 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Flatness Does (Not) Guarantee Adversarial Robustness
Oct 16, 2025Despite their empirical success, neural networks remain vulnerable to small, adversarial perturbations. A longstanding hypothesis suggests that flat minima, regions of low curvature in the loss landscape, offer increased robustness. While intuitive, this connection has remained largely informal and incomplete. By rigorously formalizing the relationship, we show this intuition is only partially correct: flatness implies local but not global adversarial robustness. To arrive at this result, we first derive a closed-form expression for relative flatness in the penultimate layer, and then show we can use this to constrain the variation of the loss in input space. This allows us to formally analyze the adversarial robustness of the entire network. We then show that to maintain robustness beyond a local neighborhood, the loss needs to curve sharply away from the data manifold. We validate our theoretical predictions empirically across architectures and datasets, uncovering the geometric structure that governs adversarial vulnerability, and linking flatness to model confidence: adversarial examples often lie in large, flat regions where the model is confidently wrong. Our results challenge simplified views of flatness and provide a nuanced understanding of its role in robustness.
Landscaping Linear Mode Connectivity
Jun 24, 2024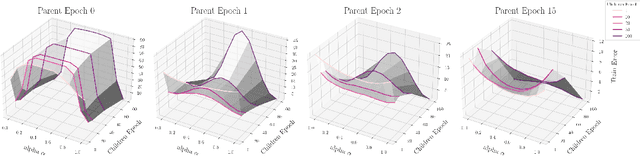
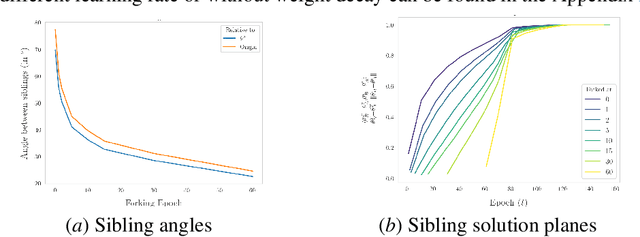
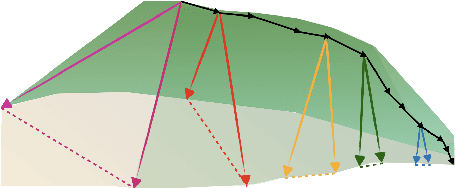
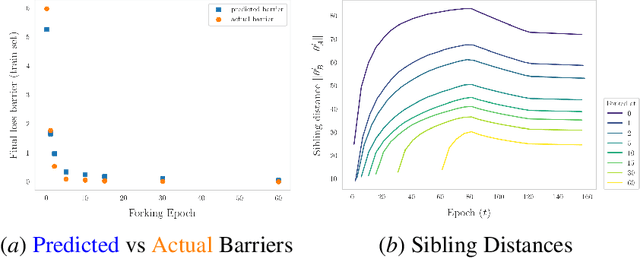
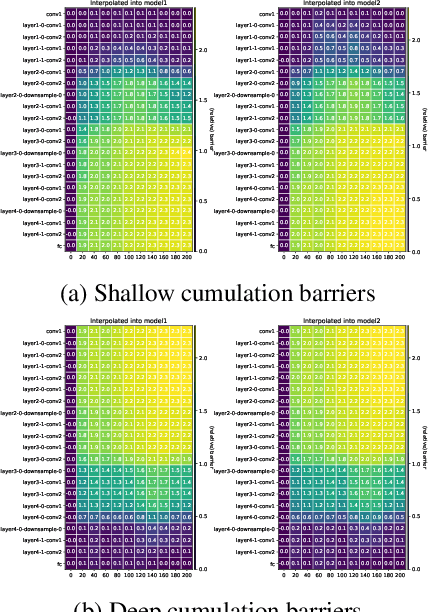
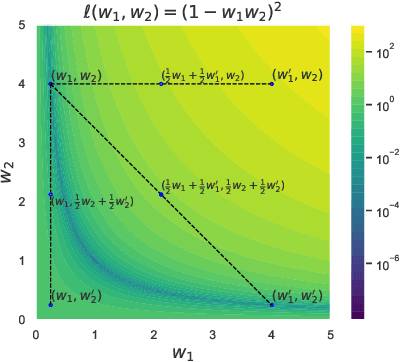
The presence of linear paths in parameter space between two different network solutions in certain cases, i.e., linear mode connectivity (LMC), has garnered interest from both theoretical and practical fronts. There has been significant research that either practically designs algorithms catered for connecting networks by adjusting for the permutation symmetries as well as some others that more theoretically construct paths through which networks can be connected. Yet, the core reasons for the occurrence of LMC, when in fact it does occur, in the highly non-convex loss landscapes of neural networks are far from clear. In this work, we take a step towards understanding it by providing a model of how the loss landscape needs to behave topographically for LMC (or the lack thereof) to manifest. Concretely, we present a `mountainside and ridge' perspective that helps to neatly tie together different geometric features that can be spotted in the loss landscape along the training runs. We also complement this perspective by providing a theoretical analysis of the barrier height, for which we provide empirical support, and which additionally extends as a faithful predictor of layer-wise LMC. We close with a toy example that provides further intuition on how barriers arise in the first place, all in all, showcasing the larger aim of the work -- to provide a working model of the landscape and its topography for the occurrence of LMC.
The Uncanny Valley: Exploring Adversarial Robustness from a Flatness Perspective
May 27, 2024



Flatness of the loss surface not only correlates positively with generalization but is also related to adversarial robustness, since perturbations of inputs relate non-linearly to perturbations of weights. In this paper, we empirically analyze the relation between adversarial examples and relative flatness with respect to the parameters of one layer. We observe a peculiar property of adversarial examples: during an iterative first-order white-box attack, the flatness of the loss surface measured around the adversarial example first becomes sharper until the label is flipped, but if we keep the attack running it runs into a flat uncanny valley where the label remains flipped. We find this phenomenon across various model architectures and datasets. Our results also extend to large language models (LLMs), but due to the discrete nature of the input space and comparatively weak attacks, the adversarial examples rarely reach a truly flat region. Most importantly, this phenomenon shows that flatness alone cannot explain adversarial robustness unless we can also guarantee the behavior of the function around the examples. We theoretically connect relative flatness to adversarial robustness by bounding the third derivative of the loss surface, underlining the need for flatness in combination with a low global Lipschitz constant for a robust model.
Layerwise Linear Mode Connectivity
Jul 13, 2023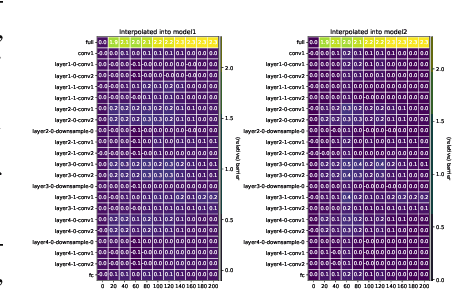

In the federated setup one performs an aggregation of separate local models multiple times during training in order to obtain a stronger global model; most often aggregation is a simple averaging of the parameters. Understanding when and why averaging works in a non-convex setup, such as federated deep learning, is an open challenge that hinders obtaining highly performant global models. On i.i.d.~datasets federated deep learning with frequent averaging is successful. The common understanding, however, is that during the independent training models are drifting away from each other and thus averaging may not work anymore after many local parameter updates. The problem can be seen from the perspective of the loss surface: for points on a non-convex surface the average can become arbitrarily bad. The assumption of local convexity, often used to explain the success of federated averaging, contradicts to the empirical evidence showing that high loss barriers exist between models from the very beginning of the learning, even when training on the same data. Based on the observation that the learning process evolves differently in different layers, we investigate the barrier between models in a layerwise fashion. Our conjecture is that barriers preventing from successful federated training are caused by a particular layer or group of layers.
FAM: Relative Flatness Aware Minimization
Jul 05, 2023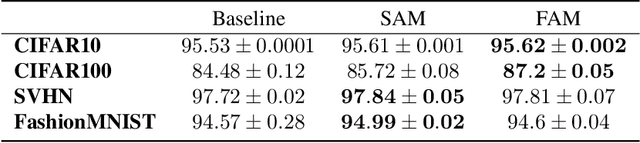
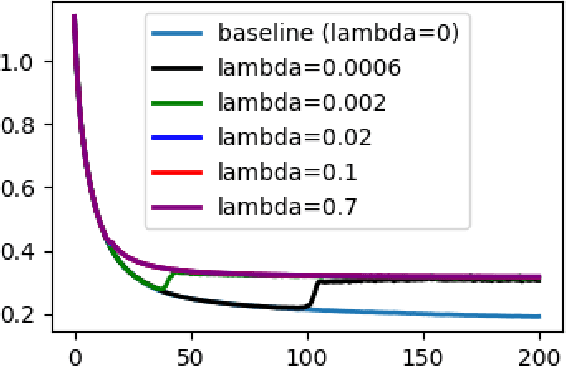
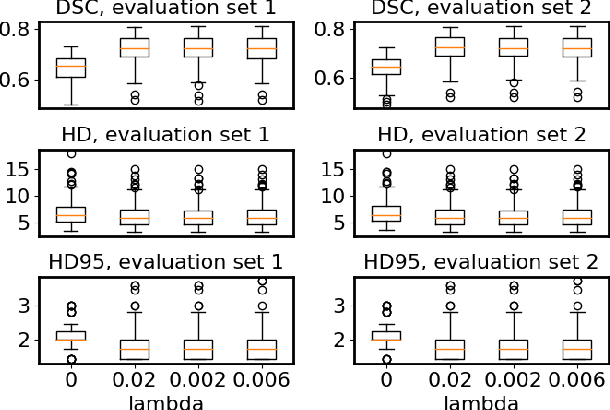

Flatness of the loss curve around a model at hand has been shown to empirically correlate with its generalization ability. Optimizing for flatness has been proposed as early as 1994 by Hochreiter and Schmidthuber, and was followed by more recent successful sharpness-aware optimization techniques. Their widespread adoption in practice, though, is dubious because of the lack of theoretically grounded connection between flatness and generalization, in particular in light of the reparameterization curse - certain reparameterizations of a neural network change most flatness measures but do not change generalization. Recent theoretical work suggests that a particular relative flatness measure can be connected to generalization and solves the reparameterization curse. In this paper, we derive a regularizer based on this relative flatness that is easy to compute, fast, efficient, and works with arbitrary loss functions. It requires computing the Hessian only of a single layer of the network, which makes it applicable to large neural networks, and with it avoids an expensive mapping of the loss surface in the vicinity of the model. In an extensive empirical evaluation we show that this relative flatness aware minimization (FAM) improves generalization in a multitude of applications and models, both in finetuning and standard training. We make the code available at github.
Guideline for Trustworthy Artificial Intelligence -- AI Assessment Catalog
Jun 20, 2023Artificial Intelligence (AI) has made impressive progress in recent years and represents a key technology that has a crucial impact on the economy and society. However, it is clear that AI and business models based on it can only reach their full potential if AI applications are developed according to high quality standards and are effectively protected against new AI risks. For instance, AI bears the risk of unfair treatment of individuals when processing personal data e.g., to support credit lending or staff recruitment decisions. The emergence of these new risks is closely linked to the fact that the behavior of AI applications, particularly those based on Machine Learning (ML), is essentially learned from large volumes of data and is not predetermined by fixed programmed rules. Thus, the issue of the trustworthiness of AI applications is crucial and is the subject of numerous major publications by stakeholders in politics, business and society. In addition, there is mutual agreement that the requirements for trustworthy AI, which are often described in an abstract way, must now be made clear and tangible. One challenge to overcome here relates to the fact that the specific quality criteria for an AI application depend heavily on the application context and possible measures to fulfill them in turn depend heavily on the AI technology used. Lastly, practical assessment procedures are needed to evaluate whether specific AI applications have been developed according to adequate quality standards. This AI assessment catalog addresses exactly this point and is intended for two target groups: Firstly, it provides developers with a guideline for systematically making their AI applications trustworthy. Secondly, it guides assessors and auditors on how to examine AI applications for trustworthiness in a structured way.
Plants Don't Walk on the Street: Common-Sense Reasoning for Reliable Semantic Segmentation
Apr 19, 2021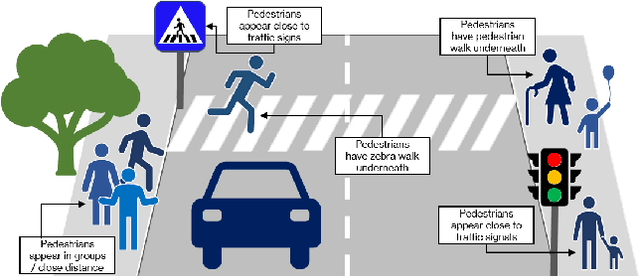

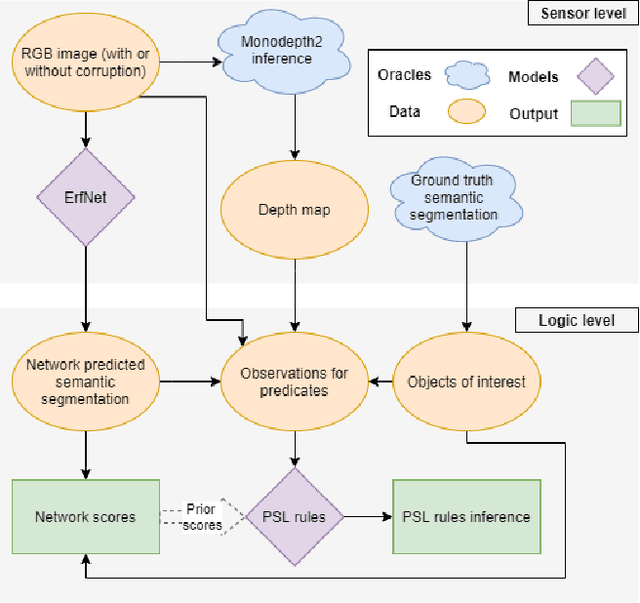

Data-driven sensor interpretation in autonomous driving can lead to highly implausible predictions as can most of the time be verified with common-sense knowledge. However, learning common knowledge only from data is hard and approaches for knowledge integration are an active research area. We propose to use a partly human-designed, partly learned set of rules to describe relations between objects of a traffic scene on a high level of abstraction. In doing so, we improve and robustify existing deep neural networks consuming low-level sensor information. We present an initial study adapting the well-established Probabilistic Soft Logic (PSL) framework to validate and improve on the problem of semantic segmentation. We describe in detail how we integrate common knowledge into the segmentation pipeline using PSL and verify our approach in a set of experiments demonstrating the increase in robustness against several severe image distortions applied to the A2D2 autonomous driving data set.
Novelty Detection in Sequential Data by Informed Clustering and Modeling
Mar 05, 2021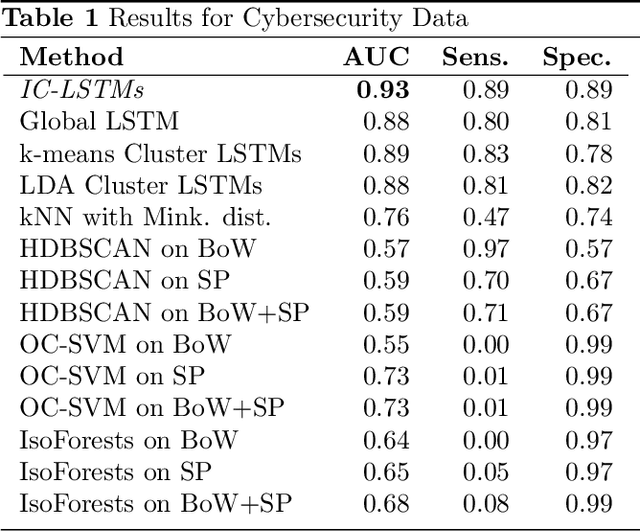

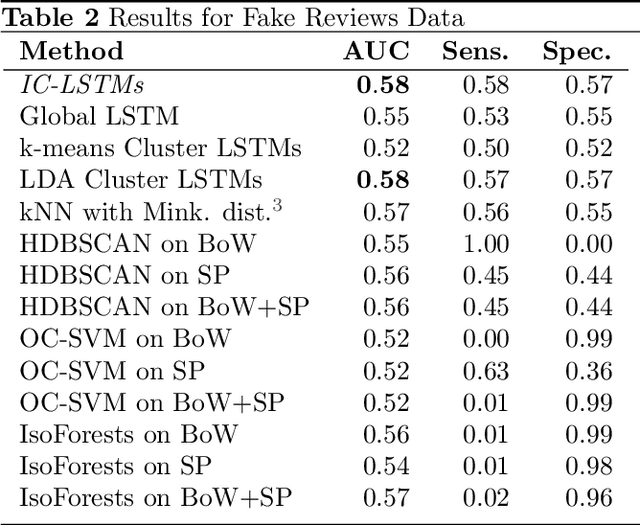
Novelty detection in discrete sequences is a challenging task, since deviations from the process generating the normal data are often small or intentionally hidden. Novelties can be detected by modeling normal sequences and measuring the deviations of a new sequence from the model predictions. However, in many applications data is generated by several distinct processes so that models trained on all the data tend to over-generalize and novelties remain undetected. We propose to approach this challenge through decomposition: by clustering the data we break down the problem, obtaining simpler modeling task in each cluster which can be modeled more accurately. However, this comes at a trade-off, since the amount of training data per cluster is reduced. This is a particular problem for discrete sequences where state-of-the-art models are data-hungry. The success of this approach thus depends on the quality of the clustering, i.e., whether the individual learning problems are sufficiently simpler than the joint problem. While clustering discrete sequences automatically is a challenging and domain-specific task, it is often easy for human domain experts, given the right tools. In this paper, we adapt a state-of-the-art visual analytics tool for discrete sequence clustering to obtain informed clusters from domain experts and use LSTMs to model each cluster individually. Our extensive empirical evaluation indicates that this informed clustering outperforms automatic ones and that our approach outperforms state-of-the-art novelty detection methods for discrete sequences in three real-world application scenarios. In particular, decomposition outperforms a global model despite less training data on each individual cluster.
Resource-Constrained On-Device Learning by Dynamic Averaging
Sep 25, 2020
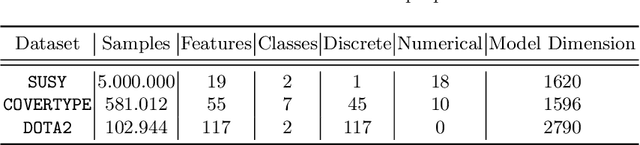
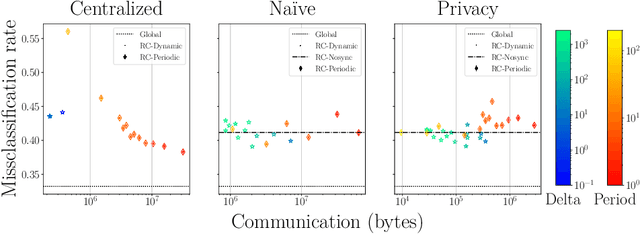
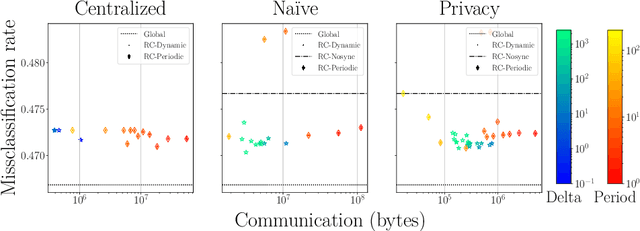
The communication between data-generating devices is partially responsible for a growing portion of the world's power consumption. Thus reducing communication is vital, both, from an economical and an ecological perspective. For machine learning, on-device learning avoids sending raw data, which can reduce communication substantially. Furthermore, not centralizing the data protects privacy-sensitive data. However, most learning algorithms require hardware with high computation power and thus high energy consumption. In contrast, ultra-low-power processors, like FPGAs or micro-controllers, allow for energy-efficient learning of local models. Combined with communication-efficient distributed learning strategies, this reduces the overall energy consumption and enables applications that were yet impossible due to limited energy on local devices. The major challenge is then, that the low-power processors typically only have integer processing capabilities. This paper investigates an approach to communication-efficient on-device learning of integer exponential families that can be executed on low-power processors, is privacy-preserving, and effectively minimizes communication. The empirical evaluation shows that the approach can reach a model quality comparable to a centrally learned regular model with an order of magnitude less communication. Comparing the overall energy consumption, this reduces the required energy for solving the machine learning task by a significant amount.
Feature-Robustness, Flatness and Generalization Error for Deep Neural Networks
Jan 07, 2020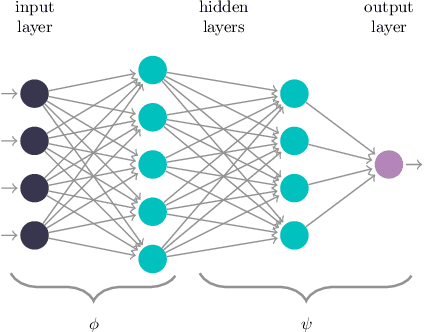

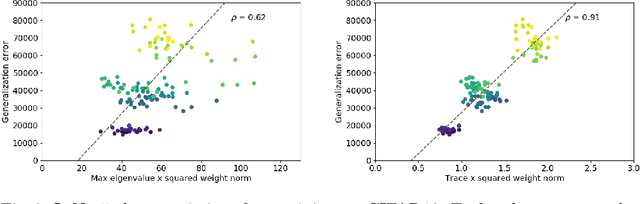

The performance of deep neural networks is often attributed to their automated, task-related feature construction. It remains an open question, though, why this leads to solutions with good generalization, even in cases where the number of parameters is larger than the number of samples. Back in the 90s, Hochreiter and Schmidhuber observed that flatness of the loss surface around a local minimum correlates with low generalization error. For several flatness measures, this correlation has been empirically validated. However, it has recently been shown that existing measures of flatness cannot theoretically be related to generalization: if a network uses ReLU activations, the network function can be reparameterized without changing its output in such a way that flatness is changed almost arbitrarily. This paper proposes a natural modification of existing flatness measures that results in invariance to reparameterization. The proposed measures imply a robustness of the network to changes in the input and the hidden layers. Connecting this feature robustness to generalization leads to a generalized definition of the representativeness of data. With this, the generalization error of a model trained on representative data can be bounded by its feature robustness which depends on our novel flatness measure.