 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA combination of noise and bilateral filters achieve supralinear and scalable adversarial robustness in CNNs
Jun 01, 2026The vulnerability of deep neural networks to adversarial examples poses a significant challenge for real-world deployment. Existing techniques to enhance deep network robustness rely on adversarial training, an approach that is powerful but computationally intensive and typically tailored to specific attack types. To address these limitations, existing works have explored techniques such as adding gaussian noise or filtering images, both of which can boost the network robustness to various adversarial attacks, albeit modestly. Here, we theoretically demonstrate that these two approaches enhance robustness against adversarial attacks through complementary mechanisms, resulting in supralinear robustness when combined. Building on this insight, we experimentally show that a simple preprocessor combining Gaussian noise and bilateral filtering yields supralinear improvements in adversarial robustness with minimal computational cost. Next, we combine our preprocessor with adversarial training and test on RobustBench to assess its supralinear improvement over state-of-the-art defenses. First, this combination ranks second on AutoAttack and third overall, while using only $\sim$35% of the training FLOPs, using a model with $\sim$50% less parametets, trained with $\sim$33% of the epochs and $\sim$15% the data compared to state-of-the-art defenses. Second, our method scales efficiently, matching the accuracy of competing models with roughly 2-8x less total compute across 3 orders of magnitude. Overall, our approach provides a principled and easily integrable framework for enhancing adversarial robustness, offering negligible computational overhead and a simple yet theoretically grounded design.
Learning Compositional Latent Structure with Vector Networks
May 27, 2026Deep networks are powerful function approximators, but they typically store many different computations in shared weight matrices, making it difficult to selectively reuse or adapt parts of them when a familiar structure appears in novel combinations. We introduce the Vector Network (VN), a hierarchical recurrent architecture in which each layer replaces a fixed weight matrix with a library of reusable rank-1 weight atoms. For each input, VN minimizes a layer-local energy to infer a sparse set of active weight atoms and their coefficients, jointly constrained by bottom-up input reconstruction and top-down feedback consistency. These weight atom coefficients then compose an input-specific low-rank weight matrix for that sample. After convergence, slow learning updates only the selected weight atoms through local residual signals scaled by the inferred coefficients. We evaluate VN on four compositional benchmarks spanning 1D signals, 2D spatial decoding, N-body dynamics, and compositional MNIST. VN matches strong baselines in distribution while often achieving out-of-distribution error about an order of magnitude lower when familiar factors must be recombined in novel ways. Vector networks thus make compositional generalization a structural property of the architecture and inference process rather than a brittle byproduct of fitting many behaviors into one shared dense parameter substrate.
Continual Learning through Control Minimization
Feb 04, 2026Catastrophic forgetting remains a fundamental challenge for neural networks when tasks are trained sequentially. In this work, we reformulate continual learning as a control problem where learning and preservation signals compete within neural activity dynamics. We convert regularization penalties into preservation signals that protect prior-task representations. Learning then proceeds by minimizing the control effort required to integrate new tasks while competing with the preservation of prior tasks. At equilibrium, the neural activities produce weight updates that implicitly encode the full prior-task curvature, a property we term the continual-natural gradient, requiring no explicit curvature storage. Experiments confirm that our learning framework recovers true prior-task curvature and enables task discrimination, outperforming existing methods on standard benchmarks without replay.
mimic-one: a Scalable Model Recipe for General Purpose Robot Dexterity
Jun 13, 2025

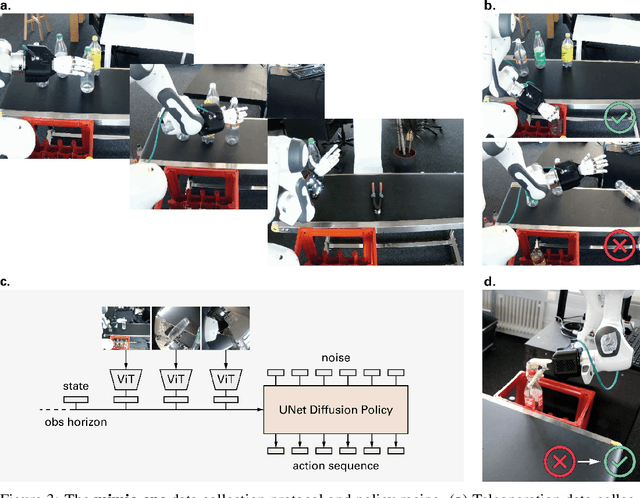
We present a diffusion-based model recipe for real-world control of a highly dexterous humanoid robotic hand, designed for sample-efficient learning and smooth fine-motor action inference. Our system features a newly designed 16-DoF tendon-driven hand, equipped with wide angle wrist cameras and mounted on a Franka Emika Panda arm. We develop a versatile teleoperation pipeline and data collection protocol using both glove-based and VR interfaces, enabling high-quality data collection across diverse tasks such as pick and place, item sorting and assembly insertion. Leveraging high-frequency generative control, we train end-to-end policies from raw sensory inputs, enabling smooth, self-correcting motions in complex manipulation scenarios. Real-world evaluations demonstrate up to 93.3% out of distribution success rates, with up to a +33.3% performance boost due to emergent self-correcting behaviors, while also revealing scaling trends in policy performance. Our results advance the state-of-the-art in dexterous robotic manipulation through a fully integrated, practical approach to hardware, learning, and real-world deployment.
Deep Retrieval at CheckThat! 2025: Identifying Scientific Papers from Implicit Social Media Mentions via Hybrid Retrieval and Re-Ranking
May 29, 2025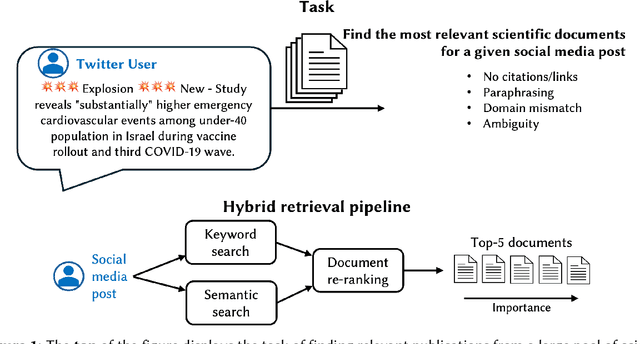
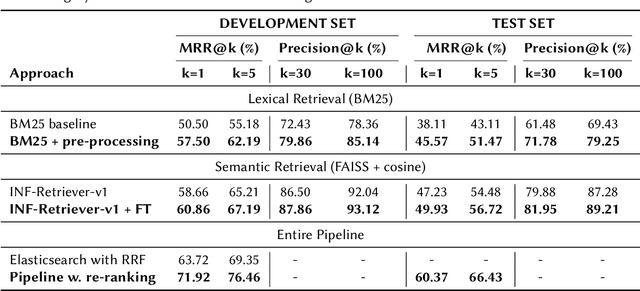
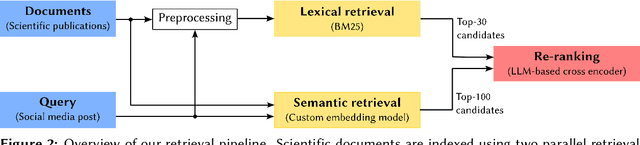
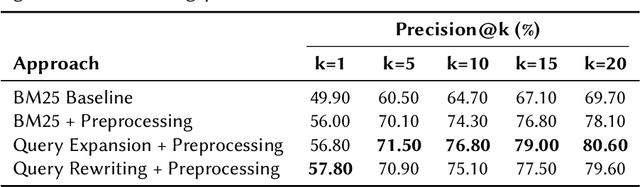
We present the methodology and results of the Deep Retrieval team for subtask 4b of the CLEF CheckThat! 2025 competition, which focuses on retrieving relevant scientific literature for given social media posts. To address this task, we propose a hybrid retrieval pipeline that combines lexical precision, semantic generalization, and deep contextual re-ranking, enabling robust retrieval that bridges the informal-to-formal language gap. Specifically, we combine BM25-based keyword matching with a FAISS vector store using a fine-tuned INF-Retriever-v1 model for dense semantic retrieval. BM25 returns the top 30 candidates, and semantic search yields 100 candidates, which are then merged and re-ranked via a large language model (LLM)-based cross-encoder. Our approach achieves a mean reciprocal rank at 5 (MRR@5) of 76.46% on the development set and 66.43% on the hidden test set, securing the 1st position on the development leaderboard and ranking 3rd on the test leaderboard (out of 31 teams), with a relative performance gap of only 2 percentage points compared to the top-ranked system. We achieve this strong performance by running open-source models locally and without external training data, highlighting the effectiveness of a carefully designed and fine-tuned retrieval pipeline.
Learning Actionable World Models for Industrial Process Control
Mar 03, 2025



To go from (passive) process monitoring to active process control, an effective AI system must learn about the behavior of the complex system from very limited training data, forming an ad-hoc digital twin with respect to process in- and outputs that captures the consequences of actions on the process's world. We propose a novel methodology based on learning world models that disentangles process parameters in the learned latent representation, allowing for fine-grained control. Representation learning is driven by the latent factors that influence the processes through contrastive learning within a joint embedding predictive architecture. This makes changes in representations predictable from changes in inputs and vice versa, facilitating interpretability of key factors responsible for process variations, paving the way for effective control actions to keep the process within operational bounds. The effectiveness of our method is validated on the example of plastic injection molding, demonstrating practical relevance in proposing specific control actions for a notoriously unstable process.
AI Agents for Computer Use: A Review of Instruction-based Computer Control, GUI Automation, and Operator Assistants
Jan 27, 2025



Instruction-based computer control agents (CCAs) execute complex action sequences on personal computers or mobile devices to fulfill tasks using the same graphical user interfaces as a human user would, provided instructions in natural language. This review offers a comprehensive overview of the emerging field of instruction-based computer control, examining available agents -- their taxonomy, development, and respective resources -- and emphasizing the shift from manually designed, specialized agents to leveraging foundation models such as large language models (LLMs) and vision-language models (VLMs). We formalize the problem and establish a taxonomy of the field to analyze agents from three perspectives: (a) the environment perspective, analyzing computer environments; (b) the interaction perspective, describing observations spaces (e.g., screenshots, HTML) and action spaces (e.g., mouse and keyboard actions, executable code); and (c) the agent perspective, focusing on the core principle of how an agent acts and learns to act. Our framework encompasses both specialized and foundation agents, facilitating their comparative analysis and revealing how prior solutions in specialized agents, such as an environment learning step, can guide the development of more capable foundation agents. Additionally, we review current CCA datasets and CCA evaluation methods and outline the challenges to deploying such agents in a productive setting. In total, we review and classify 86 CCAs and 33 related datasets. By highlighting trends, limitations, and future research directions, this work presents a comprehensive foundation to obtain a broad understanding of the field and push its future development.
Local vs Global continual learning
Jul 23, 2024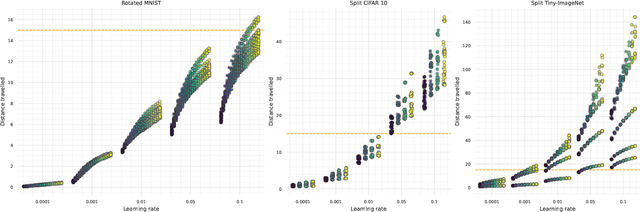



Continual learning is the problem of integrating new information in a model while retaining the knowledge acquired in the past. Despite the tangible improvements achieved in recent years, the problem of continual learning is still an open one. A better understanding of the mechanisms behind the successes and failures of existing continual learning algorithms can unlock the development of new successful strategies. In this work, we view continual learning from the perspective of the multi-task loss approximation, and we compare two alternative strategies, namely local and global approximations. We classify existing continual learning algorithms based on the approximation used, and we assess the practical effects of this distinction in common continual learning settings.Additionally, we study optimal continual learning objectives in the case of local polynomial approximations and we provide examples of existing algorithms implementing the optimal objectives
The Dynamic Net Architecture: Learning Robust and Holistic Visual Representations Through Self-Organizing Networks
Jul 08, 2024



We present a novel intelligent-system architecture called "Dynamic Net Architecture" (DNA) that relies on recurrence-stabilized networks and discuss it in application to vision. Our architecture models a (cerebral cortical) area wherein elementary feature neurons encode details of visual structures, and coherent nets of such neurons model holistic object structures. By interpreting smaller or larger coherent pieces of an area network as complex features, our model encodes hierarchical feature representations essentially different than artificial neural networks (ANNs). DNA models operate on a dynamic connectionism principle, wherein neural activations stemming from initial afferent signals undergo stabilization through a self-organizing mechanism facilitated by Hebbian plasticity alongside periodically tightening inhibition. In contrast to ANNs, which rely on feed-forward connections and backpropagation of error, we posit that this processing paradigm leads to highly robust representations, as by employing dynamic lateral connections, irrelevant details in neural activations are filtered out, freeing further processing steps from distracting noise and premature decisions. We empirically demonstrate the viability of the DNA by composing line fragments into longer lines and show that the construction of nets representing lines remains robust even with the introduction of up to $59\%$ noise at each spatial location. Furthermore, we demonstrate the model's capability to reconstruct anticipated features from partially obscured inputs and that it can generalize to patterns not observed during training. In this work, we limit the DNA to one cortical area and focus on its internals while providing insights into a standalone area's strengths and shortcomings. Additionally, we provide an outlook on how future work can implement invariant object recognition by combining multiple areas.
Towards guarantees for parameter isolation in continual learning
Oct 02, 2023



Deep learning has proved to be a successful paradigm for solving many challenges in machine learning. However, deep neural networks fail when trained sequentially on multiple tasks, a shortcoming known as catastrophic forgetting in the continual learning literature. Despite a recent flourish of learning algorithms successfully addressing this problem, we find that provable guarantees against catastrophic forgetting are lacking. In this work, we study the relationship between learning and forgetting by looking at the geometry of neural networks' loss landscape. We offer a unifying perspective on a family of continual learning algorithms, namely methods based on parameter isolation, and we establish guarantees on catastrophic forgetting for some of them.