 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-Loop Next-Best-View Planning for Target-Driven Grasping
Jul 21, 2022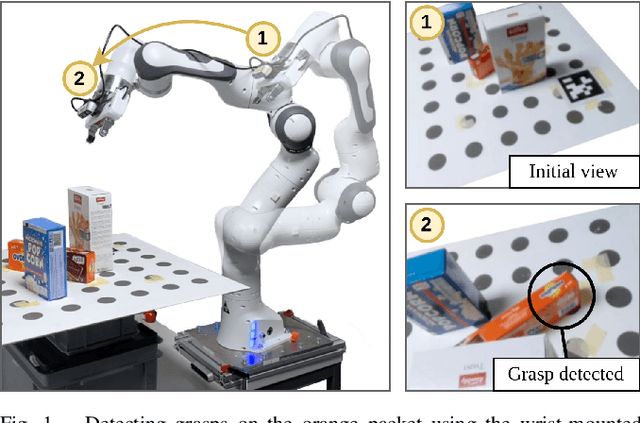
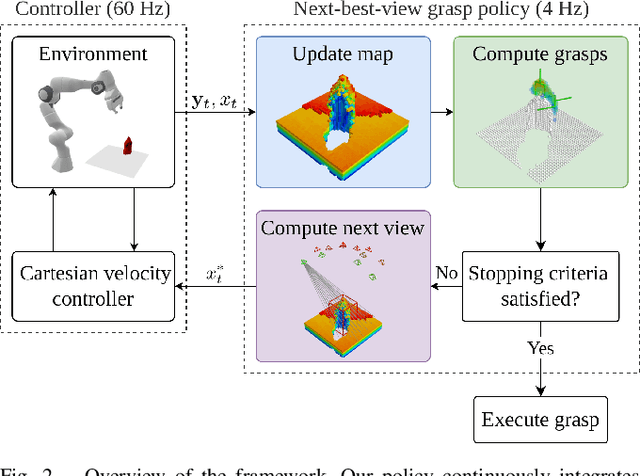
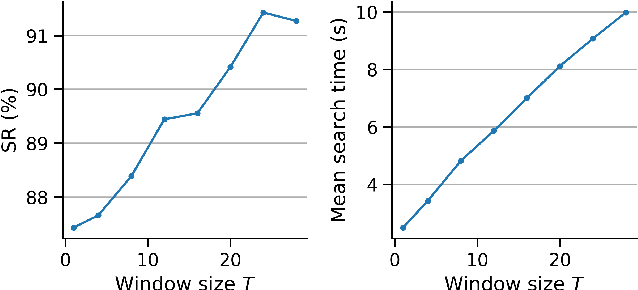

Picking a specific object from clutter is an essential component of many manipulation tasks. Partial observations often require the robot to collect additional views of the scene before attempting a grasp. This paper proposes a closed-loop next-best-view planner that drives exploration based on occluded object parts. By continuously predicting grasps from an up-to-date scene reconstruction, our policy can decide online to finalize a grasp execution or to adapt the robot's trajectory for further exploration. We show that our reactive approach decreases execution times without loss of grasp success rates compared to common camera placements and handles situations where the fixed baselines fail. Video and code are available at https://github.com/ethz-asl/active_grasp.
Unified Data Collection for Visual-Inertial Calibration via Deep Reinforcement Learning
Sep 30, 2021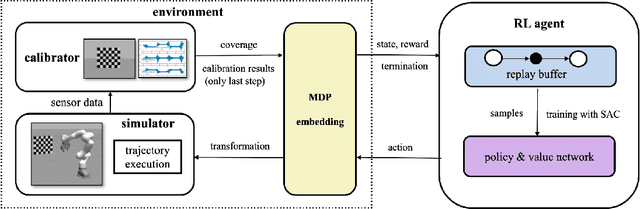
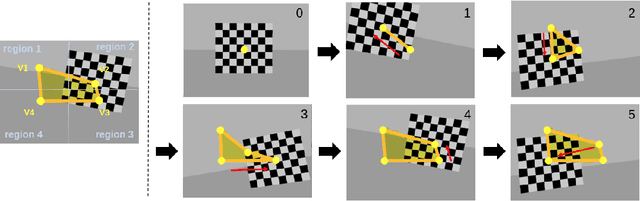

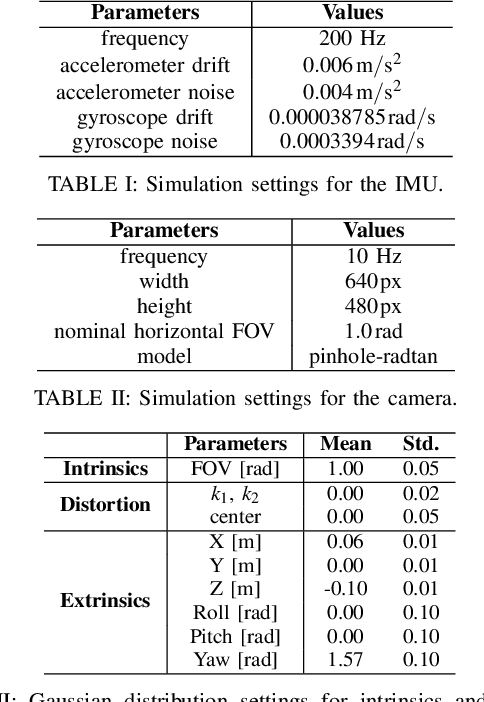
Visual-inertial sensors have a wide range of applications in robotics. However, good performance often requires different sophisticated motion routines to accurately calibrate camera intrinsics and inter-sensor extrinsics. This work presents a novel formulation to learn a motion policy to be executed on a robot arm for automatic data collection for calibrating intrinsics and extrinsics jointly. Our approach models the calibration process compactly using model-free deep reinforcement learning to derive a policy that guides the motions of a robotic arm holding the sensor to efficiently collect measurements that can be used for both camera intrinsic calibration and camera-IMU extrinsic calibration. Given the current pose and collected measurements, the learned policy generates the subsequent transformation that optimizes sensor calibration accuracy. The evaluations in simulation and on a real robotic system show that our learned policy generates favorable motion trajectories and collects enough measurements efficiently that yield the desired intrinsics and extrinsics with short path lengths. In simulation we are able to perform calibrations 10 times faster than hand-crafted policies, which transfers to a real-world speed up of 3 times over a human expert.
Volumetric Grasping Network: Real-time 6 DOF Grasp Detection in Clutter
Jan 04, 2021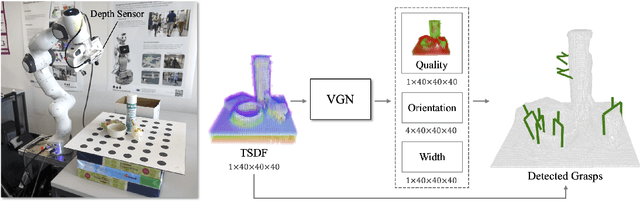
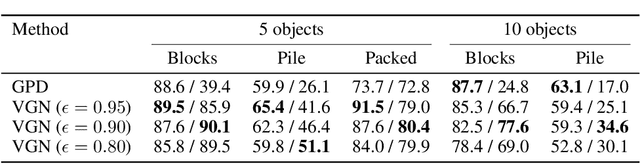
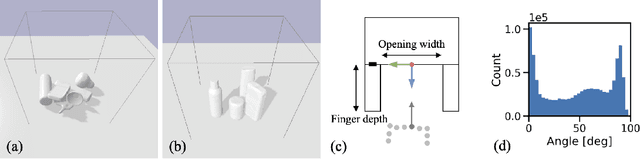

General robot grasping in clutter requires the ability to synthesize grasps that work for previously unseen objects and that are also robust to physical interactions, such as collisions with other objects in the scene. In this work, we design and train a network that predicts 6 DOF grasps from 3D scene information gathered from an on-board sensor such as a wrist-mounted depth camera. Our proposed Volumetric Grasping Network (VGN) accepts a Truncated Signed Distance Function (TSDF) representation of the scene and directly outputs the predicted grasp quality and the associated gripper orientation and opening width for each voxel in the queried 3D volume. We show that our approach can plan grasps in only 10 ms and is able to clear 92% of the objects in real-world clutter removal experiments without the need for explicit collision checking. The real-time capability opens up the possibility for closed-loop grasp planning, allowing robots to handle disturbances, recover from errors and provide increased robustness. Code is available at https://github.com/ethz-asl/vgn.
Learning Trajectories for Visual-Inertial System Calibration via Model-based Heuristic Deep Reinforcement Learning
Nov 04, 2020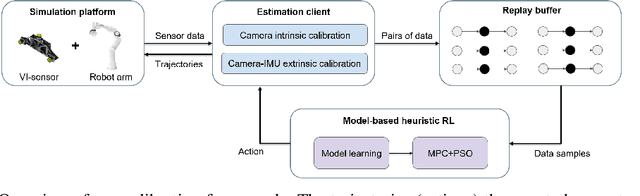

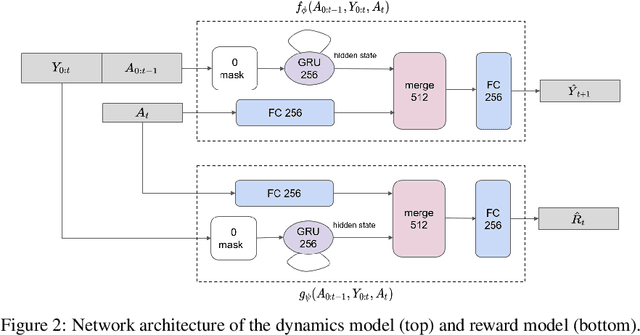
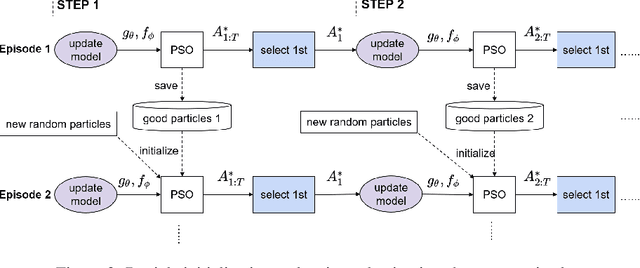
Visual-inertial systems rely on precise calibrations of both camera intrinsics and inter-sensor extrinsics, which typically require manually performing complex motions in front of a calibration target. In this work we present a novel approach to obtain favorable trajectories for visual-inertial system calibration, using model-based deep reinforcement learning. Our key contribution is to model the calibration process as a Markov decision process and then use model-based deep reinforcement learning with particle swarm optimization to establish a sequence of calibration trajectories to be performed by a robot arm. Our experiments show that while maintaining similar or shorter path lengths, the trajectories generated by our learned policy result in lower calibration errors compared to random or handcrafted trajectories.
Go Fetch: Mobile Manipulation in Unstructured Environments
Apr 02, 2020
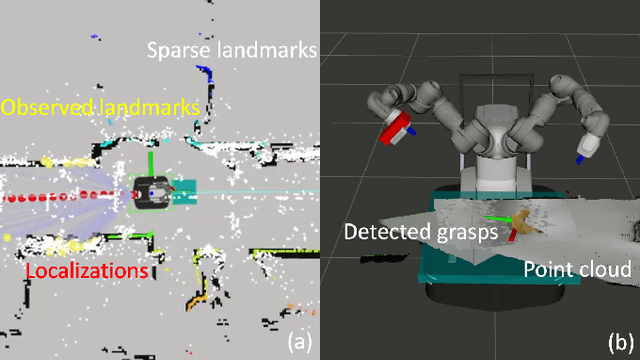
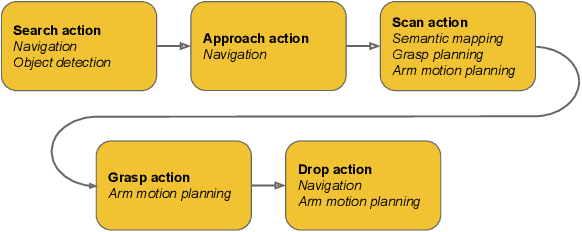
With humankind facing new and increasingly large-scale challenges in the medical and domestic spheres, automation of the service sector carries a tremendous potential for improved efficiency, quality, and safety of operations. Mobile robotics can offer solutions with a high degree of mobility and dexterity, however these complex systems require a multitude of heterogeneous components to be carefully integrated into one consistent framework. This work presents a mobile manipulation system that combines perception, localization, navigation, motion planning and grasping skills into one common workflow for fetch and carry applications in unstructured indoor environments. The tight integration across the various modules is experimentally demonstrated on the task of finding a commonly available object in an office environment, grasping it, and delivering it to a desired drop-off location. The accompanying video is available at https://youtu.be/e89_Xg1sLnY.
Object Finding in Cluttered Scenes Using Interactive Perception
Nov 18, 2019
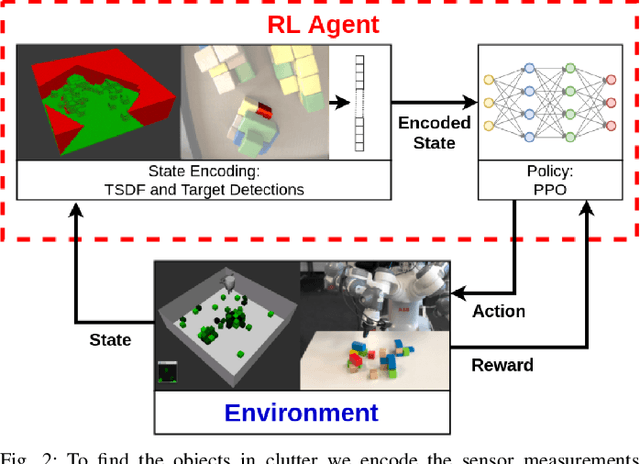
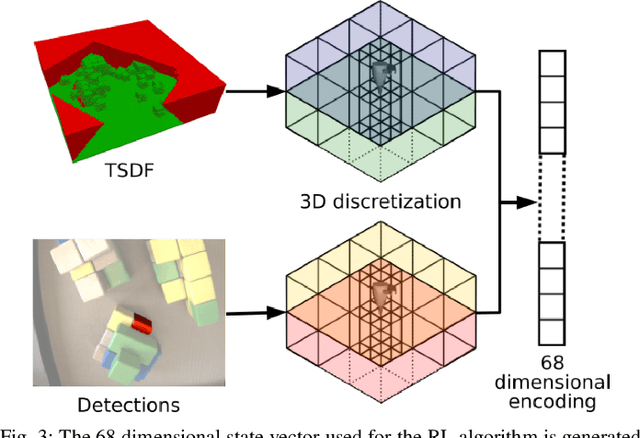
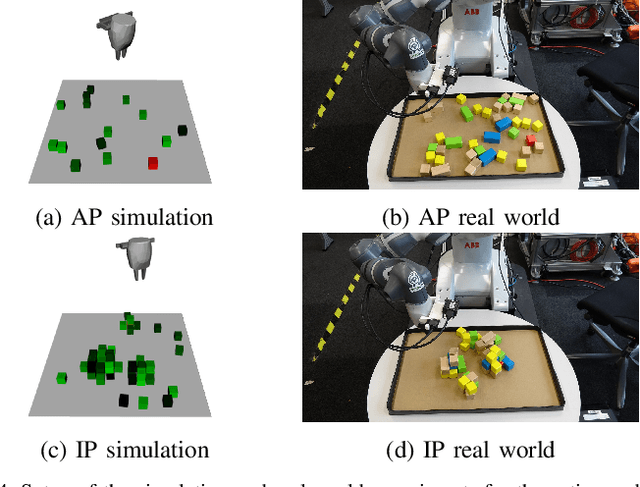
Object finding in clutter is a skill that requires both perception of the environment and in many cases physical interaction. In robotics, interactive perception defines a set of algorithms that leverage actions to improve the perception of the environment, and vice versa use perception to guide the next action. Scene interactions are difficult to model, therefore, most of the current systems use predefined heuristics. This limits their ability to efficiently search for the target object in a complex environment. In order to remove heuristics and the need for explicit models of the interactions, in this work we propose a reinforcement learning based active and interactive perception system for scene exploration and object search. We evaluate our work both in simulated and in real world experiments using a robotic manipulator equipped with an RGB and a depth camera, and compared our system to two baselines. The results indicate that our approach, trained in simulation only, transfers smoothly to reality and can solve the object finding task efficiently and with more than 90% success rate.
Comparing Task Simplifications to Learn Closed-Loop Object Picking Using Deep Reinforcement Learning
Jan 31, 2019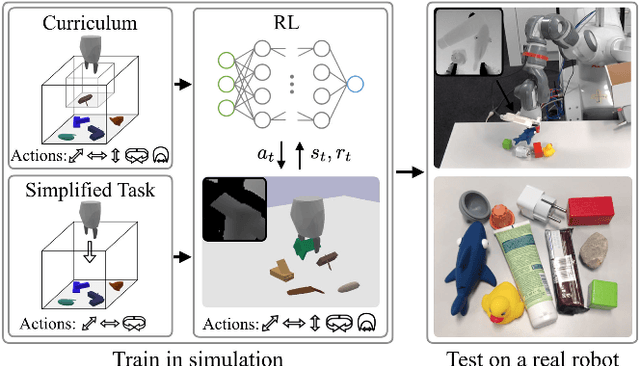
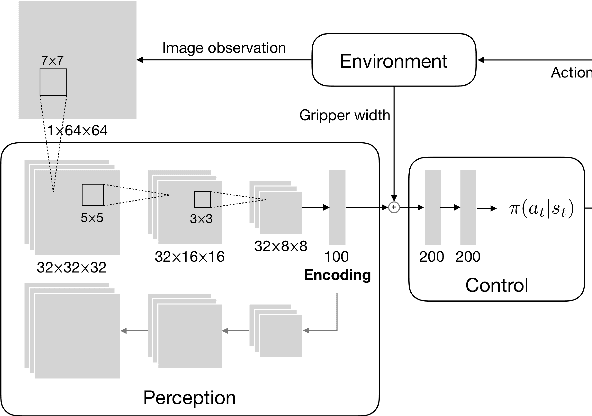

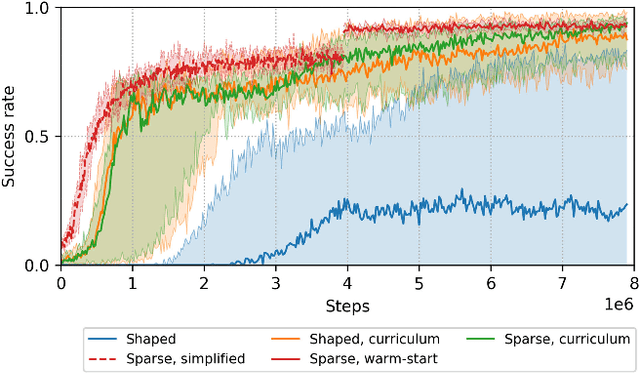
Enabling autonomous robots to interact in unstructured environments with dynamic objects requires manipulation capabilities that can deal with clutter, changes, and objects' variability. This paper presents a comparison of different reinforcement learning-based approaches for object picking with a robotic manipulator. We learn closed-loop policies mapping depth camera inputs to motion commands and compare different approaches to keep the problem tractable, including reward shaping, curriculum learning and using a policy pre-trained on a task with a reduced action set to warm-start the full problem. For efficient and more flexible data collection, we train in simulation and transfer the policies to a real robot. We show that using curriculum learning, policies learned with a sparse reward formulation can be trained at similar rates as with a shaped reward. These policies result in success rates comparable to the policy initialized on the simplified task. We could successfully transfer these policies to the real robot with only minor modifications of the depth image filtering. We found that using a heuristic to warm-start the training was useful to enforce desired behavior, while the policies trained from scratch using a curriculum learned better to cope with unseen scenarios where objects are removed.