 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSILK: Smooth InterpoLation frameworK for motion in-betweening A Simplified Computational Approach
Jun 09, 2025Motion in-betweening is a crucial tool for animators, enabling intricate control over pose-level details in each keyframe. Recent machine learning solutions for motion in-betweening rely on complex models, incorporating skeleton-aware architectures or requiring multiple modules and training steps. In this work, we introduce a simple yet effective Transformer-based framework, employing a single Transformer encoder to synthesize realistic motions for motion in-betweening tasks. We find that data modeling choices play a significant role in improving in-betweening performance. Among others, we show that increasing data volume can yield equivalent or improved motion transitions, that the choice of pose representation is vital for achieving high-quality results, and that incorporating velocity input features enhances animation performance. These findings challenge the assumption that model complexity is the primary determinant of animation quality and provide insights into a more data-centric approach to motion interpolation. Additional videos and supplementary material are available at https://silk-paper.github.io.
Evaluating Local Model-Agnostic Explanations of Learning to Rank Models with Decision Paths
Mar 16, 2022



Local explanations of learning-to-rank (LTR) models are thought to extract the most important features that contribute to the ranking predicted by the LTR model for a single data point. Evaluating the accuracy of such explanations is challenging since the ground truth feature importance scores are not available for most modern LTR models. In this work, we propose a systematic evaluation technique for explanations of LTR models. Instead of using black-box models, such as neural networks, we propose to focus on tree-based LTR models, from which we can extract the ground truth feature importance scores using decision paths. Once extracted, we can directly compare the ground truth feature importance scores to the feature importance scores generated with explanation techniques. We compare two recently proposed explanation techniques for LTR models when using decision trees and gradient boosting models on the MQ2008 dataset. We show that the explanation accuracy in these techniques can largely vary depending on the explained model and even which data point is explained.
Evaluation of Local Model-Agnostic Explanations Using Ground Truth
Jun 04, 2021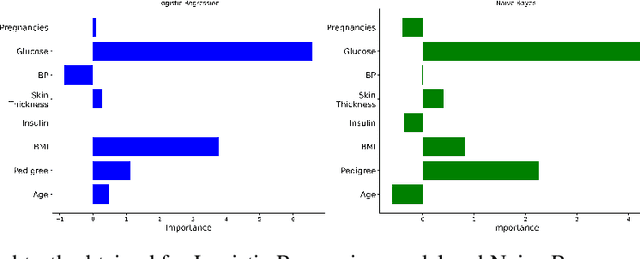

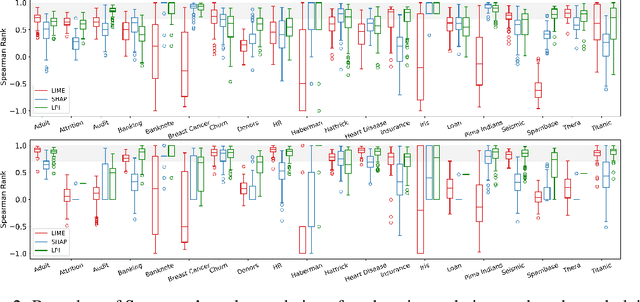
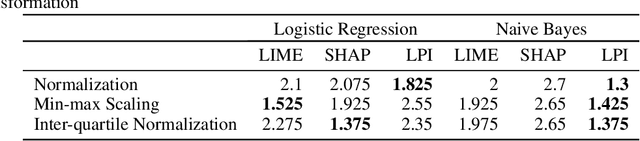
Explanation techniques are commonly evaluated using human-grounded methods, limiting the possibilities for large-scale evaluations and rapid progress in the development of new techniques. We propose a functionally-grounded evaluation procedure for local model-agnostic explanation techniques. In our approach, we generate ground truth for explanations when the black-box model is Logistic Regression and Gaussian Naive Bayes and compare how similar each explanation is to the extracted ground truth. In our empirical study, explanations of Local Interpretable Model-agnostic Explanations (LIME), SHapley Additive exPlanations (SHAP), and Local Permutation Importance (LPI) are compared in terms of how similar they are to the extracted ground truth. In the case of Logistic Regression, we find that the performance of the explanation techniques is highly dependent on the normalization of the data. In contrast, Local Permutation Importance outperforms the other techniques on Naive Bayes, irrespective of normalization. We hope that this work lays the foundation for further research into functionally-grounded evaluation methods for explanation techniques.
Fashion Landmark Detection and Category Classification for Robotics
Mar 26, 2020

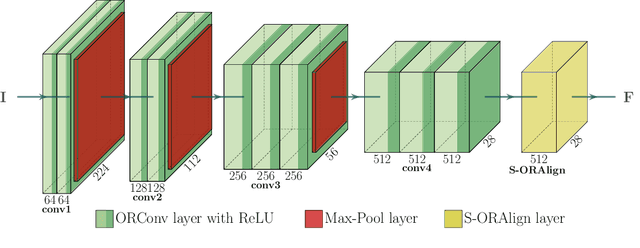
Research on automated, image based identification of clothing categories and fashion landmarks has recently gained significant interest due to its potential impact on areas such as robotic clothing manipulation, automated clothes sorting and recycling, and online shopping. Several public and annotated fashion datasets have been created to facilitate research advances in this direction. In this work, we make the first step towards leveraging the data and techniques developed for fashion image analysis in vision-based robotic clothing manipulation tasks. We focus on techniques that can generalize from large-scale fashion datasets to less structured, small datasets collected in a robotic lab. Specifically, we propose training data augmentation methods such as elastic warping, and model adjustments such as rotation invariant convolutions to make the model generalize better. Our experiments demonstrate that our approach outperforms stateof-the art models with respect to clothing category classification and fashion landmark detection when tested on previously unseen datasets. Furthermore, we present experimental results on a new dataset composed of images where a robot holds different garments, collected in our lab.
Advances in Variational Inference
Oct 23, 2018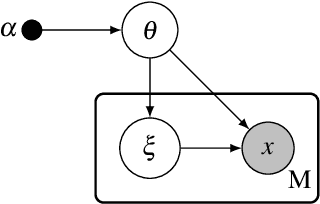
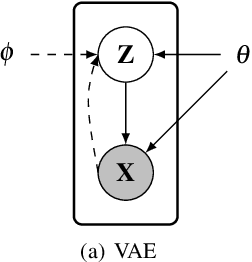
Many modern unsupervised or semi-supervised machine learning algorithms rely on Bayesian probabilistic models. These models are usually intractable and thus require approximate inference. Variational inference (VI) lets us approximate a high-dimensional Bayesian posterior with a simpler variational distribution by solving an optimization problem. This approach has been successfully used in various models and large-scale applications. In this review, we give an overview of recent trends in variational inference. We first introduce standard mean field variational inference, then review recent advances focusing on the following aspects: (a) scalable VI, which includes stochastic approximations, (b) generic VI, which extends the applicability of VI to a large class of otherwise intractable models, such as non-conjugate models, (c) accurate VI, which includes variational models beyond the mean field approximation or with atypical divergences, and (d) amortized VI, which implements the inference over local latent variables with inference networks. Finally, we provide a summary of promising future research directions.