 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCD -- Line Clustering and Description for Place Recognition
Oct 21, 2020
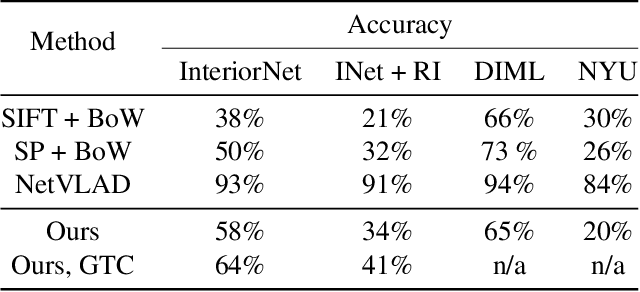
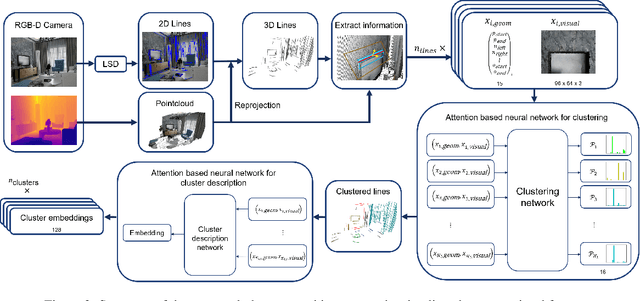
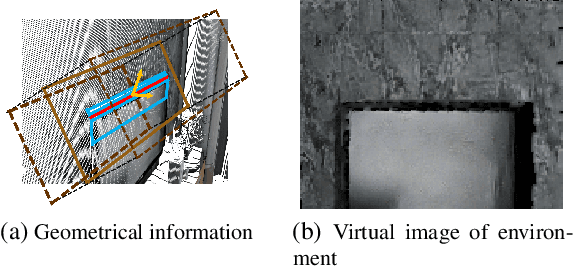
Current research on visual place recognition mostly focuses on aggregating local visual features of an image into a single vector representation. Therefore, high-level information such as the geometric arrangement of the features is typically lost. In this paper, we introduce a novel learning-based approach to place recognition, using RGB-D cameras and line clusters as visual and geometric features. We state the place recognition problem as a problem of recognizing clusters of lines instead of individual patches, thus maintaining structural information. In our work, line clusters are defined as lines that make up individual objects, hence our place recognition approach can be understood as object recognition. 3D line segments are detected in RGB-D images using state-of-the-art techniques. We present a neural network architecture based on the attention mechanism for frame-wise line clustering. A similar neural network is used for the description of these clusters with a compact embedding of 128 floating point numbers, trained with triplet loss on training data obtained from the InteriorNet dataset. We show experiments on a large number of indoor scenes and compare our method with the bag-of-words image-retrieval approach using SIFT and SuperPoint features and the global descriptor NetVLAD. Trained only on synthetic data, our approach generalizes well to real-world data captured with Kinect sensors, while also providing information about the geometric arrangement of instances.
Fashion Landmark Detection and Category Classification for Robotics
Mar 26, 2020

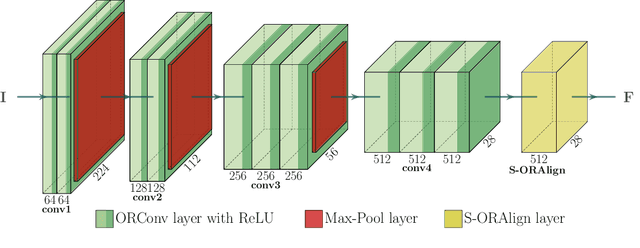
Research on automated, image based identification of clothing categories and fashion landmarks has recently gained significant interest due to its potential impact on areas such as robotic clothing manipulation, automated clothes sorting and recycling, and online shopping. Several public and annotated fashion datasets have been created to facilitate research advances in this direction. In this work, we make the first step towards leveraging the data and techniques developed for fashion image analysis in vision-based robotic clothing manipulation tasks. We focus on techniques that can generalize from large-scale fashion datasets to less structured, small datasets collected in a robotic lab. Specifically, we propose training data augmentation methods such as elastic warping, and model adjustments such as rotation invariant convolutions to make the model generalize better. Our experiments demonstrate that our approach outperforms stateof-the art models with respect to clothing category classification and fashion landmark detection when tested on previously unseen datasets. Furthermore, we present experimental results on a new dataset composed of images where a robot holds different garments, collected in our lab.
Whole-Body Control of a Mobile Manipulator using End-to-End Reinforcement Learning
Feb 25, 2020
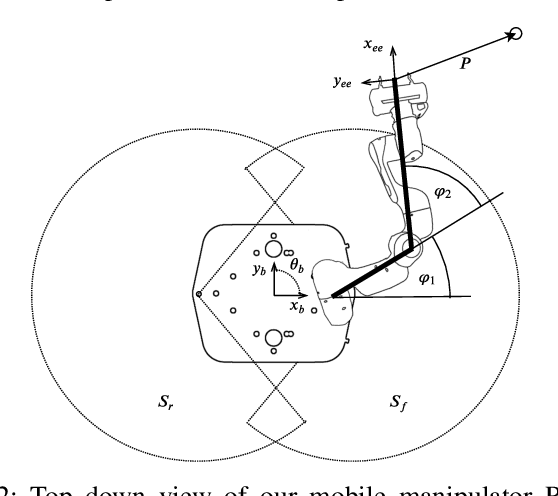
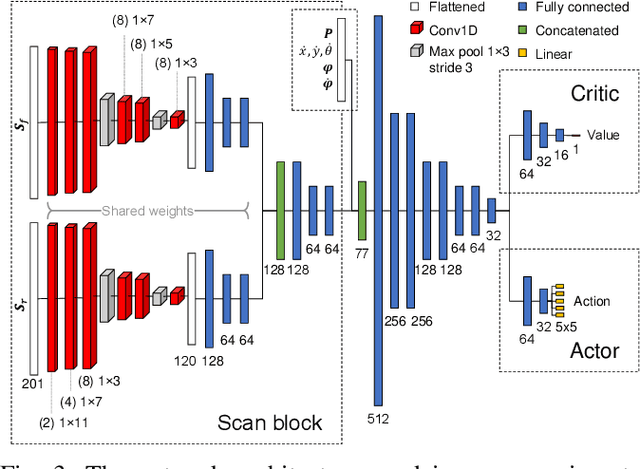

Mobile manipulation is usually achieved by sequentially executing base and manipulator movements. This simplification, however, leads to a loss in efficiency and in some cases a reduction of workspace size. Even though different methods have been proposed to solve Whole-Body Control (WBC) online, they are either limited by a kinematic model or do not allow for reactive, online obstacle avoidance. In order to overcome these drawbacks, in this work, we propose an end-to-end Reinforcement Learning (RL) approach to WBC. We compared our learned controller against a state-of-the-art sampling-based method in simulation and achieved faster overall mission times. In addition, we validated the learned policy on our mobile manipulator RoyalPanda in challenging narrow corridor environments.
VersaVIS: An Open Versatile Multi-Camera Visual-Inertial Sensor Suite
Dec 05, 2019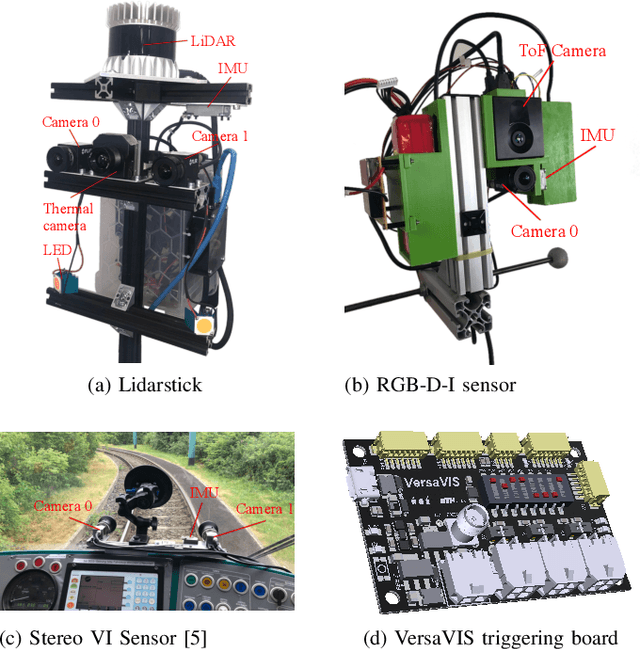
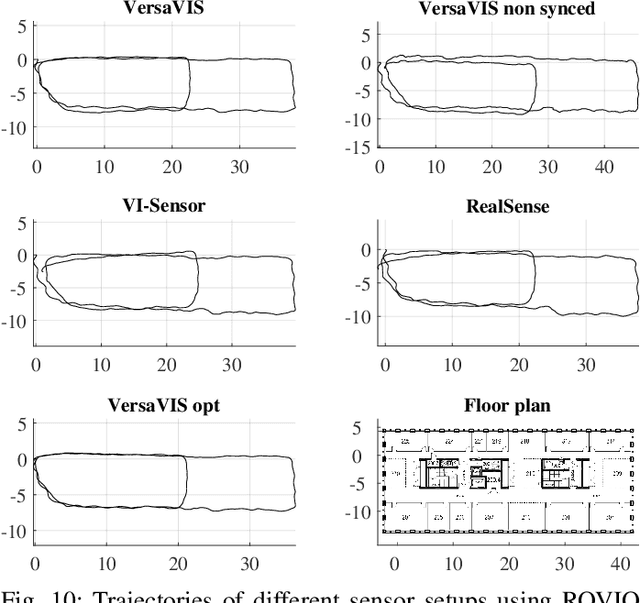
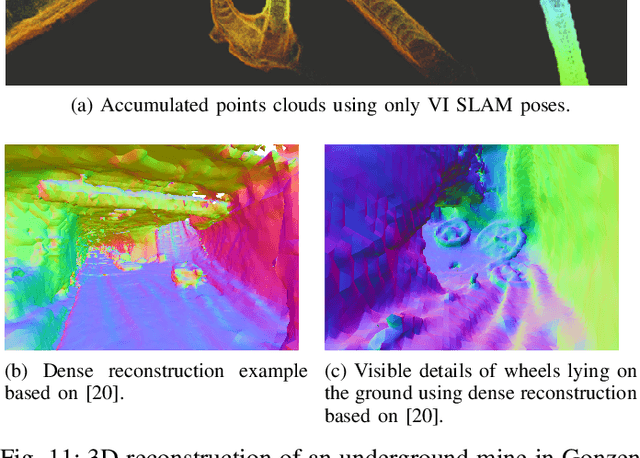
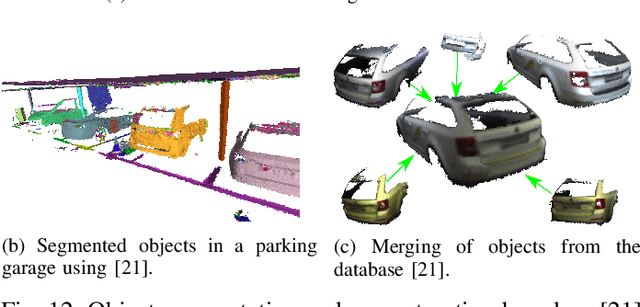
Robust and accurate pose estimation is crucial for many applications in mobile robotics. Extending visual Simultaneous Localization and Mapping (SLAM) with other modalities such as an inertial measurement unit (IMU) can boost robustness and accuracy. However, for a tight sensor fusion, accurate time synchronization of the sensors is often crucial. Changing exposure times, internal sensor filtering, multiple clock sources and unpredictable delays from operation system scheduling and data transfer can make sensor synchronization challenging. In this paper, we present VersaVIS, an Open Versatile Multi-Camera Visual-Inertial Sensor Suite aimed to be an efficient research platform for easy deployment, integration and extension for many mobile robotic applications. VersaVIS provides a complete, open-source hardware, firmware and software bundle to perform time synchronization of multiple cameras with an IMU featuring exposure compensation, host clock translation and independent and stereo camera triggering. The sensor suite supports a wide range of cameras and IMUs to match the requirements of the application. The synchronization accuracy of the framework is evaluated on multiple experiments achieving timing accuracy of less than 1 ms. Furthermore, the applicability and versatility of the sensor suite is demonstrated in multiple applications including visual-inertial SLAM, multi-camera applications, multimodal mapping, reconstruction and object based mapping.
Object Finding in Cluttered Scenes Using Interactive Perception
Nov 18, 2019
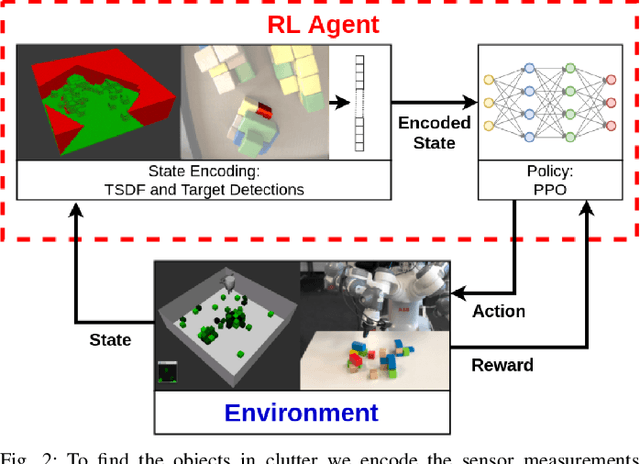
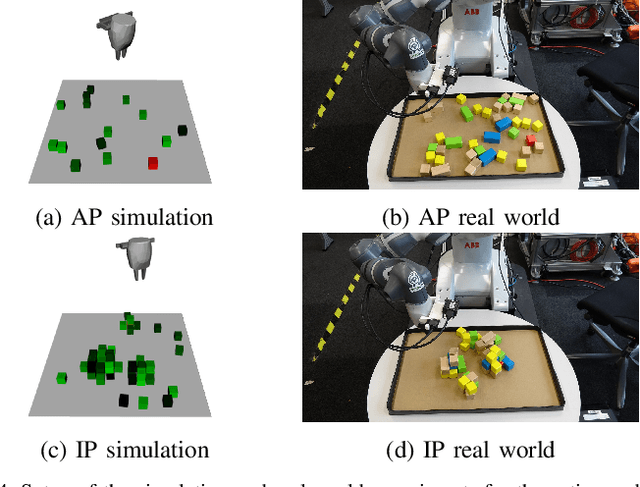
Object finding in clutter is a skill that requires both perception of the environment and in many cases physical interaction. In robotics, interactive perception defines a set of algorithms that leverage actions to improve the perception of the environment, and vice versa use perception to guide the next action. Scene interactions are difficult to model, therefore, most of the current systems use predefined heuristics. This limits their ability to efficiently search for the target object in a complex environment. In order to remove heuristics and the need for explicit models of the interactions, in this work we propose a reinforcement learning based active and interactive perception system for scene exploration and object search. We evaluate our work both in simulated and in real world experiments using a robotic manipulator equipped with an RGB and a depth camera, and compared our system to two baselines. The results indicate that our approach, trained in simulation only, transfers smoothly to reality and can solve the object finding task efficiently and with more than 90% success rate.
Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery
Mar 01, 2019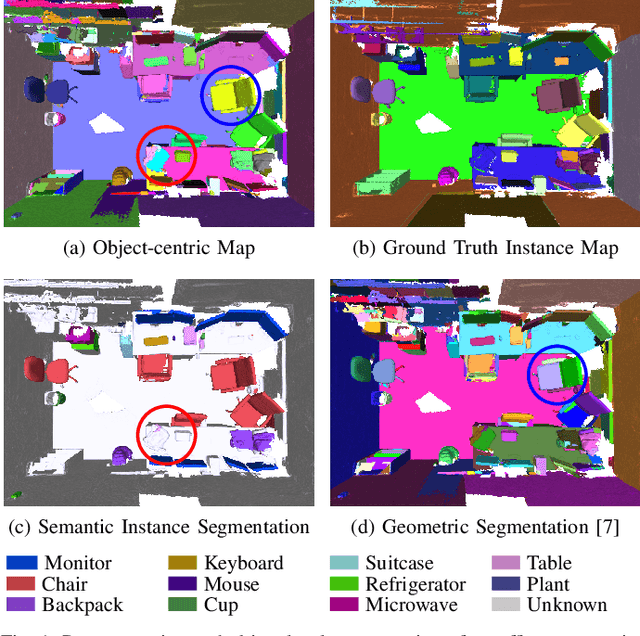
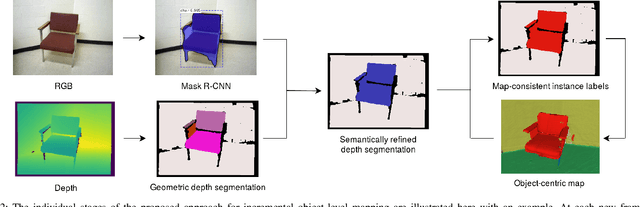


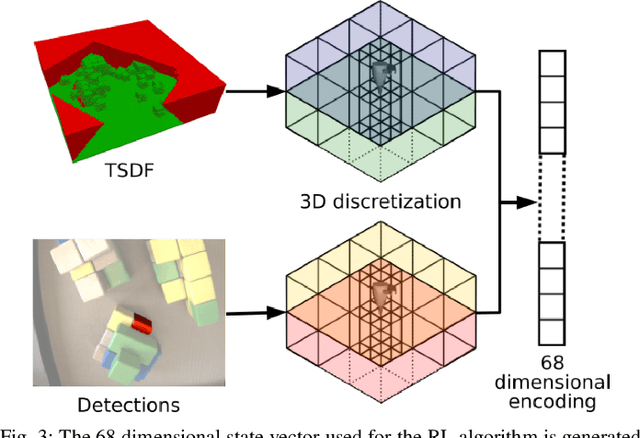
To autonomously navigate and plan interactions in real-world environments, robots require the ability to robustly perceive and map complex, unstructured surrounding scenes. Besides building an internal representation of the observed scene geometry, the key insight towards a truly functional understanding of the environment is the usage of higher-level entities during mapping, such as individual object instances. We propose an approach to incrementally build volumetric object-centric maps during online scanning with a localized RGB-D camera. First, a per-frame segmentation scheme combines an unsupervised geometric approach with instance-aware semantic object predictions. This allows us to detect and segment elements both from the set of known classes and from other, previously unseen categories. Next, a data association step tracks the predicted instances across the different frames. Finally, a map integration strategy fuses information about their 3D shape, location, and, if available, semantic class into a global volume. Evaluation on a publicly available dataset shows that the proposed approach for building instance-level semantic maps is competitive with state-of-the-art methods, while additionally able to discover objects of unseen categories. The system is further evaluated within a real-world robotic mapping setup, for which qualitative results highlight the online nature of the method.
Comparing Task Simplifications to Learn Closed-Loop Object Picking Using Deep Reinforcement Learning
Jan 31, 2019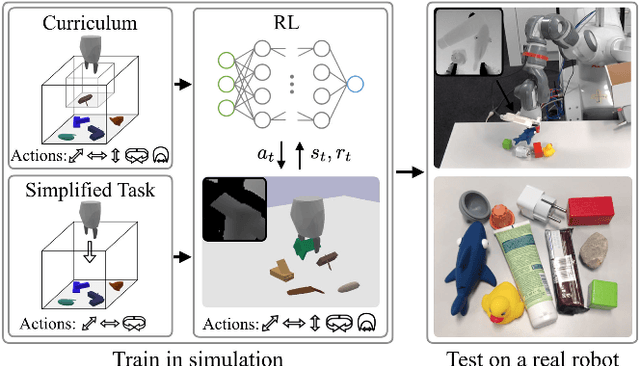
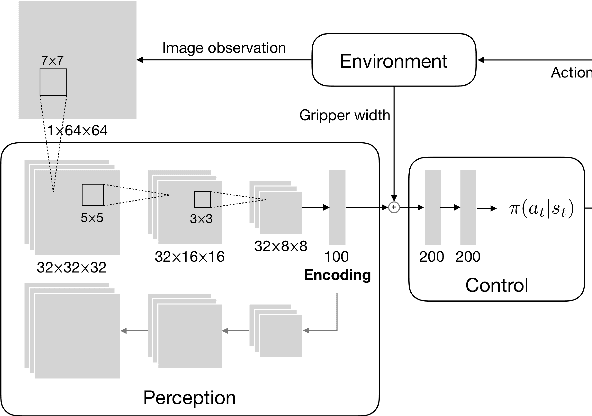

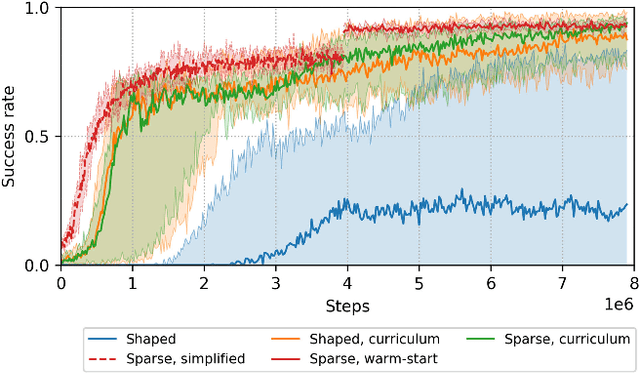
Enabling autonomous robots to interact in unstructured environments with dynamic objects requires manipulation capabilities that can deal with clutter, changes, and objects' variability. This paper presents a comparison of different reinforcement learning-based approaches for object picking with a robotic manipulator. We learn closed-loop policies mapping depth camera inputs to motion commands and compare different approaches to keep the problem tractable, including reward shaping, curriculum learning and using a policy pre-trained on a task with a reduced action set to warm-start the full problem. For efficient and more flexible data collection, we train in simulation and transfer the policies to a real robot. We show that using curriculum learning, policies learned with a sparse reward formulation can be trained at similar rates as with a shaped reward. These policies result in success rates comparable to the policy initialized on the simplified task. We could successfully transfer these policies to the real robot with only minor modifications of the depth image filtering. We found that using a heuristic to warm-start the training was useful to enforce desired behavior, while the policies trained from scratch using a curriculum learned better to cope with unseen scenarios where objects are removed.
Incremental Object Database: Building 3D Models from Multiple Partial Observations
Aug 02, 2018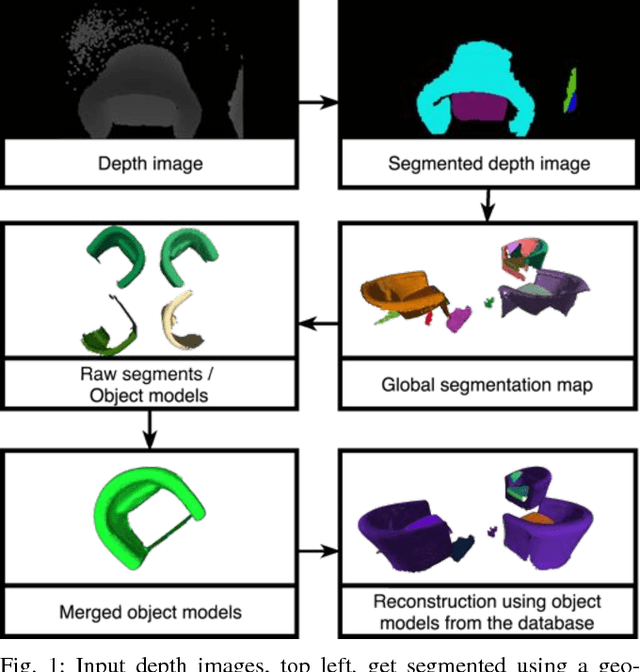

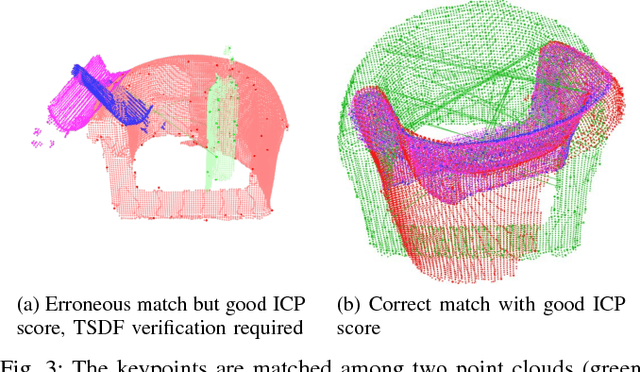
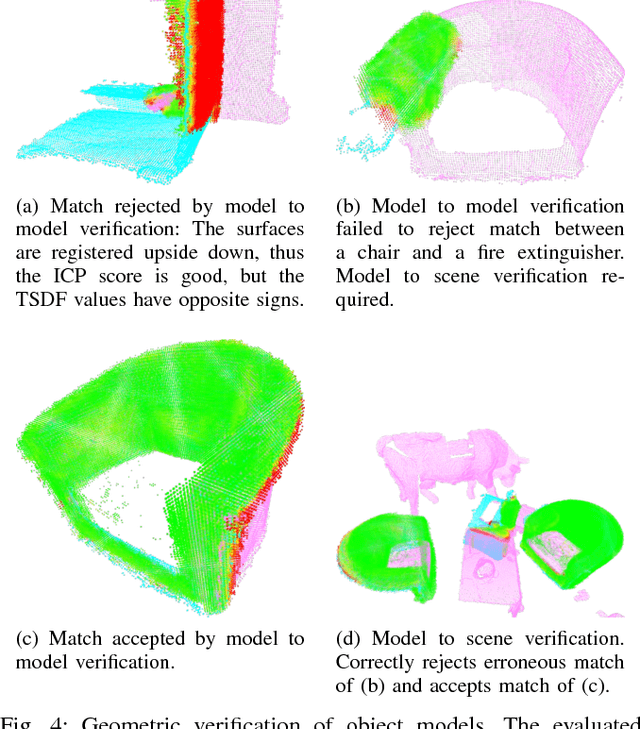
Collecting 3D object datasets involves a large amount of manual work and is time consuming. Getting complete models of objects either requires a 3D scanner that covers all the surfaces of an object or one needs to rotate it to completely observe it. We present a system that incrementally builds a database of objects as a mobile agent traverses a scene. Our approach requires no prior knowledge of the shapes present in the scene. Object-like segments are extracted from a global segmentation map, which is built online using the input of segmented RGB-D images. These segments are stored in a database, matched among each other, and merged with other previously observed instances. This allows us to create and improve object models on the fly and to use these merged models to reconstruct also unobserved parts of the scene. The database contains each (potentially merged) object model only once, together with a set of poses where it was observed. We evaluate our pipeline with one public dataset, and on a newly created Google Tango dataset containing four indoor scenes with some of the objects appearing multiple times, both within and across scenes.
Aerial Picking and Delivery of Magnetic Objects with MAVs
Dec 08, 2016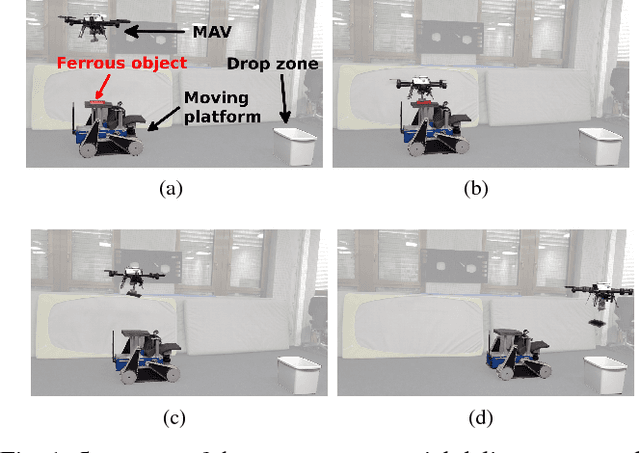
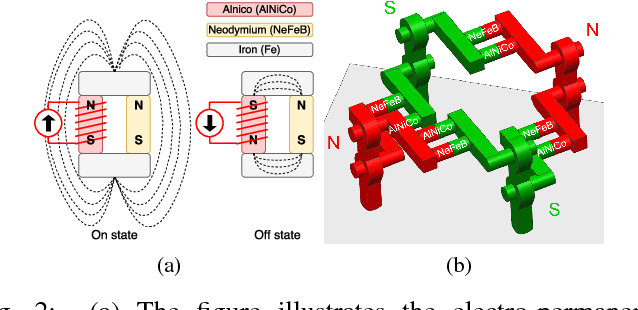
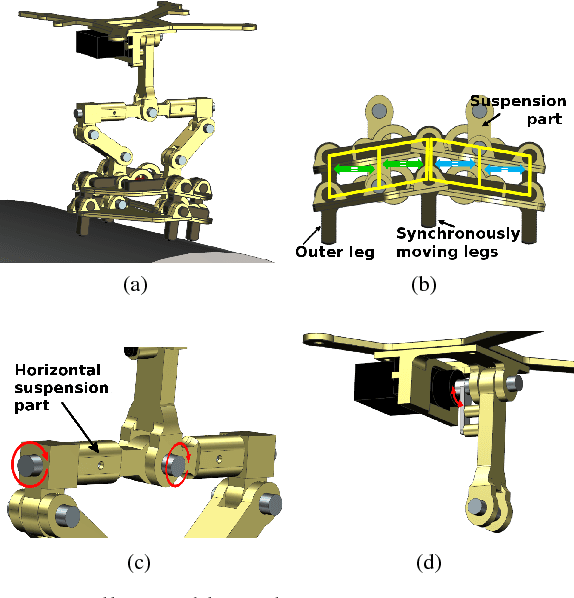
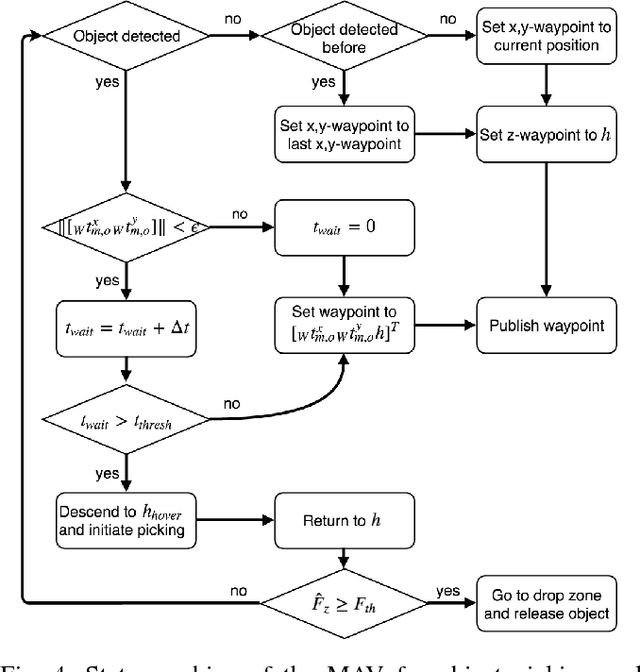
Autonomous delivery of goods using a MAV is a difficult problem, as it poses high demand on the MAV's control, perception and manipulation capabilities. This problem is especially challenging if the exact shape, location and configuration of the objects are unknown. In this paper, we report our findings during the development and evaluation of a fully integrated system that is energy efficient and enables MAVs to pick up and deliver objects with partly ferrous surface of varying shapes and weights. This is achieved by using a novel combination of an electro-permanent magnetic gripper with a passively compliant structure and integration with detection, control and servo positioning algorithms. The system's ability to grasp stationary and moving objects was tested, as well as its ability to cope with different shapes of the object and external disturbances. We show that such a system can be successfully deployed in scenarios where an object with partly ferrous parts needs to be gripped and placed in a predetermined location.