 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Non-Uniform Replay Matter in Reinforcement Learning?
May 11, 2026Modern off-policy reinforcement learning algorithms often rely on simple uniform replay sampling and it remains unclear when and why non-uniform replay improves over this strong baseline. Across diverse RL settings, we show that the effectiveness of non-uniform replay is governed by three factors: replay volume, the number of replayed transitions per environment step; expected recency, how recent sampled transitions are; and the entropy of the replay sampling distribution. Our main contribution is clarifying when non-uniform replay is beneficial and providing practical guidance for replay design in modern off-policy RL. Namely, we find that non-uniform replay is most beneficial when replay volume is low, and that high-entropy sampling is important even at comparable expected recency. Motivated by these findings, we adopt a simple Truncated Geometric replay that biases sampling toward recent experience while preserving high entropy and incurring negligible computational overhead. Across large-scale parallel simulation, single-task, and multi-task settings, including three modern algorithms evaluated on five RL benchmark suites, this replay sampling strategy improves sample efficiency in low-volume regimes while remaining competitive when replay volume is high.
What Matters for Simulation to Online Reinforcement Learning on Real Robots
Feb 23, 2026We investigate what specific design choices enable successful online reinforcement learning (RL) on physical robots. Across 100 real-world training runs on three distinct robotic platforms, we systematically ablate algorithmic, systems, and experimental decisions that are typically left implicit in prior work. We find that some widely used defaults can be harmful, while a set of robust, readily adopted design choices within standard RL practice yield stable learning across tasks and hardware. These results provide the first large-sample empirical study of such design choices, enabling practitioners to deploy online RL with lower engineering effort.
Safe Exploration via Policy Priors
Jan 27, 2026Safe exploration is a key requirement for reinforcement learning (RL) agents to learn and adapt online, beyond controlled (e.g. simulated) environments. In this work, we tackle this challenge by utilizing suboptimal yet conservative policies (e.g., obtained from offline data or simulators) as priors. Our approach, SOOPER, uses probabilistic dynamics models to optimistically explore, yet pessimistically fall back to the conservative policy prior if needed. We prove that SOOPER guarantees safety throughout learning, and establish convergence to an optimal policy by bounding its cumulative regret. Extensive experiments on key safe RL benchmarks and real-world hardware demonstrate that SOOPER is scalable, outperforms the state-of-the-art and validate our theoretical guarantees in practice.
Learning Safety Constraints for Large Language Models
May 30, 2025Large language models (LLMs) have emerged as powerful tools but pose significant safety risks through harmful outputs and vulnerability to adversarial attacks. We propose SaP, short for Safety Polytope, a geometric approach to LLM safety that learns and enforces multiple safety constraints directly in the model's representation space. We develop a framework that identifies safe and unsafe regions via the polytope's facets, enabling both detection and correction of unsafe outputs through geometric steering. Unlike existing approaches that modify model weights, SaP operates post-hoc in the representation space, preserving model capabilities while enforcing safety constraints. Experiments across multiple LLMs demonstrate that our method can effectively detect unethical inputs, reduce adversarial attack success rates while maintaining performance on standard tasks, thus highlighting the importance of having an explicit geometric model for safety. Analysis of the learned polytope facets reveals emergence of specialization in detecting different semantic notions of safety, providing interpretable insights into how safety is captured in LLMs' representation space.
Safe-EF: Error Feedback for Nonsmooth Constrained Optimization
May 09, 2025Federated learning faces severe communication bottlenecks due to the high dimensionality of model updates. Communication compression with contractive compressors (e.g., Top-K) is often preferable in practice but can degrade performance without proper handling. Error feedback (EF) mitigates such issues but has been largely restricted for smooth, unconstrained problems, limiting its real-world applicability where non-smooth objectives and safety constraints are critical. We advance our understanding of EF in the canonical non-smooth convex setting by establishing new lower complexity bounds for first-order algorithms with contractive compression. Next, we propose Safe-EF, a novel algorithm that matches our lower bound (up to a constant) while enforcing safety constraints essential for practical applications. Extending our approach to the stochastic setting, we bridge the gap between theory and practical implementation. Extensive experiments in a reinforcement learning setup, simulating distributed humanoid robot training, validate the effectiveness of Safe-EF in ensuring safety and reducing communication complexity.
Toward Task Generalization via Memory Augmentation in Meta-Reinforcement Learning
Feb 03, 2025



In reinforcement learning (RL), agents often struggle to perform well on tasks that differ from those encountered during training. This limitation presents a challenge to the broader deployment of RL in diverse and dynamic task settings. In this work, we introduce memory augmentation, a memory-based RL approach to improve task generalization. Our approach leverages task-structured augmentations to simulate plausible out-of-distribution scenarios and incorporates memory mechanisms to enable context-aware policy adaptation. Trained on a predefined set of tasks, our policy demonstrates the ability to generalize to unseen tasks through memory augmentation without requiring additional interactions with the environment. Through extensive simulation experiments and real-world hardware evaluations on legged locomotion tasks, we demonstrate that our approach achieves zero-shot generalization to unseen tasks while maintaining robust in-distribution performance and high sample efficiency.
ActSafe: Active Exploration with Safety Constraints for Reinforcement Learning
Oct 12, 2024



Reinforcement learning (RL) is ubiquitous in the development of modern AI systems. However, state-of-the-art RL agents require extensive, and potentially unsafe, interactions with their environments to learn effectively. These limitations confine RL agents to simulated environments, hindering their ability to learn directly in real-world settings. In this work, we present ActSafe, a novel model-based RL algorithm for safe and efficient exploration. ActSafe learns a well-calibrated probabilistic model of the system and plans optimistically w.r.t. the epistemic uncertainty about the unknown dynamics, while enforcing pessimism w.r.t. the safety constraints. Under regularity assumptions on the constraints and dynamics, we show that ActSafe guarantees safety during learning while also obtaining a near-optimal policy in finite time. In addition, we propose a practical variant of ActSafe that builds on latest model-based RL advancements and enables safe exploration even in high-dimensional settings such as visual control. We empirically show that ActSafe obtains state-of-the-art performance in difficult exploration tasks on standard safe deep RL benchmarks while ensuring safety during learning.
When to Sense and Control? A Time-adaptive Approach for Continuous-Time RL
Jun 04, 2024Reinforcement learning (RL) excels in optimizing policies for discrete-time Markov decision processes (MDP). However, various systems are inherently continuous in time, making discrete-time MDPs an inexact modeling choice. In many applications, such as greenhouse control or medical treatments, each interaction (measurement or switching of action) involves manual intervention and thus is inherently costly. Therefore, we generally prefer a time-adaptive approach with fewer interactions with the system. In this work, we formalize an RL framework, Time-adaptive Control & Sensing (TaCoS), that tackles this challenge by optimizing over policies that besides control predict the duration of its application. Our formulation results in an extended MDP that any standard RL algorithm can solve. We demonstrate that state-of-the-art RL algorithms trained on TaCoS drastically reduce the interaction amount over their discrete-time counterpart while retaining the same or improved performance, and exhibiting robustness over discretization frequency. Finally, we propose OTaCoS, an efficient model-based algorithm for our setting. We show that OTaCoS enjoys sublinear regret for systems with sufficiently smooth dynamics and empirically results in further sample-efficiency gains.
Safe Exploration Using Bayesian World Models and Log-Barrier Optimization
May 09, 2024A major challenge in deploying reinforcement learning in online tasks is ensuring that safety is maintained throughout the learning process. In this work, we propose CERL, a new method for solving constrained Markov decision processes while keeping the policy safe during learning. Our method leverages Bayesian world models and suggests policies that are pessimistic w.r.t. the model's epistemic uncertainty. This makes CERL robust towards model inaccuracies and leads to safe exploration during learning. In our experiments, we demonstrate that CERL outperforms the current state-of-the-art in terms of safety and optimality in solving CMDPs from image observations.
Information-based Transductive Active Learning
Feb 13, 2024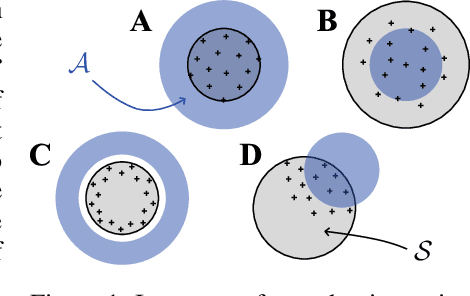
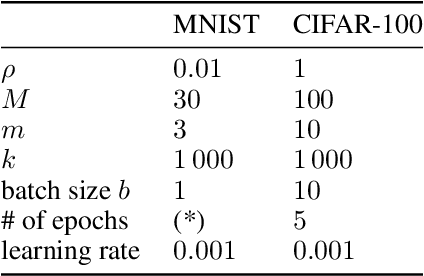
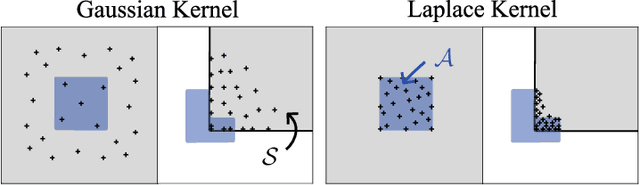
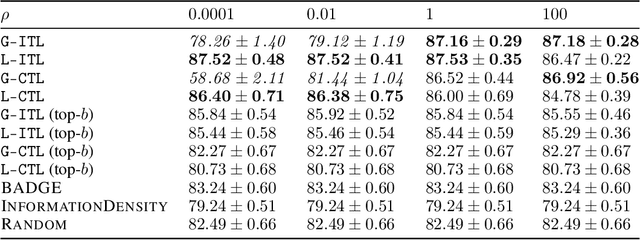
We generalize active learning to address real-world settings where sampling is restricted to an accessible region of the domain, while prediction targets may lie outside this region. To this end, we propose ITL, short for information-based transductive learning, an approach which samples adaptively to maximize the information gained about specified prediction targets. We show, under general regularity assumptions, that ITL converges uniformly to the smallest possible uncertainty obtainable from the accessible data. We demonstrate ITL in two key applications: Few-shot fine-tuning of large neural networks and safe Bayesian optimization, and in both cases, ITL significantly outperforms the state-of-the-art.