, we evaluate the performance of the Segment Anything Model (SAM) as an annotation tool for medical data by using it to produce so-called "pseudo labels" on the Medical Segmentation Decathlon (MSD) computed tomography (CT) tasks. The pseudo labels are then used in place of ground truth labels to train a UNet model in a weakly-supervised manner. We experiment with different prompt types on SAM and find that the bounding box prompt is a simple yet effective method for generating pseudo labels. This method allows us to develop a weakly-supervised model that performs comparably to a fully supervised model.
Inverse Problems with Diffusion Models: A MAP Estimation Perspective
Jul 27, 2024



Inverse problems have many applications in science and engineering. In Computer vision, several image restoration tasks such as inpainting, deblurring, and super-resolution can be formally modeled as inverse problems. Recently, methods have been developed for solving inverse problems that only leverage a pre-trained unconditional diffusion model and do not require additional task-specific training. In such methods, however, the inherent intractability of determining the conditional score function during the reverse diffusion process poses a real challenge, leaving the methods to settle with an approximation instead, which affects their performance in practice. Here, we propose a MAP estimation framework to model the reverse conditional generation process of a continuous time diffusion model as an optimization process of the underlying MAP objective, whose gradient term is tractable. In theory, the proposed framework can be applied to solve general inverse problems using gradient-based optimization methods. However, given the highly non-convex nature of the loss objective, finding a perfect gradient-based optimization algorithm can be quite challenging, nevertheless, our framework offers several potential research directions. We use our proposed formulation and develop empirically effective algorithms for solving noiseless and noisy image inpainting tasks. We validate our proposed algorithms with extensive experiments across diverse mask settings.
Revisiting Score Function Estimators for $k$-Subset Sampling
Jul 22, 2024



Are score function estimators an underestimated approach to learning with $k$-subset sampling? Sampling $k$-subsets is a fundamental operation in many machine learning tasks that is not amenable to differentiable parametrization, impeding gradient-based optimization. Prior work has focused on relaxed sampling or pathwise gradient estimators. Inspired by the success of score function estimators in variational inference and reinforcement learning, we revisit them within the context of $k$-subset sampling. Specifically, we demonstrate how to efficiently compute the $k$-subset distribution's score function using a discrete Fourier transform, and reduce the estimator's variance with control variates. The resulting estimator provides both exact samples and unbiased gradient estimates while also applying to non-differentiable downstream models, unlike existing methods. Experiments in feature selection show results competitive with current methods, despite weaker assumptions.
Continuous Urban Change Detection from Satellite Image Time Series with Temporal Feature Refinement and Multi-Task Integration
Jun 25, 2024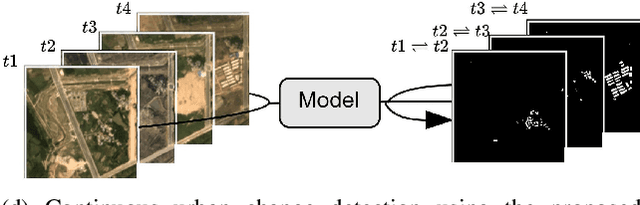
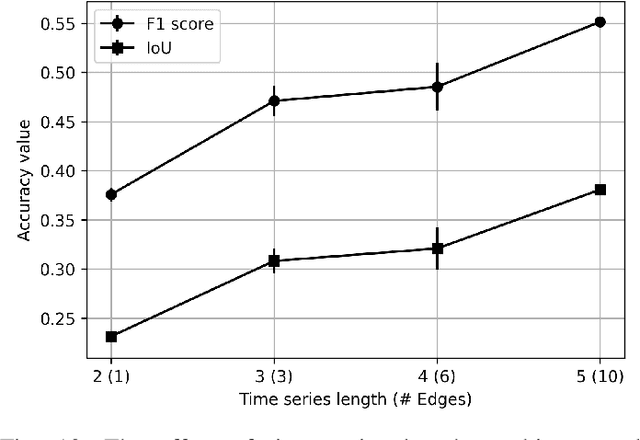
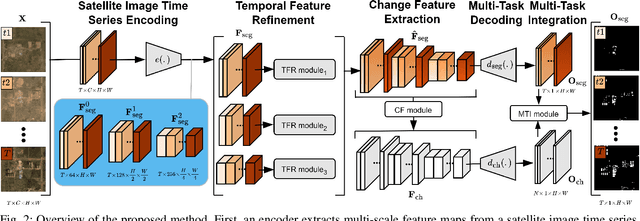
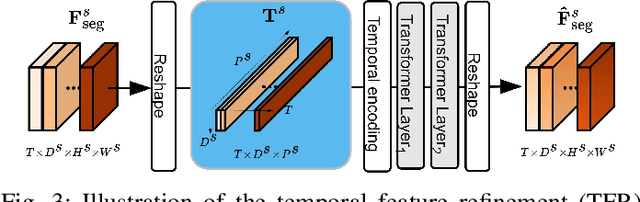
Urbanization advances at unprecedented rates, resulting in negative effects on the environment and human well-being. Remote sensing has the potential to mitigate these effects by supporting sustainable development strategies with accurate information on urban growth. Deep learning-based methods have achieved promising urban change detection results from optical satellite image pairs using convolutional neural networks (ConvNets), transformers, and a multi-task learning setup. However, transformers have not been leveraged for urban change detection with multi-temporal data, i.e., >2 images, and multi-task learning methods lack integration approaches that combine change and segmentation outputs. To fill this research gap, we propose a continuous urban change detection method that identifies changes in each consecutive image pair of a satellite image time series. Specifically, we propose a temporal feature refinement (TFR) module that utilizes self-attention to improve ConvNet-based multi-temporal building representations. Furthermore, we propose a multi-task integration (MTI) module that utilizes Markov networks to find an optimal building map time series based on segmentation and dense change outputs. The proposed method effectively identifies urban changes based on high-resolution satellite image time series acquired by the PlanetScope constellation (F1 score 0.551) and Gaofen-2 (F1 score 0.440). Moreover, our experiments on two challenging datasets demonstrate the effectiveness of the proposed method compared to bi-temporal and multi-temporal urban change detection and segmentation methods.