 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSDF++: A Multi-Object Formulation for Dynamic Object Tracking and Reconstruction
May 16, 2021
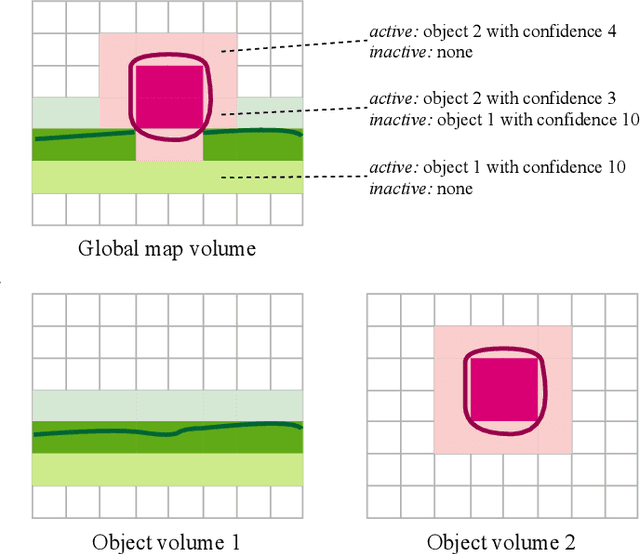

The ability to simultaneously track and reconstruct multiple objects moving in the scene is of the utmost importance for robotic tasks such as autonomous navigation and interaction. Virtually all of the previous attempts to map multiple dynamic objects have evolved to store individual objects in separate reconstruction volumes and track the relative pose between them. While simple and intuitive, such formulation does not scale well with respect to the number of objects in the scene and introduces the need for an explicit occlusion handling strategy. In contrast, we propose a map representation that allows maintaining a single volume for the entire scene and all the objects therein. To this end, we introduce a novel multi-object TSDF formulation that can encode multiple object surfaces at any given location in the map. In a multiple dynamic object tracking and reconstruction scenario, our representation allows maintaining accurate reconstruction of surfaces even while they become temporarily occluded by other objects moving in their proximity. We evaluate the proposed TSDF++ formulation on a public synthetic dataset and demonstrate its ability to preserve reconstructions of occluded surfaces when compared to the standard TSDF map representation.
3DSNet: Unsupervised Shape-to-Shape 3D Style Transfer
Nov 30, 2020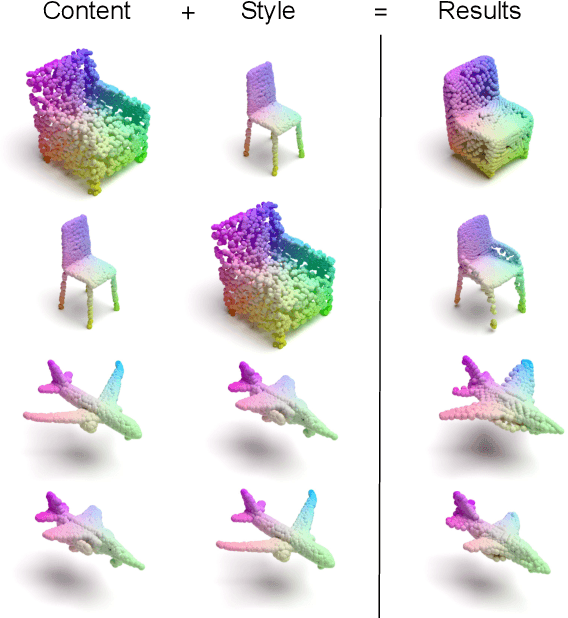

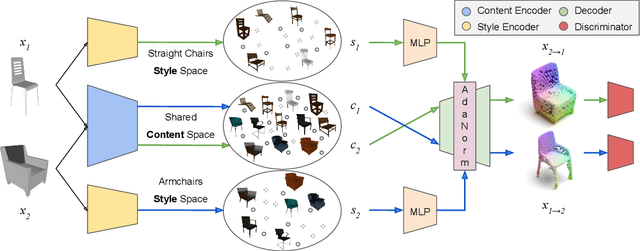

Transferring the style from one image onto another is a popular and widely studied task in computer vision. Yet, learning-based style transfer in the 3D setting remains a largely unexplored problem. To our knowledge, we propose the first learning-based generative approach for style transfer between 3D objects. Our method allows to combine the content and style of a source and target 3D model to generate a novel shape that resembles in style the target while retaining the source content. The proposed framework can synthesize new 3D shapes both in the form of point clouds and meshes. Furthermore, we extend our technique to implicitly learn the underlying multimodal style distribution of the individual category domains. By sampling style codes from the learned distributions, we increase the variety of styles that our model can confer to a given reference object. Experimental results validate the effectiveness of the proposed 3D style transfer method on a number of benchmarks.
Go Fetch: Mobile Manipulation in Unstructured Environments
Apr 02, 2020
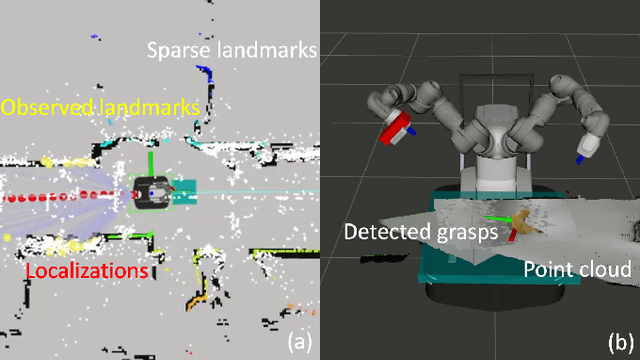
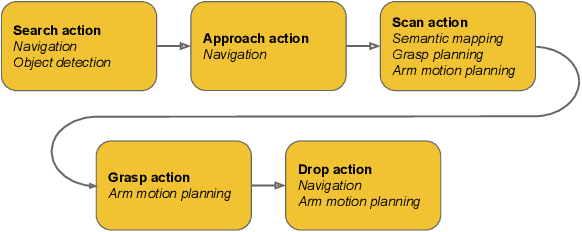
With humankind facing new and increasingly large-scale challenges in the medical and domestic spheres, automation of the service sector carries a tremendous potential for improved efficiency, quality, and safety of operations. Mobile robotics can offer solutions with a high degree of mobility and dexterity, however these complex systems require a multitude of heterogeneous components to be carefully integrated into one consistent framework. This work presents a mobile manipulation system that combines perception, localization, navigation, motion planning and grasping skills into one common workflow for fetch and carry applications in unstructured indoor environments. The tight integration across the various modules is experimentally demonstrated on the task of finding a commonly available object in an office environment, grasping it, and delivering it to a desired drop-off location. The accompanying video is available at https://youtu.be/e89_Xg1sLnY.
Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery
Mar 01, 2019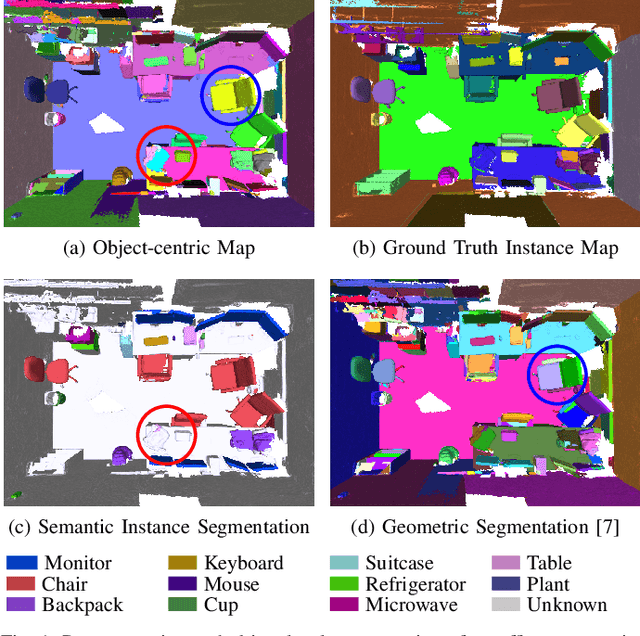
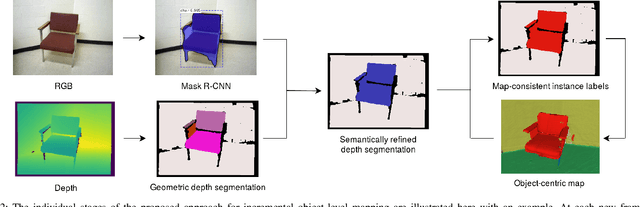


To autonomously navigate and plan interactions in real-world environments, robots require the ability to robustly perceive and map complex, unstructured surrounding scenes. Besides building an internal representation of the observed scene geometry, the key insight towards a truly functional understanding of the environment is the usage of higher-level entities during mapping, such as individual object instances. We propose an approach to incrementally build volumetric object-centric maps during online scanning with a localized RGB-D camera. First, a per-frame segmentation scheme combines an unsupervised geometric approach with instance-aware semantic object predictions. This allows us to detect and segment elements both from the set of known classes and from other, previously unseen categories. Next, a data association step tracks the predicted instances across the different frames. Finally, a map integration strategy fuses information about their 3D shape, location, and, if available, semantic class into a global volume. Evaluation on a publicly available dataset shows that the proposed approach for building instance-level semantic maps is competitive with state-of-the-art methods, while additionally able to discover objects of unseen categories. The system is further evaluated within a real-world robotic mapping setup, for which qualitative results highlight the online nature of the method.
Incremental Object Database: Building 3D Models from Multiple Partial Observations
Aug 02, 2018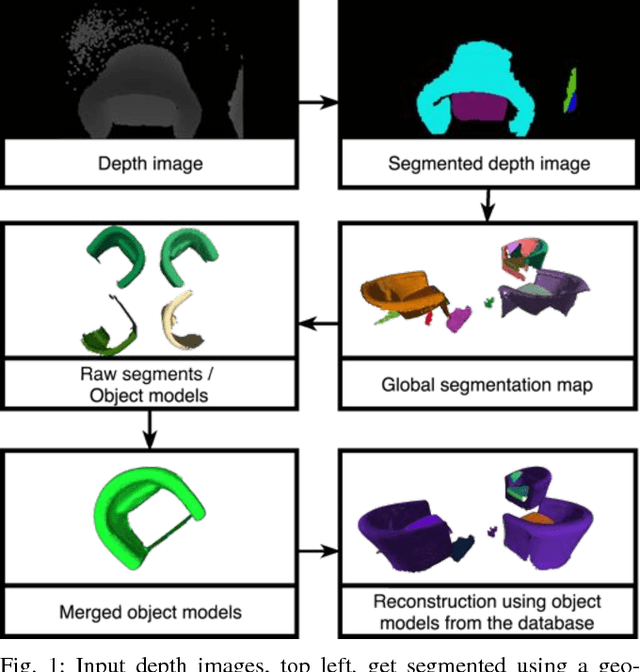

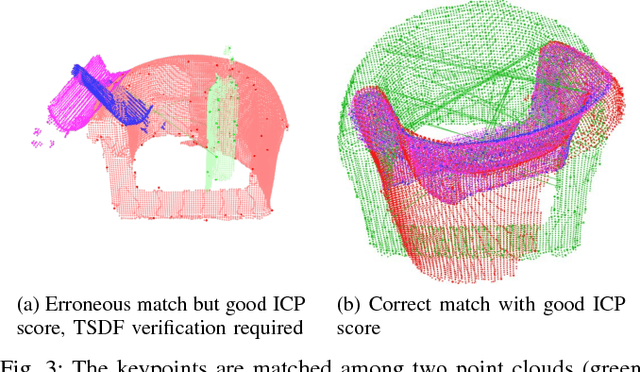
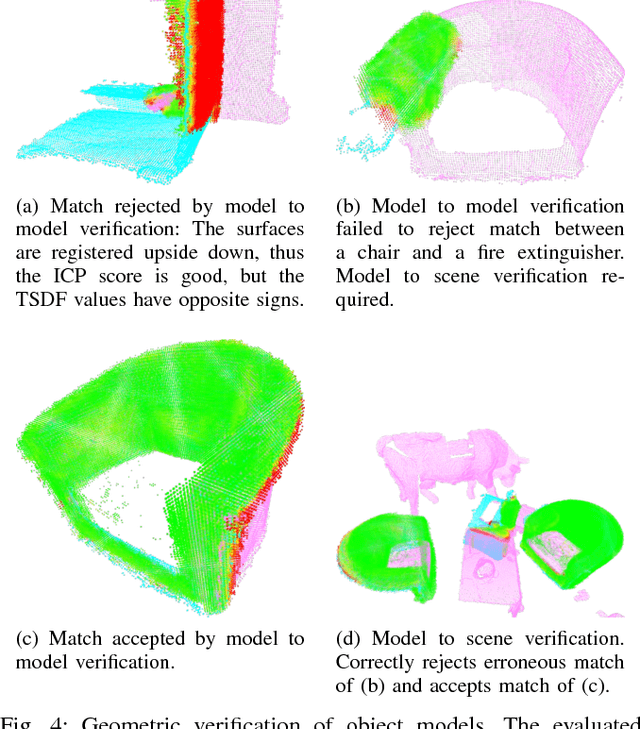
Collecting 3D object datasets involves a large amount of manual work and is time consuming. Getting complete models of objects either requires a 3D scanner that covers all the surfaces of an object or one needs to rotate it to completely observe it. We present a system that incrementally builds a database of objects as a mobile agent traverses a scene. Our approach requires no prior knowledge of the shapes present in the scene. Object-like segments are extracted from a global segmentation map, which is built online using the input of segmented RGB-D images. These segments are stored in a database, matched among each other, and merged with other previously observed instances. This allows us to create and improve object models on the fly and to use these merged models to reconstruct also unobserved parts of the scene. The database contains each (potentially merged) object model only once, together with a set of poses where it was observed. We evaluate our pipeline with one public dataset, and on a newly created Google Tango dataset containing four indoor scenes with some of the objects appearing multiple times, both within and across scenes.