 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunities for machine learning in scientific discovery
May 07, 2024Technological advancements have substantially increased computational power and data availability, enabling the application of powerful machine-learning (ML) techniques across various fields. However, our ability to leverage ML methods for scientific discovery, {\it i.e.} to obtain fundamental and formalized knowledge about natural processes, is still in its infancy. In this review, we explore how the scientific community can increasingly leverage ML techniques to achieve scientific discoveries. We observe that the applicability and opportunity of ML depends strongly on the nature of the problem domain, and whether we have full ({\it e.g.}, turbulence), partial ({\it e.g.}, computational biochemistry), or no ({\it e.g.}, neuroscience) {\it a-priori} knowledge about the governing equations and physical properties of the system. Although challenges remain, principled use of ML is opening up new avenues for fundamental scientific discoveries. Throughout these diverse fields, there is a theme that ML is enabling researchers to embrace complexity in observational data that was previously intractable to classic analysis and numerical investigations.
Causal discovery from conditionally stationary time-series
Oct 12, 2021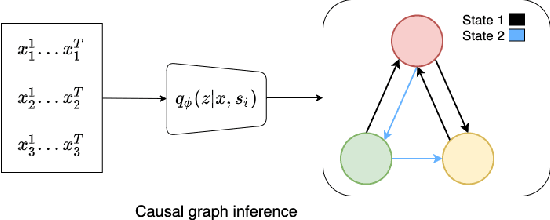

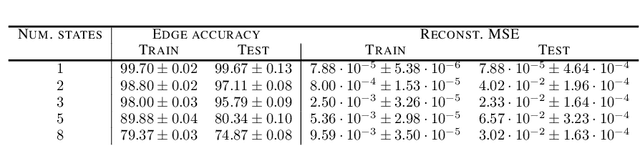

Causal discovery, i.e., inferring underlying cause-effect relationships from observations of a scene or system, is an inherent mechanism in human cognition, but has been shown to be highly challenging to automate. The majority of approaches in the literature aiming for this task consider constrained scenarios with fully observed variables or data from stationary time-series. In this work we aim for causal discovery in a more general class of scenarios, scenes with non-stationary behavior over time. For our purposes we here regard a scene as a composition objects interacting with each other over time. Non-stationarity is modeled as stationarity conditioned on an underlying variable, a state, which can be of varying dimension, more or less hidden given observations of the scene, and also depend more or less directly on these observations. We propose a probabilistic deep learning approach called State-Dependent Causal Inference (SDCI) for causal discovery in such conditionally stationary time-series data. Results in two different synthetic scenarios show that this method is able to recover the underlying causal dependencies with high accuracy even in cases with hidden states.
Advances in Variational Inference
Oct 23, 2018
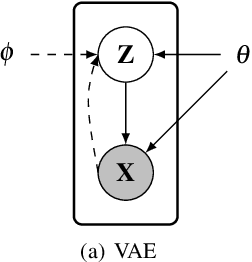
Many modern unsupervised or semi-supervised machine learning algorithms rely on Bayesian probabilistic models. These models are usually intractable and thus require approximate inference. Variational inference (VI) lets us approximate a high-dimensional Bayesian posterior with a simpler variational distribution by solving an optimization problem. This approach has been successfully used in various models and large-scale applications. In this review, we give an overview of recent trends in variational inference. We first introduce standard mean field variational inference, then review recent advances focusing on the following aspects: (a) scalable VI, which includes stochastic approximations, (b) generic VI, which extends the applicability of VI to a large class of otherwise intractable models, such as non-conjugate models, (c) accurate VI, which includes variational models beyond the mean field approximation or with atypical divergences, and (d) amortized VI, which implements the inference over local latent variables with inference networks. Finally, we provide a summary of promising future research directions.
Machine Learning and Social Robotics for Detecting Early Signs of Dementia
Sep 05, 2017
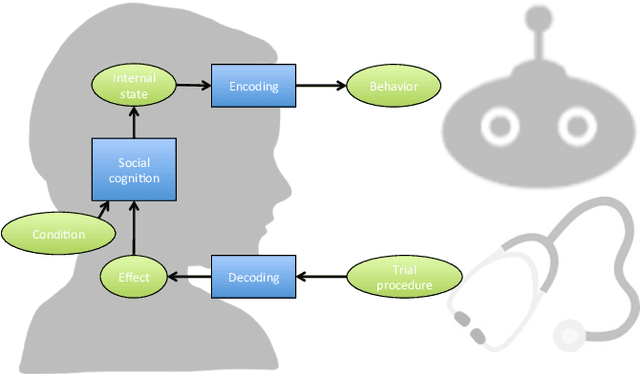
This paper presents the EACare project, an ambitious multi-disciplinary collaboration with the aim to develop an embodied system, capable of carrying out neuropsychological tests to detect early signs of dementia, e.g., due to Alzheimer's disease. The system will use methods from Machine Learning and Social Robotics, and be trained with examples of recorded clinician-patient interactions. The interaction will be developed using a participatory design approach. We describe the scope and method of the project, and report on a first Wizard of Oz prototype.
Determinantal Point Processes for Mini-Batch Diversification
Aug 23, 2017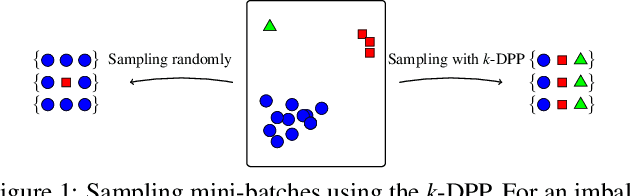

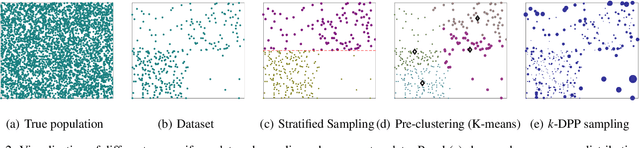
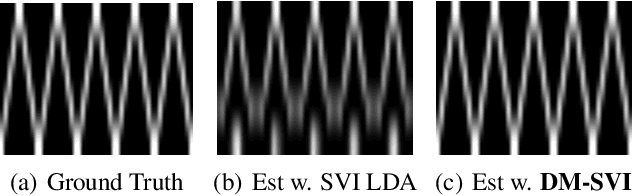
We study a mini-batch diversification scheme for stochastic gradient descent (SGD). While classical SGD relies on uniformly sampling data points to form a mini-batch, we propose a non-uniform sampling scheme based on the Determinantal Point Process (DPP). The DPP relies on a similarity measure between data points and gives low probabilities to mini-batches which contain redundant data, and higher probabilities to mini-batches with more diverse data. This simultaneously balances the data and leads to stochastic gradients with lower variance. We term this approach Diversified Mini-Batch SGD (DM-SGD). We show that regular SGD and a biased version of stratified sampling emerge as special cases. Furthermore, DM-SGD generalizes stratified sampling to cases where no discrete features exist to bin the data into groups. We show experimentally that our method results more interpretable and diverse features in unsupervised setups, and in better classification accuracies in supervised setups.
Diagnostic Prediction Using Discomfort Drawings
Dec 05, 2016
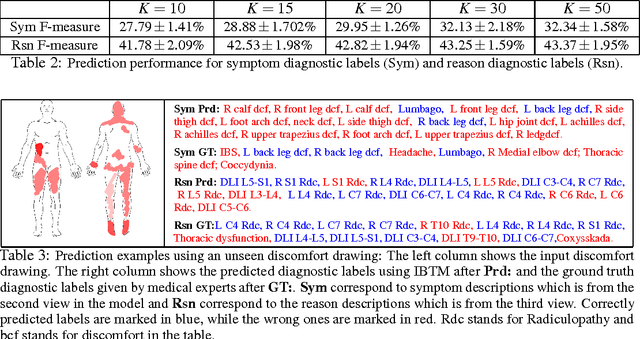
In this paper, we explore the possibility to apply machine learning to make diagnostic predictions using discomfort drawings. A discomfort drawing is an intuitive way for patients to express discomfort and pain related symptoms. These drawings have proven to be an effective method to collect patient data and make diagnostic decisions in real-life practice. A dataset from real-world patient cases is collected for which medical experts provide diagnostic labels. Next, we extend a factorized multimodal topic model, Inter-Battery Topic Model (IBTM), to train a system that can make diagnostic predictions given an unseen discomfort drawing. Experimental results show reasonable predictions of diagnostic labels given an unseen discomfort drawing. The positive result indicates a significant potential of machine learning to be used for parts of the pain diagnostic process and to be a decision support system for physicians and other health care personnel.
Diagnostic Prediction Using Discomfort Drawings with IBTM
Sep 13, 2016


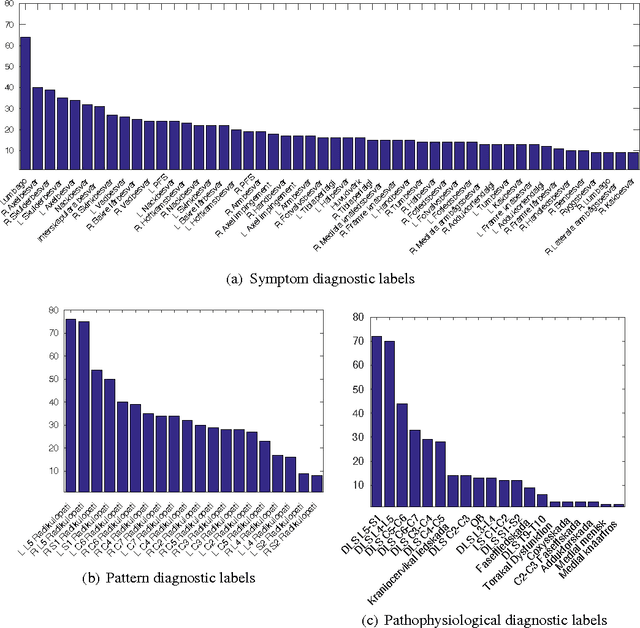
In this paper, we explore the possibility to apply machine learning to make diagnostic predictions using discomfort drawings. A discomfort drawing is an intuitive way for patients to express discomfort and pain related symptoms. These drawings have proven to be an effective method to collect patient data and make diagnostic decisions in real-life practice. A dataset from real-world patient cases is collected for which medical experts provide diagnostic labels. Next, we use a factorized multimodal topic model, Inter-Battery Topic Model (IBTM), to train a system that can make diagnostic predictions given an unseen discomfort drawing. The number of output diagnostic labels is determined by using mean-shift clustering on the discomfort drawing. Experimental results show reasonable predictions of diagnostic labels given an unseen discomfort drawing. Additionally, we generate synthetic discomfort drawings with IBTM given a diagnostic label, which results in typical cases of symptoms. The positive result indicates a significant potential of machine learning to be used for parts of the pain diagnostic process and to be a decision support system for physicians and other health care personnel.
Inter-Battery Topic Representation Learning
Jul 28, 2016
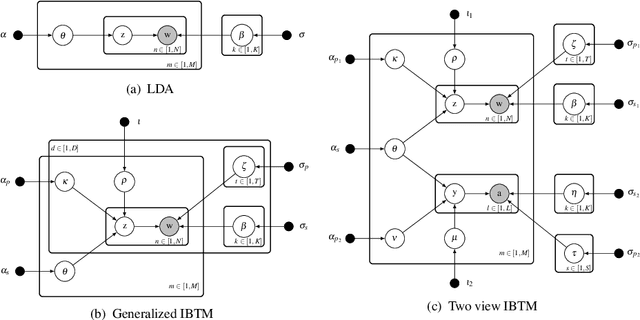


In this paper, we present the Inter-Battery Topic Model (IBTM). Our approach extends traditional topic models by learning a factorized latent variable representation. The structured representation leads to a model that marries benefits traditionally associated with a discriminative approach, such as feature selection, with those of a generative model, such as principled regularization and ability to handle missing data. The factorization is provided by representing data in terms of aligned pairs of observations as different views. This provides means for selecting a representation that separately models topics that exist in both views from the topics that are unique to a single view. This structured consolidation allows for efficient and robust inference and provides a compact and efficient representation. Learning is performed in a Bayesian fashion by maximizing a rigorous bound on the log-likelihood. Firstly, we illustrate the benefits of the model on a synthetic dataset,. The model is then evaluated in both uni- and multi-modality settings on two different classification tasks with off-the-shelf convolutional neural network (CNN) features which generate state-of-the-art results with extremely compact representations.
Factorized Topic Models
Apr 23, 2013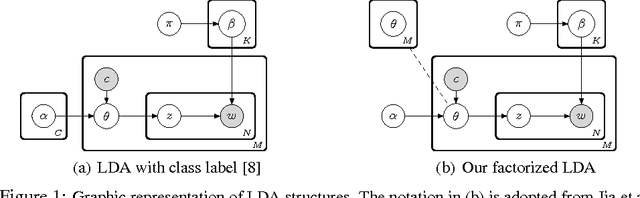
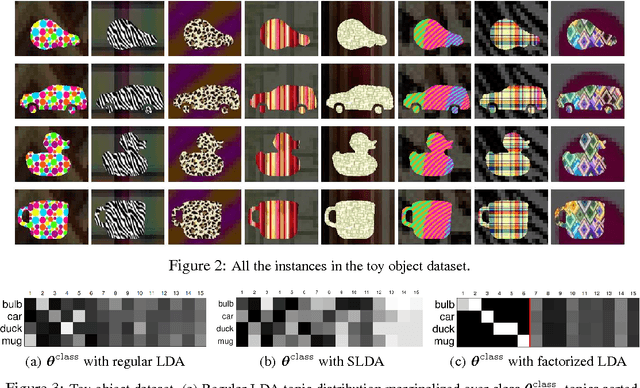


In this paper we present a modification to a latent topic model, which makes the model exploit supervision to produce a factorized representation of the observed data. The structured parameterization separately encodes variance that is shared between classes from variance that is private to each class by the introduction of a new prior over the topic space. The approach allows for a more eff{}icient inference and provides an intuitive interpretation of the data in terms of an informative signal together with structured noise. The factorized representation is shown to enhance inference performance for image, text, and video classification.
Multi-Class Detection and Segmentation of Objects in Depth
Jan 23, 2013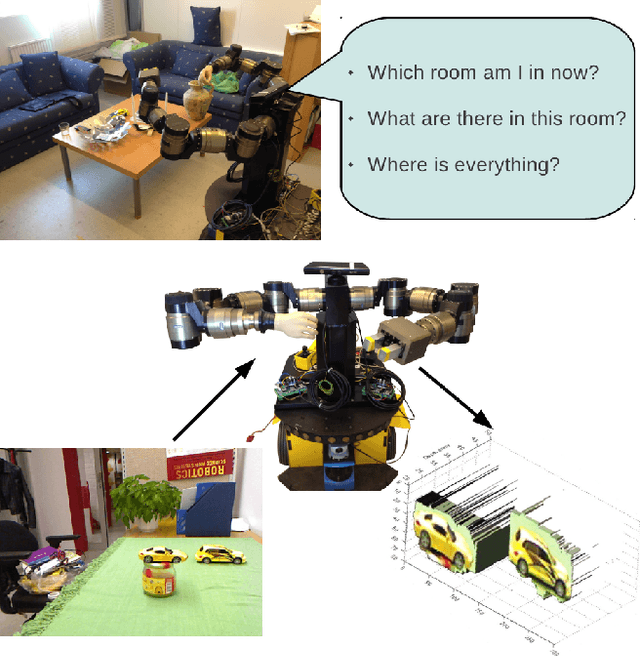


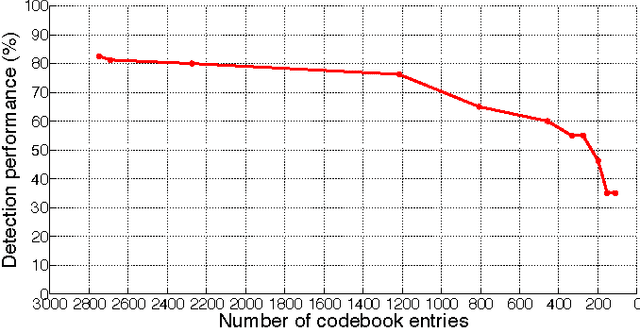
The quality of life of many people could be improved by autonomous humanoid robots in the home. To function in the human world, a humanoid household robot must be able to locate itself and perceive the environment like a human; scene perception, object detection and segmentation, and object spatial localization in 3D are fundamental capabilities for such humanoid robots. This paper presents a 3D multi-class object detection and segmentation method. The contributions are twofold. Firstly, we present a multi-class detection method, where a minimal joint codebook is learned in a principled manner. Secondly, we incorporate depth information using RGB-D imagery, which increases the robustness of the method and gives the 3D location of objects -- necessary since the robot reasons in 3D space. Experiments show that the multi-class extension improves the detection efficiency with respect to the number of classes and the depth extension improves the detection robustness and give sufficient natural 3D location of the objects.