 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Neural Network Training Along Sharp and Flat Directions
May 17, 2025Recent work has highlighted a surprising alignment between gradients and the top eigenspace of the Hessian -- termed the Dominant subspace -- during neural network training. Concurrently, there has been growing interest in the distinct roles of sharp and flat directions in the Hessian spectrum. In this work, we study Bulk-SGD, a variant of SGD that restricts updates to the orthogonal complement of the Dominant subspace. Through ablation studies, we characterize the stability properties of Bulk-SGD and identify critical hyperparameters that govern its behavior. We show that updates along the Bulk subspace, corresponding to flatter directions in the loss landscape, can accelerate convergence but may compromise stability. To balance these effects, we introduce interpolated gradient methods that unify SGD, Dom-SGD, and Bulk-SGD. Finally, we empirically connect this subspace decomposition to the Generalized Gauss-Newton and Functional Hessian terms, showing that curvature energy is largely concentrated in the Dominant subspace. Our findings suggest a principled approach to designing curvature-aware optimizers.
Avoiding spurious sharpness minimization broadens applicability of SAM
Feb 04, 2025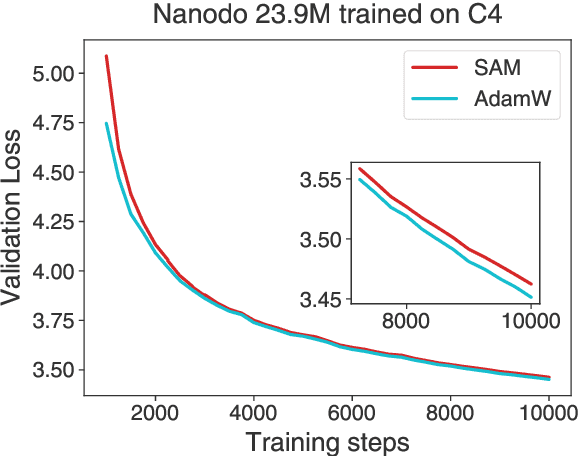



Curvature regularization techniques like Sharpness Aware Minimization (SAM) have shown great promise in improving generalization on vision tasks. However, we find that SAM performs poorly in domains like natural language processing (NLP), often degrading performance -- even with twice the compute budget. We investigate the discrepancy across domains and find that in the NLP setting, SAM is dominated by regularization of the logit statistics -- instead of improving the geometry of the function itself. We use this observation to develop an alternative algorithm we call Functional-SAM, which regularizes curvature only through modification of the statistics of the overall function implemented by the neural network, and avoids spurious minimization through logit manipulation. Furthermore, we argue that preconditioning the SAM perturbation also prevents spurious minimization, and when combined with Functional-SAM, it gives further improvements. Our proposed algorithms show improved performance over AdamW and SAM baselines when trained for an equal number of steps, in both fixed-length and Chinchilla-style training settings, at various model scales (including billion-parameter scale). On the whole, our work highlights the importance of more precise characterizations of sharpness in broadening the applicability of curvature regularization to large language models (LLMs).
Theoretical characterisation of the Gauss-Newton conditioning in Neural Networks
Nov 04, 2024



The Gauss-Newton (GN) matrix plays an important role in machine learning, most evident in its use as a preconditioning matrix for a wide family of popular adaptive methods to speed up optimization. Besides, it can also provide key insights into the optimization landscape of neural networks. In the context of deep neural networks, understanding the GN matrix involves studying the interaction between different weight matrices as well as the dependencies introduced by the data, thus rendering its analysis challenging. In this work, we take a first step towards theoretically characterizing the conditioning of the GN matrix in neural networks. We establish tight bounds on the condition number of the GN in deep linear networks of arbitrary depth and width, which we also extend to two-layer ReLU networks. We expand the analysis to further architectural components, such as residual connections and convolutional layers. Finally, we empirically validate the bounds and uncover valuable insights into the influence of the analyzed architectural components.
What Does It Mean to Be a Transformer? Insights from a Theoretical Hessian Analysis
Oct 14, 2024



The Transformer architecture has inarguably revolutionized deep learning, overtaking classical architectures like multi-layer perceptrons (MLPs) and convolutional neural networks (CNNs). At its core, the attention block differs in form and functionality from most other architectural components in deep learning -- to the extent that Transformers are often accompanied by adaptive optimizers, layer normalization, learning rate warmup, and more, in comparison to MLPs/CNNs. The root causes behind these outward manifestations, and the precise mechanisms that govern them, remain poorly understood. In this work, we bridge this gap by providing a fundamental understanding of what distinguishes the Transformer from the other architectures -- grounded in a theoretical comparison of the (loss) Hessian. Concretely, for a single self-attention layer, (a) we first entirely derive the Transformer's Hessian and express it in matrix derivatives; (b) we then characterize it in terms of data, weight, and attention moment dependencies; and (c) while doing so further highlight the important structural differences to the Hessian of classical networks. Our results suggest that various common architectural and optimization choices in Transformers can be traced back to their highly non-linear dependencies on the data and weight matrices, which vary heterogeneously across parameters. Ultimately, our findings provide a deeper understanding of the Transformer's unique optimization landscape and the challenges it poses.
Local vs Global continual learning
Jul 23, 2024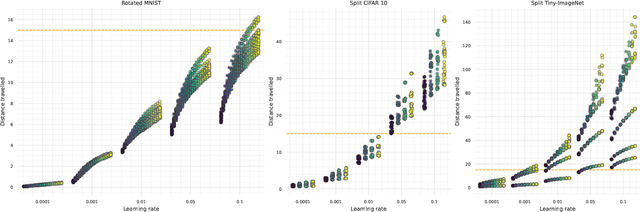



Continual learning is the problem of integrating new information in a model while retaining the knowledge acquired in the past. Despite the tangible improvements achieved in recent years, the problem of continual learning is still an open one. A better understanding of the mechanisms behind the successes and failures of existing continual learning algorithms can unlock the development of new successful strategies. In this work, we view continual learning from the perspective of the multi-task loss approximation, and we compare two alternative strategies, namely local and global approximations. We classify existing continual learning algorithms based on the approximation used, and we assess the practical effects of this distinction in common continual learning settings.Additionally, we study optimal continual learning objectives in the case of local polynomial approximations and we provide examples of existing algorithms implementing the optimal objectives
Landscaping Linear Mode Connectivity
Jun 24, 2024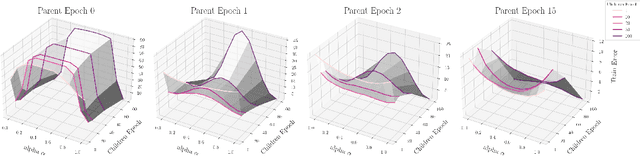
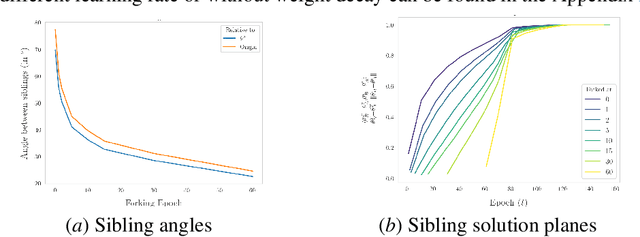
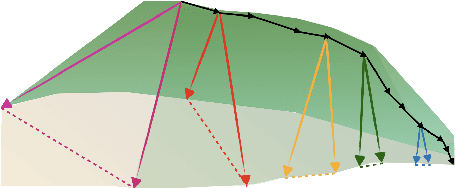
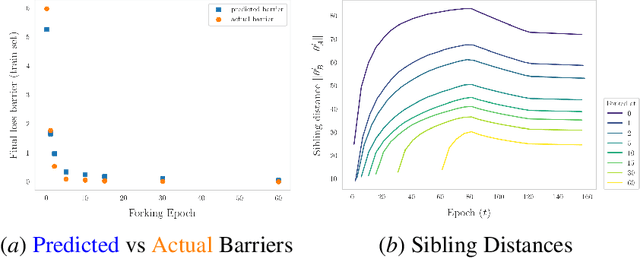
The presence of linear paths in parameter space between two different network solutions in certain cases, i.e., linear mode connectivity (LMC), has garnered interest from both theoretical and practical fronts. There has been significant research that either practically designs algorithms catered for connecting networks by adjusting for the permutation symmetries as well as some others that more theoretically construct paths through which networks can be connected. Yet, the core reasons for the occurrence of LMC, when in fact it does occur, in the highly non-convex loss landscapes of neural networks are far from clear. In this work, we take a step towards understanding it by providing a model of how the loss landscape needs to behave topographically for LMC (or the lack thereof) to manifest. Concretely, we present a `mountainside and ridge' perspective that helps to neatly tie together different geometric features that can be spotted in the loss landscape along the training runs. We also complement this perspective by providing a theoretical analysis of the barrier height, for which we provide empirical support, and which additionally extends as a faithful predictor of layer-wise LMC. We close with a toy example that provides further intuition on how barriers arise in the first place, all in all, showcasing the larger aim of the work -- to provide a working model of the landscape and its topography for the occurrence of LMC.
Hallmarks of Optimization Trajectories in Neural Networks and LLMs: The Lengths, Bends, and Dead Ends
Mar 12, 2024



We propose a fresh take on understanding the mechanisms of neural networks by analyzing the rich structure of parameters contained within their optimization trajectories. Towards this end, we introduce some natural notions of the complexity of optimization trajectories, both qualitative and quantitative, which reveal the inherent nuance and interplay involved between various optimization choices, such as momentum, weight decay, and batch size. We use them to provide key hallmarks about the nature of optimization in deep neural networks: when it goes right, and when it finds itself in a dead end. Further, thanks to our trajectory perspective, we uncover an intertwined behaviour of momentum and weight decay that promotes directional exploration, as well as a directional regularization behaviour of some others. We perform experiments over large-scale vision and language settings, including large language models (LLMs) with up to 12 billion parameters, to demonstrate the value of our approach.
Towards Meta-Pruning via Optimal Transport
Feb 13, 2024Structural pruning of neural networks conventionally relies on identifying and discarding less important neurons, a practice often resulting in significant accuracy loss that necessitates subsequent fine-tuning efforts. This paper introduces a novel approach named Intra-Fusion, challenging this prevailing pruning paradigm. Unlike existing methods that focus on designing meaningful neuron importance metrics, Intra-Fusion redefines the overlying pruning procedure. Through utilizing the concepts of model fusion and Optimal Transport, we leverage an agnostically given importance metric to arrive at a more effective sparse model representation. Notably, our approach achieves substantial accuracy recovery without the need for resource-intensive fine-tuning, making it an efficient and promising tool for neural network compression. Additionally, we explore how fusion can be added to the pruning process to significantly decrease the training time while maintaining competitive performance. We benchmark our results for various networks on commonly used datasets such as CIFAR-10, CIFAR-100, and ImageNet. More broadly, we hope that the proposed Intra-Fusion approach invigorates exploration into a fresh alternative to the predominant compression approaches. Our code is available here: https://github.com/alexandertheus/Intra-Fusion.
Rethinking Attention: Exploring Shallow Feed-Forward Neural Networks as an Alternative to Attention Layers in Transformers
Nov 29, 2023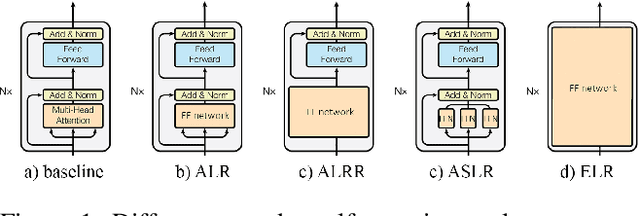



This work presents an analysis of the effectiveness of using standard shallow feed-forward networks to mimic the behavior of the attention mechanism in the original Transformer model, a state-of-the-art architecture for sequence-to-sequence tasks. We substitute key elements of the attention mechanism in the Transformer with simple feed-forward networks, trained using the original components via knowledge distillation. Our experiments, conducted on the IWSLT2017 dataset, reveal the capacity of these "attentionless Transformers" to rival the performance of the original architecture. Through rigorous ablation studies, and experimenting with various replacement network types and sizes, we offer insights that support the viability of our approach. This not only sheds light on the adaptability of shallow feed-forward networks in emulating attention mechanisms but also underscores their potential to streamline complex architectures for sequence-to-sequence tasks.
Transformer Fusion with Optimal Transport
Oct 15, 2023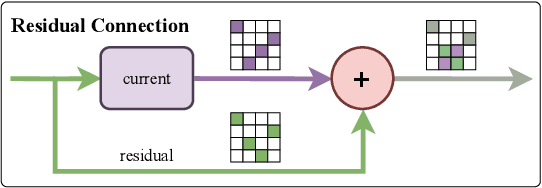


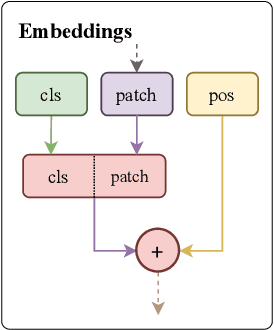
Fusion is a technique for merging multiple independently-trained neural networks in order to combine their capabilities. Past attempts have been restricted to the case of fully-connected, convolutional, and residual networks. In this paper, we present a systematic approach for fusing two or more transformer-based networks exploiting Optimal Transport to (soft-)align the various architectural components. We flesh out an abstraction for layer alignment, that can generalize to arbitrary architectures -- in principle -- and we apply this to the key ingredients of Transformers such as multi-head self-attention, layer-normalization, and residual connections, and we discuss how to handle them via various ablation studies. Furthermore, our method allows the fusion of models of different sizes (heterogeneous fusion), providing a new and efficient way for compression of Transformers. The proposed approach is evaluated on both image classification tasks via Vision Transformer and natural language modeling tasks using BERT. Our approach consistently outperforms vanilla fusion, and, after a surprisingly short finetuning, also outperforms the individual converged parent models. In our analysis, we uncover intriguing insights about the significant role of soft alignment in the case of Transformers. Our results showcase the potential of fusing multiple Transformers, thus compounding their expertise, in the budding paradigm of model fusion and recombination.