 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralBoneReg: A Novel Self-Supervised Method for Robust and Accurate Multi-Modal Bone Surface Registration
Nov 18, 2025In computer- and robot-assisted orthopedic surgery (CAOS), patient-specific surgical plans derived from preoperative imaging define target locations and implant trajectories. During surgery, these plans must be accurately transferred, relying on precise cross-registration between preoperative and intraoperative data. However, substantial modality heterogeneity across imaging modalities makes this registration challenging and error-prone. Robust, automatic, and modality-agnostic bone surface registration is therefore clinically important. We propose NeuralBoneReg, a self-supervised, surface-based framework that registers bone surfaces using 3D point clouds as a modality-agnostic representation. NeuralBoneReg includes two modules: an implicit neural unsigned distance field (UDF) that learns the preoperative bone model, and an MLP-based registration module that performs global initialization and local refinement by generating transformation hypotheses to align the intraoperative point cloud with the neural UDF. Unlike SOTA supervised methods, NeuralBoneReg operates in a self-supervised manner, without requiring inter-subject training data. We evaluated NeuralBoneReg against baseline methods on two publicly available multi-modal datasets: a CT-ultrasound dataset of the fibula and tibia (UltraBones100k) and a CT-RGB-D dataset of spinal vertebrae (SpineDepth). The evaluation also includes a newly introduced CT--ultrasound dataset of cadaveric subjects containing femur and pelvis (UltraBones-Hip), which will be made publicly available. NeuralBoneReg matches or surpasses existing methods across all datasets, achieving mean RRE/RTE of 1.68°/1.86 mm on UltraBones100k, 1.88°/1.89 mm on UltraBones-Hip, and 3.79°/2.45 mm on SpineDepth. These results demonstrate strong generalizability across anatomies and modalities, providing robust and accurate cross-modal alignment for CAOS.
SonoGym: High Performance Simulation for Challenging Surgical Tasks with Robotic Ultrasound
Jul 01, 2025Ultrasound (US) is a widely used medical imaging modality due to its real-time capabilities, non-invasive nature, and cost-effectiveness. Robotic ultrasound can further enhance its utility by reducing operator dependence and improving access to complex anatomical regions. For this, while deep reinforcement learning (DRL) and imitation learning (IL) have shown potential for autonomous navigation, their use in complex surgical tasks such as anatomy reconstruction and surgical guidance remains limited -- largely due to the lack of realistic and efficient simulation environments tailored to these tasks. We introduce SonoGym, a scalable simulation platform for complex robotic ultrasound tasks that enables parallel simulation across tens to hundreds of environments. Our framework supports realistic and real-time simulation of US data from CT-derived 3D models of the anatomy through both a physics-based and a generative modeling approach. Sonogym enables the training of DRL and recent IL agents (vision transformers and diffusion policies) for relevant tasks in robotic orthopedic surgery by integrating common robotic platforms and orthopedic end effectors. We further incorporate submodular DRL -- a recent method that handles history-dependent rewards -- for anatomy reconstruction and safe reinforcement learning for surgery. Our results demonstrate successful policy learning across a range of scenarios, while also highlighting the limitations of current methods in clinically relevant environments. We believe our simulation can facilitate research in robot learning approaches for such challenging robotic surgery applications. Dataset, codes, and videos are publicly available at https://sonogym.github.io/.
MIXPINN: Mixed-Material Simulations by Physics-Informed Neural Network
Mar 17, 2025Simulating the complex interactions between soft tissues and rigid anatomy is critical for applications in surgical training, planning, and robotic-assisted interventions. Traditional Finite Element Method (FEM)-based simulations, while accurate, are computationally expensive and impractical for real-time scenarios. Learning-based approaches have shown promise in accelerating predictions but have fallen short in modeling soft-rigid interactions effectively. We introduce MIXPINN, a physics-informed Graph Neural Network (GNN) framework for mixed-material simulations, explicitly capturing soft-rigid interactions using graph-based augmentations. Our approach integrates Virtual Nodes (VNs) and Virtual Edges (VEs) to enhance rigid body constraint satisfaction while preserving computational efficiency. By leveraging a graph-based representation of biomechanical structures, MIXPINN learns high-fidelity deformations from FEM-generated data and achieves real-time inference with sub-millimeter accuracy. We validate our method in a realistic clinical scenario, demonstrating superior performance compared to baseline GNN models and traditional FEM methods. Our results show that MIXPINN reduces computational cost by an order of magnitude while maintaining high physical accuracy, making it a viable solution for real-time surgical simulation and robotic-assisted procedures.
Generalizable Single-Source Cross-modality Medical Image Segmentation via Invariant Causal Mechanisms
Nov 07, 2024Single-source domain generalization (SDG) aims to learn a model from a single source domain that can generalize well on unseen target domains. This is an important task in computer vision, particularly relevant to medical imaging where domain shifts are common. In this work, we consider a challenging yet practical setting: SDG for cross-modality medical image segmentation. We combine causality-inspired theoretical insights on learning domain-invariant representations with recent advancements in diffusion-based augmentation to improve generalization across diverse imaging modalities. Guided by the ``intervention-augmentation equivariant'' principle, we use controlled diffusion models (DMs) to simulate diverse imaging styles while preserving the content, leveraging rich generative priors in large-scale pretrained DMs to comprehensively perturb the multidimensional style variable. Extensive experiments on challenging cross-modality segmentation tasks demonstrate that our approach consistently outperforms state-of-the-art SDG methods across three distinct anatomies and imaging modalities. The source code is available at \href{https://github.com/ratschlab/ICMSeg}{https://github.com/ratschlab/ICMSeg}.
Safe Deep RL for Intraoperative Planning of Pedicle Screw Placement
May 10, 2023



Spinal fusion surgery requires highly accurate implantation of pedicle screw implants, which must be conducted in critical proximity to vital structures with a limited view of anatomy. Robotic surgery systems have been proposed to improve placement accuracy, however, state-of-the-art systems suffer from the limitations of open-loop approaches, as they follow traditional concepts of preoperative planning and intraoperative registration, without real-time recalculation of the surgical plan. In this paper, we propose an intraoperative planning approach for robotic spine surgery that leverages real-time observation for drill path planning based on Safe Deep Reinforcement Learning (DRL). The main contributions of our method are (1) the capability to guarantee safe actions by introducing an uncertainty-aware distance-based safety filter; and (2) the ability to compensate for incomplete intraoperative anatomical information, by encoding a-priori knowledge about anatomical structures with a network pre-trained on high-fidelity anatomical models. Planning quality was assessed by quantitative comparison with the gold standard (GS) drill planning. In experiments with 5 models derived from real magnetic resonance imaging (MRI) data, our approach was capable of achieving 90% bone penetration with respect to the GS while satisfying safety requirements, even under observation and motion uncertainty. To the best of our knowledge, our approach is the first safe DRL approach focusing on orthopedic surgeries.
Unified Data Collection for Visual-Inertial Calibration via Deep Reinforcement Learning
Sep 30, 2021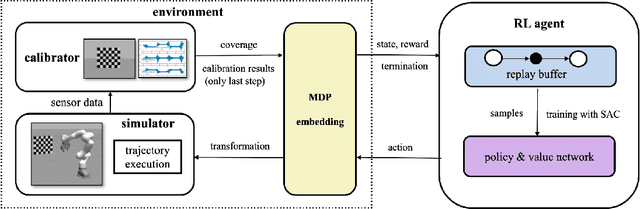
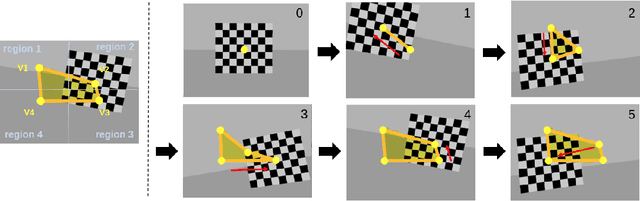

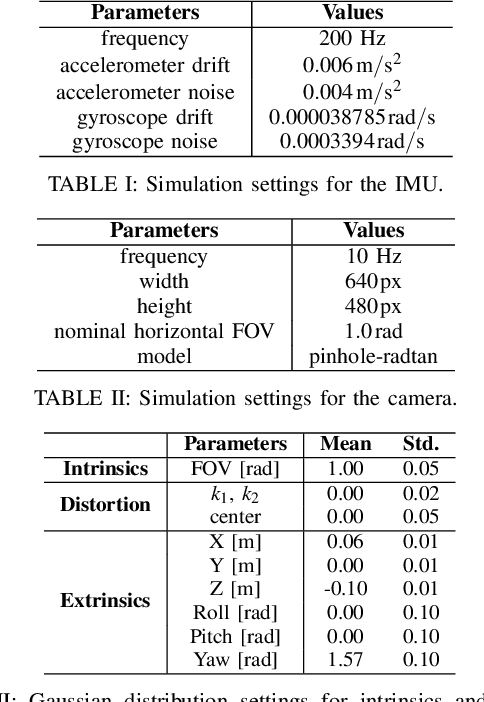
Visual-inertial sensors have a wide range of applications in robotics. However, good performance often requires different sophisticated motion routines to accurately calibrate camera intrinsics and inter-sensor extrinsics. This work presents a novel formulation to learn a motion policy to be executed on a robot arm for automatic data collection for calibrating intrinsics and extrinsics jointly. Our approach models the calibration process compactly using model-free deep reinforcement learning to derive a policy that guides the motions of a robotic arm holding the sensor to efficiently collect measurements that can be used for both camera intrinsic calibration and camera-IMU extrinsic calibration. Given the current pose and collected measurements, the learned policy generates the subsequent transformation that optimizes sensor calibration accuracy. The evaluations in simulation and on a real robotic system show that our learned policy generates favorable motion trajectories and collects enough measurements efficiently that yield the desired intrinsics and extrinsics with short path lengths. In simulation we are able to perform calibrations 10 times faster than hand-crafted policies, which transfers to a real-world speed up of 3 times over a human expert.
Learning Trajectories for Visual-Inertial System Calibration via Model-based Heuristic Deep Reinforcement Learning
Nov 04, 2020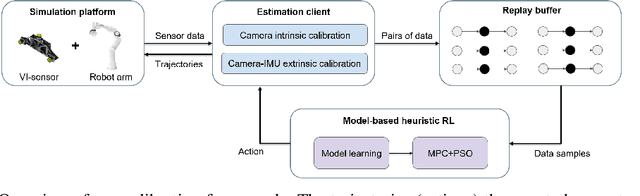

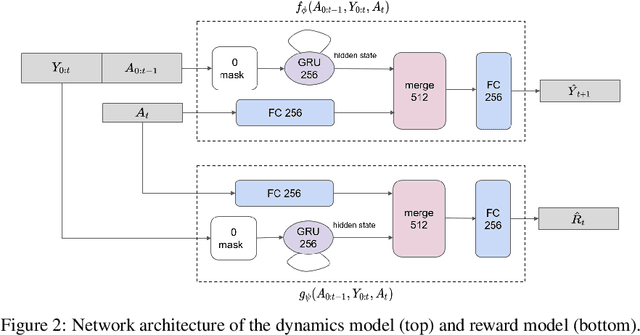
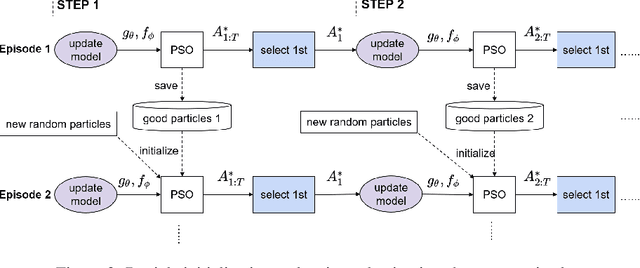
Visual-inertial systems rely on precise calibrations of both camera intrinsics and inter-sensor extrinsics, which typically require manually performing complex motions in front of a calibration target. In this work we present a novel approach to obtain favorable trajectories for visual-inertial system calibration, using model-based deep reinforcement learning. Our key contribution is to model the calibration process as a Markov decision process and then use model-based deep reinforcement learning with particle swarm optimization to establish a sequence of calibration trajectories to be performed by a robot arm. Our experiments show that while maintaining similar or shorter path lengths, the trajectories generated by our learned policy result in lower calibration errors compared to random or handcrafted trajectories.