 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Perception for Deformable Object Manipulation
Mar 08, 2024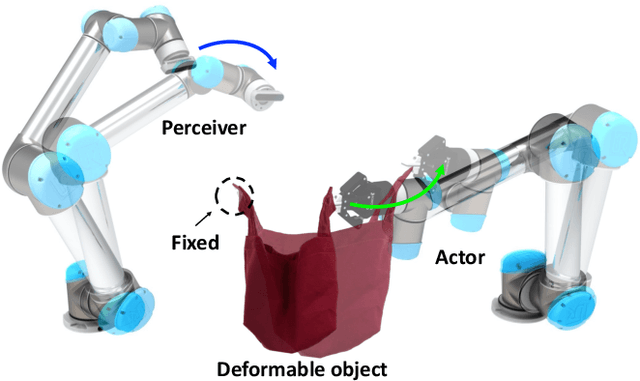
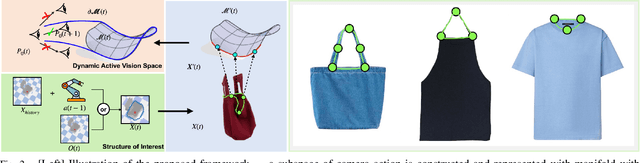
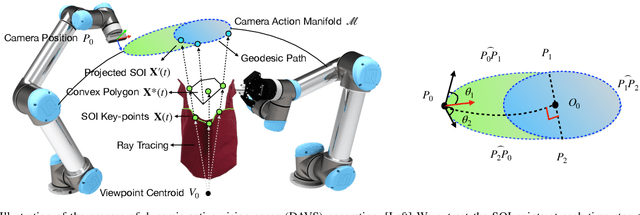
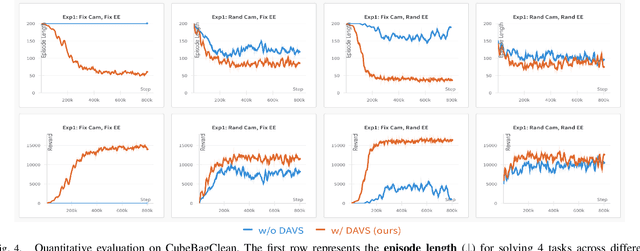
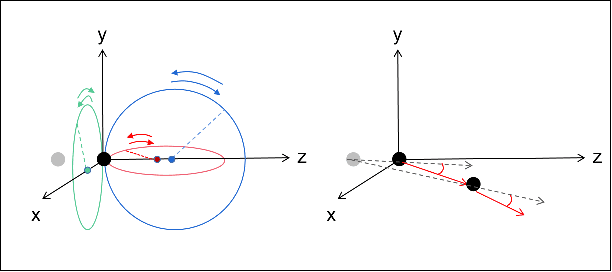
Interactive perception enables robots to manipulate the environment and objects to bring them into states that benefit the perception process. Deformable objects pose challenges to this due to significant manipulation difficulty and occlusion in vision-based perception. In this work, we address such a problem with a setup involving both an active camera and an object manipulator. Our approach is based on a sequential decision-making framework and explicitly considers the motion regularity and structure in coupling the camera and manipulator. We contribute a method for constructing and computing a subspace, called Dynamic Active Vision Space (DAVS), for effectively utilizing the regularity in motion exploration. The effectiveness of the framework and approach are validated in both a simulation and a real dual-arm robot setup. Our results confirm the necessity of an active camera and coordinative motion in interactive perception for deformable objects.
Learning Geometric Representations of Objects via Interaction
Sep 11, 2023



We address the problem of learning representations from observations of a scene involving an agent and an external object the agent interacts with. To this end, we propose a representation learning framework extracting the location in physical space of both the agent and the object from unstructured observations of arbitrary nature. Our framework relies on the actions performed by the agent as the only source of supervision, while assuming that the object is displaced by the agent via unknown dynamics. We provide a theoretical foundation and formally prove that an ideal learner is guaranteed to infer an isometric representation, disentangling the agent from the object and correctly extracting their locations. We evaluate empirically our framework on a variety of scenarios, showing that it outperforms vision-based approaches such as a state-of-the-art keypoint extractor. We moreover demonstrate how the extracted representations enable the agent to solve downstream tasks via reinforcement learning in an efficient manner.
Equivariant Representation Learning via Class-Pose Decomposition
Jul 11, 2022
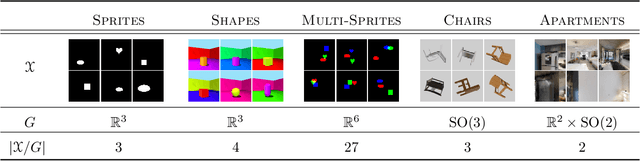
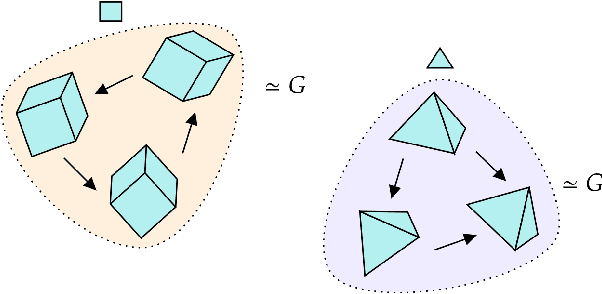
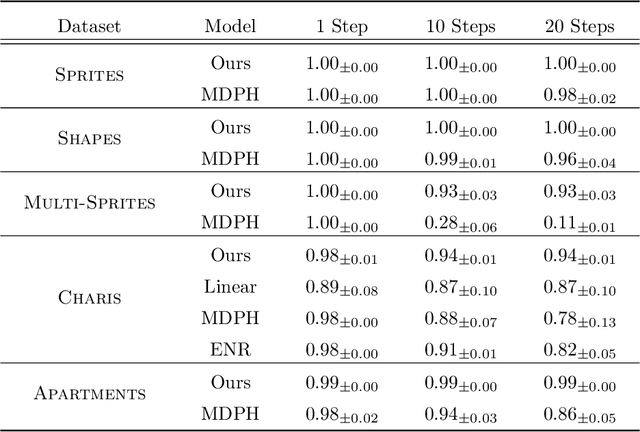
We introduce a general method for learning representations that are equivariant to symmetries of data. Our central idea is to decompose the latent space in an invariant factor and the symmetry group itself. The components semantically correspond to intrinsic data classes and poses respectively. The learner is self-supervised and infers these semantics based on relative symmetry information. The approach is motivated by theoretical results from group theory and guarantees representations that are lossless, interpretable and disentangled. We provide an empirical investigation via experiments involving datasets with a variety of symmetries. Results show that our representations capture the geometry of data and outperform other equivariant representation learning frameworks.
Active Nearest Neighbor Regression Through Delaunay Refinement
Jun 16, 2022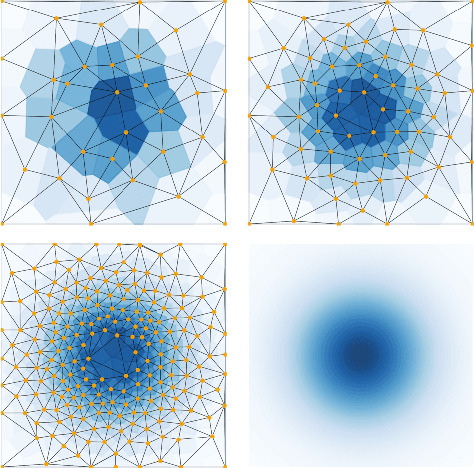
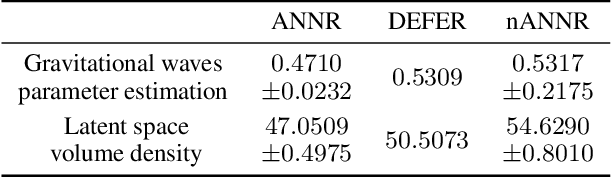
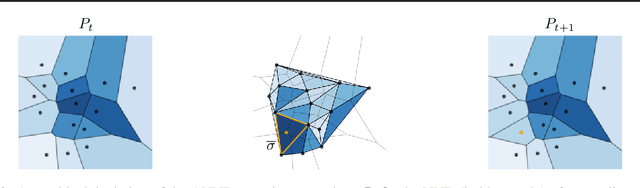

We introduce an algorithm for active function approximation based on nearest neighbor regression. Our Active Nearest Neighbor Regressor (ANNR) relies on the Voronoi-Delaunay framework from computational geometry to subdivide the space into cells with constant estimated function value and select novel query points in a way that takes the geometry of the function graph into account. We consider the recent state-of-the-art active function approximator called DEFER, which is based on incremental rectangular partitioning of the space, as the main baseline. The ANNR addresses a number of limitations that arise from the space subdivision strategy used in DEFER. We provide a computationally efficient implementation of our method, as well as theoretical halting guarantees. Empirical results show that ANNR outperforms the baseline for both closed-form functions and real-world examples, such as gravitational wave parameter inference and exploration of the latent space of a generative model.
Graph-based Task-specific Prediction Models for Interactions between Deformable and Rigid Objects
Mar 04, 2021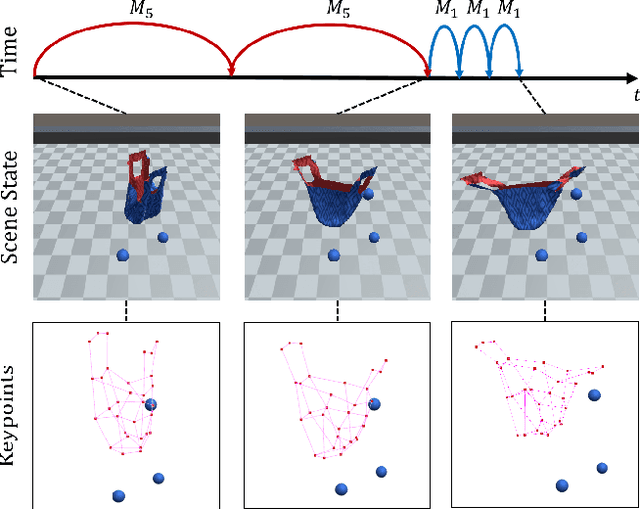
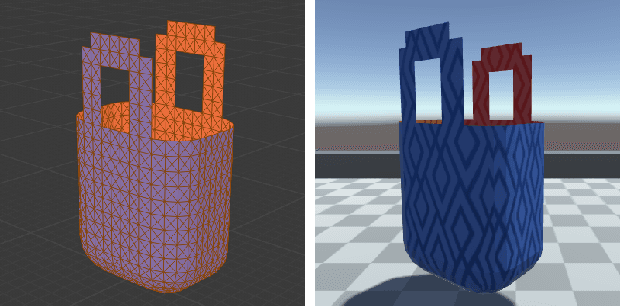

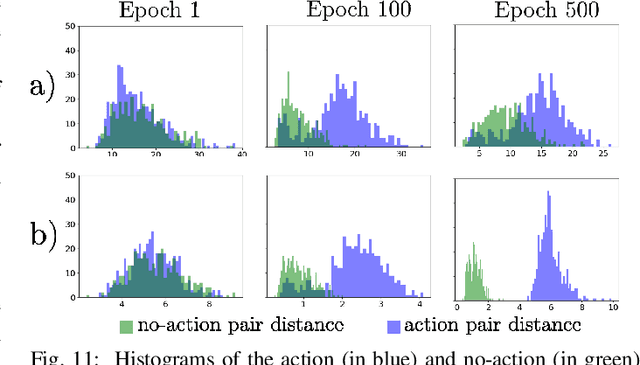
Capturing scene dynamics and predicting the future scene state is challenging but essential for robotic manipulation tasks, especially when the scene contains both rigid and deformable objects. In this work, we contribute a simulation environment and generate a novel dataset for task-specific manipulation, involving interactions between rigid objects and a deformable bag. The dataset incorporates a rich variety of scenarios including different object sizes, object numbers and manipulation actions. We approach dynamics learning by proposing an object-centric graph representation and two modules which are Active Prediction Module (APM) and Position Prediction Module (PPM) based on graph neural networks with an encode-process-decode architecture. At the inference stage, we build a two-stage model based on the learned modules for single time step prediction. We combine modules with different prediction horizons into a mixed-horizon model which addresses long-term prediction. In an ablation study, we show the benefits of the two-stage model for single time step prediction and the effectiveness of the mixed-horizon model for long-term prediction tasks. Supplementary material is available at https://github.com/wengzehang/deformable_rigid_interaction_prediction
Enabling Visual Action Planning for Object Manipulation through Latent Space Roadmap
Mar 03, 2021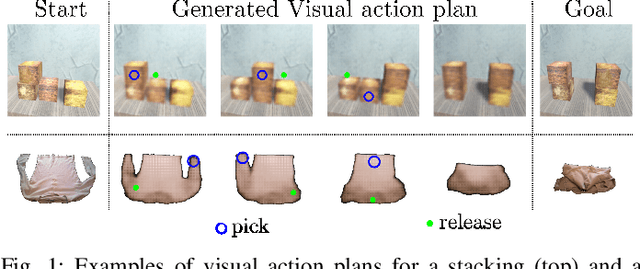


We present a framework for visual action planning of complex manipulation tasks with high-dimensional state spaces, focusing on manipulation of deformable objects. We propose a Latent Space Roadmap (LSR) for task planning, a graph-based structure capturing globally the system dynamics in a low-dimensional latent space. Our framework consists of three parts: (1) a Mapping Module (MM) that maps observations, given in the form of images, into a structured latent space extracting the respective states, that generates observations from the latent states, (2) the LSR which builds and connects clusters containing similar states in order to find the latent plans between start and goal states extracted by MM, and (3) the Action Proposal Module that complements the latent plan found by the LSR with the corresponding actions. We present a thorough investigation of our framework on two simulated box stacking tasks and a folding task executed on a real robot.
Sequential Topological Representations for Predictive Models of Deformable Objects
Nov 23, 2020
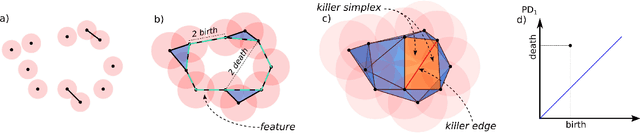

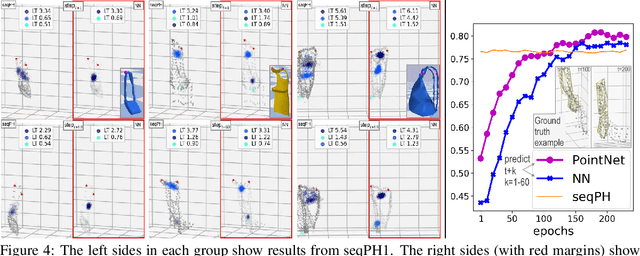
Deformable objects present a formidable challenge for robotic manipulation due to the lack of canonical low-dimensional representations and the difficulty of capturing, predicting, and controlling such objects. We construct compact topological representations to capture the state of highly deformable objects that are topologically nontrivial. We develop an approach that tracks the evolution of this topological state through time. Under several mild assumptions, we prove that the topology of the scene and its evolution can be recovered from point clouds representing the scene. Our further contribution is a method to learn predictive models that take a sequence of past point cloud observations as input and predict a sequence of topological states, conditioned on target/future control actions. Our experiments with highly deformable objects in simulation show that the proposed multistep predictive models yield more precise results than those obtained from computational topology libraries. These models can leverage patterns inferred across various objects and offer fast multistep predictions suitable for real-time applications.
Fashion Landmark Detection and Category Classification for Robotics
Mar 26, 2020

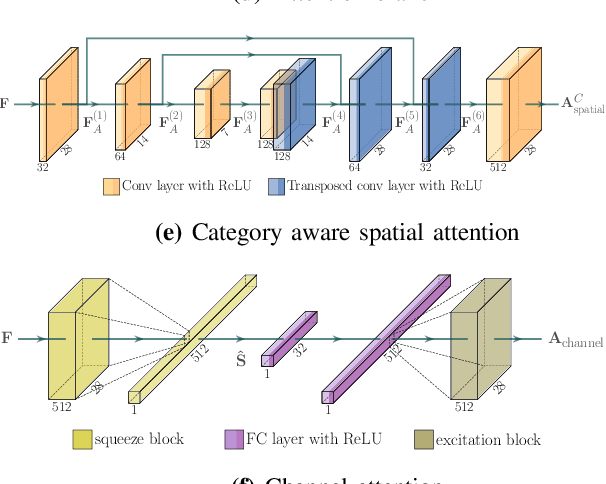
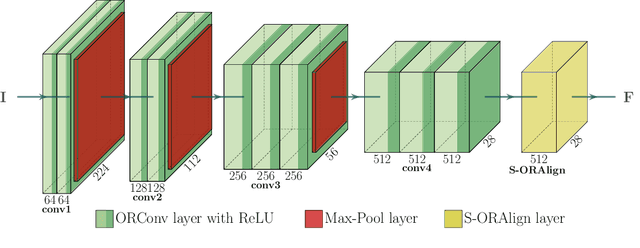
Research on automated, image based identification of clothing categories and fashion landmarks has recently gained significant interest due to its potential impact on areas such as robotic clothing manipulation, automated clothes sorting and recycling, and online shopping. Several public and annotated fashion datasets have been created to facilitate research advances in this direction. In this work, we make the first step towards leveraging the data and techniques developed for fashion image analysis in vision-based robotic clothing manipulation tasks. We focus on techniques that can generalize from large-scale fashion datasets to less structured, small datasets collected in a robotic lab. Specifically, we propose training data augmentation methods such as elastic warping, and model adjustments such as rotation invariant convolutions to make the model generalize better. Our experiments demonstrate that our approach outperforms stateof-the art models with respect to clothing category classification and fashion landmark detection when tested on previously unseen datasets. Furthermore, we present experimental results on a new dataset composed of images where a robot holds different garments, collected in our lab.
Latent Space Roadmap for Visual Action Planning of Deformable and Rigid Object Manipulation
Mar 19, 2020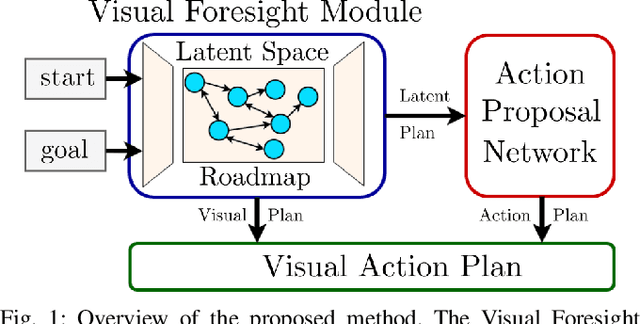
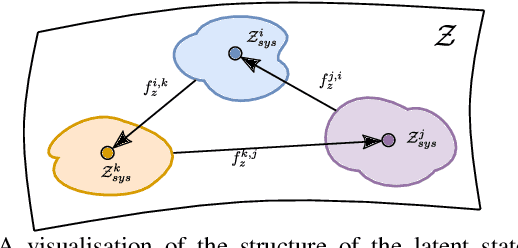
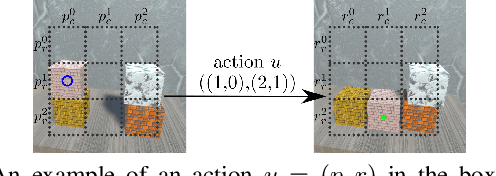
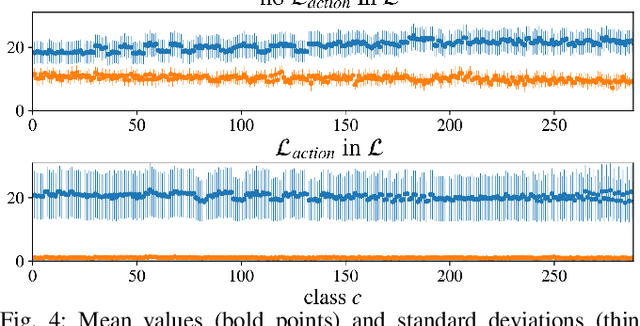
We present a framework for visual action planning of complex manipulation tasks with high-dimensional state spaces such as manipulation of deformable objects. Planning is performed in a low-dimensional latent state space that embeds images. We define and implement a Latent Space Roadmap (LSR) which is a graph-based structure that globally captures the latent system dynamics. Our framework consists of two main components: a Visual Foresight Module (VFM) that generates a visual plan as a sequence of images, and an Action Proposal Network (APN) that predicts the actions between them. We show the effectiveness of the method on a simulated box stacking task as well as a T-shirt folding task performed with a real robot.
Free Space of Rigid Objects: Caging, Path Non-Existence, and Narrow Passage Detection
Feb 07, 2020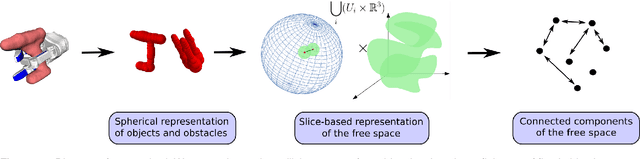
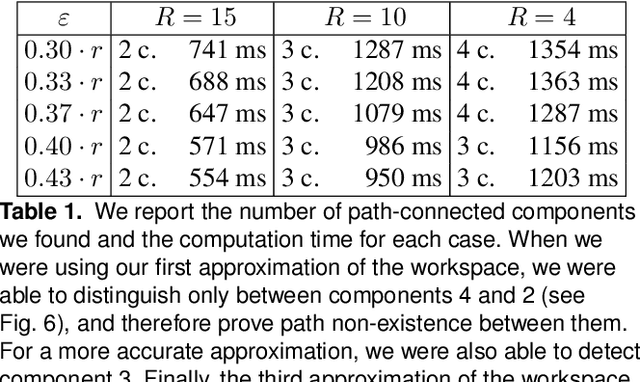
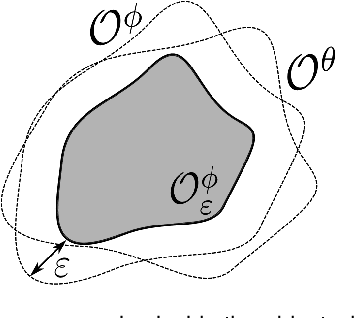

In this work we propose algorithms to explicitly construct a conservative estimate of the configuration spaces of rigid objects in 2D and 3D. Our approach is able to detect compact path components and narrow passages in configuration space which are important for applications in robotic manipulation and path planning. Moreover, as we demonstrate, they are also applicable to identification of molecular cages in chemistry. Our algorithms are based on a decomposition of the resulting 3 and 6 dimensional configuration spaces into slices corresponding to a finite sample of fixed orientations in configuration space. We utilize dual diagrams of unions of balls and uniform grids of orientations to approximate the configuration space. We carry out experiments to evaluate the computational efficiency on a set of objects with different geometric features thus demonstrating that our approach is applicable to different object shapes. We investigate the performance of our algorithm by computing increasingly fine-grained approximations of the object's configuration space.