 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and Naming Subgroups with Exceptional Survival Characteristics
Feb 25, 2026In many applications, it is important to identify subpopulations that survive longer or shorter than the rest of the population. In medicine, for example, it allows determining which patients benefit from treatment, and in predictive maintenance, which components are more likely to fail. Existing methods for discovering subgroups with exceptional survival characteristics require restrictive assumptions about the survival model (e.g. proportional hazards), pre-discretized features, and, as they compare average statistics, tend to overlook individual deviations. In this paper, we propose Sysurv, a fully differentiable, non-parametric method that leverages random survival forests to learn individual survival curves, automatically learns conditions and how to combine these into inherently interpretable rules, so as to select subgroups with exceptional survival characteristics. Empirical evaluation on a wide range of datasets and settings, including a case study on cancer data, shows that Sysurv reveals insightful and actionable survival subgroups.
Causal Characterization of Measurement and Mechanistic Anomalies
Jan 30, 2026Root cause analysis of anomalies aims to identify those features that cause the deviation from the normal process. Existing methods ignore, however, that anomalies can arise through two fundamentally different processes: measurement errors, where data was generated normally but one or more values were recorded incorrectly, and mechanism shifts, where the causal process generating the data changed. While measurement errors can often be safely corrected, mechanistic anomalies require careful consideration. We define a causal model that explicitly captures both types by treating outliers as latent interventions on latent ("true") and observed ("measured") variables. We show that they are identifiable, and propose a maximum likelihood estimation approach to put this to practice. Experiments show that our method matches state-of-the-art performance in root cause localization, while it additionally enables accurate classification of anomaly types, and remains robust even when the causal DAG is unknown.
When Flatness Does (Not) Guarantee Adversarial Robustness
Oct 16, 2025Despite their empirical success, neural networks remain vulnerable to small, adversarial perturbations. A longstanding hypothesis suggests that flat minima, regions of low curvature in the loss landscape, offer increased robustness. While intuitive, this connection has remained largely informal and incomplete. By rigorously formalizing the relationship, we show this intuition is only partially correct: flatness implies local but not global adversarial robustness. To arrive at this result, we first derive a closed-form expression for relative flatness in the penultimate layer, and then show we can use this to constrain the variation of the loss in input space. This allows us to formally analyze the adversarial robustness of the entire network. We then show that to maintain robustness beyond a local neighborhood, the loss needs to curve sharply away from the data manifold. We validate our theoretical predictions empirically across architectures and datasets, uncovering the geometric structure that governs adversarial vulnerability, and linking flatness to model confidence: adversarial examples often lie in large, flat regions where the model is confidently wrong. Our results challenge simplified views of flatness and provide a nuanced understanding of its role in robustness.
Seqret: Mining Rule Sets from Event Sequences
May 09, 2025



Summarizing event sequences is a key aspect of data mining. Most existing methods neglect conditional dependencies and focus on discovering sequential patterns only. In this paper, we study the problem of discovering both conditional and unconditional dependencies from event sequence data. We do so by discovering rules of the form $X \rightarrow Y$ where $X$ and $Y$ are sequential patterns. Rules like these are simple to understand and provide a clear description of the relation between the antecedent and the consequent. To discover succinct and non-redundant sets of rules we formalize the problem in terms of the Minimum Description Length principle. As the search space is enormous and does not exhibit helpful structure, we propose the Seqret method to discover high-quality rule sets in practice. Through extensive empirical evaluation we show that unlike the state of the art, Seqret ably recovers the ground truth on synthetic datasets and finds useful rules from real datasets.
Now you see me! A framework for obtaining class-relevant saliency maps
Mar 10, 2025



Neural networks are part of daily-life decision-making, including in high-stakes settings where understanding and transparency are key. Saliency maps have been developed to gain understanding into which input features neural networks use for a specific prediction. Although widely employed, these methods often result in overly general saliency maps that fail to identify the specific information that triggered the classification. In this work, we suggest a framework that allows to incorporate attributions across classes to arrive at saliency maps that actually capture the class-relevant information. On established benchmarks for attribution methods, including the grid-pointing game and randomization-based sanity checks, we show that our framework heavily boosts the performance of standard saliency map approaches. It is, by design, agnostic to model architectures and attribution methods and now allows to identify the distinguishing and shared features used for a model prediction.
SpaceTime: Causal Discovery from Non-Stationary Time Series
Jan 17, 2025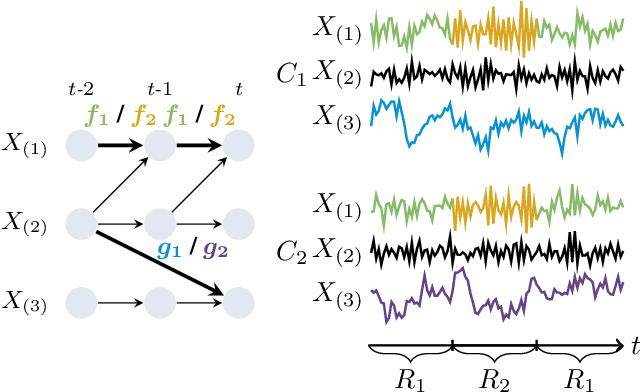
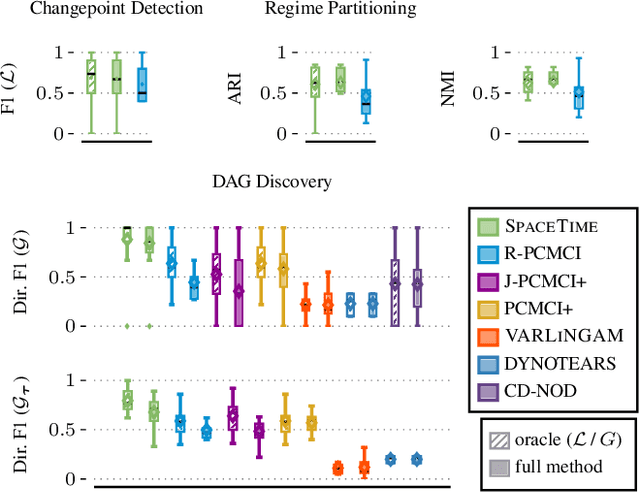
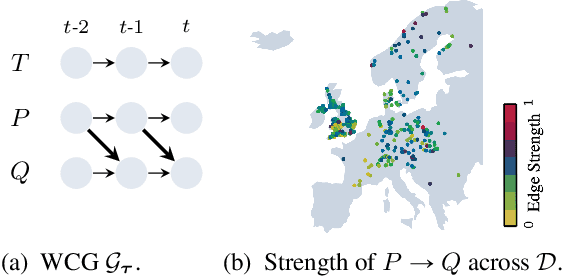
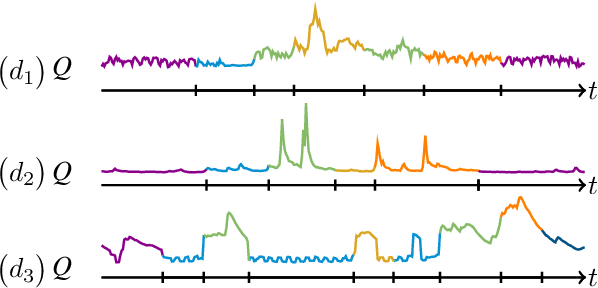
Understanding causality is challenging and often complicated by changing causal relationships over time and across environments. Climate patterns, for example, shift over time with recurring seasonal trends, while also depending on geographical characteristics such as ecosystem variability. Existing methods for discovering causal graphs from time series either assume stationarity, do not permit both temporal and spatial distribution changes, or are unaware of locations with the same causal relationships. In this work, we therefore unify the three tasks of causal graph discovery in the non-stationary multi-context setting, of reconstructing temporal regimes, and of partitioning datasets and time intervals into those where invariant causal relationships hold. To construct a consistent score that forms the basis of our method, we employ the Minimum Description Length principle. Our resulting algorithm SPACETIME simultaneously accounts for heterogeneity across space and non-stationarity over time. Given multiple time series, it discovers regime changepoints and a temporal causal graph using non-parametric functional modeling and kernelized discrepancy testing. We also show that our method provides insights into real-world phenomena such as river-runoff measured at different catchments and biosphere-atmosphere interactions across ecosystems.
Neuro-Symbolic Rule Lists
Nov 10, 2024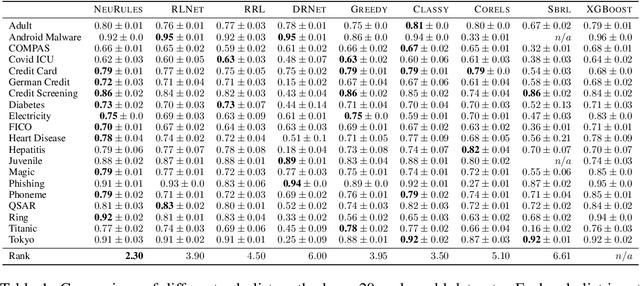
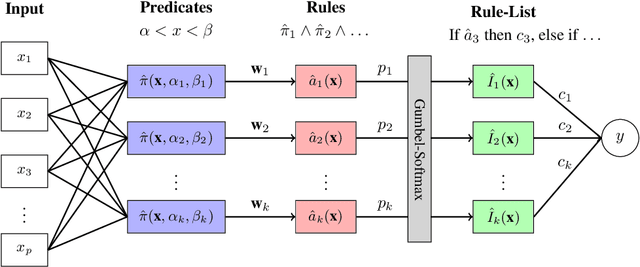
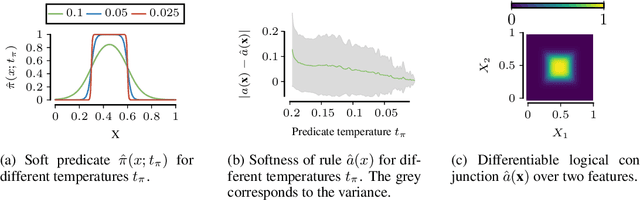
Machine learning models deployed in sensitive areas such as healthcare must be interpretable to ensure accountability and fairness. Rule lists (if Age < 35 $\wedge$ Priors > 0 then Recidivism = True, else if Next Condition . . . ) offer full transparency, making them well-suited for high-stakes decisions. However, learning such rule lists presents significant challenges. Existing methods based on combinatorial optimization require feature pre-discretization and impose restrictions on rule size. Neuro-symbolic methods use more scalable continuous optimization yet place similar pre-discretization constraints and suffer from unstable optimization. To address the existing limitations, we introduce NeuRules, an end-to-end trainable model that unifies discretization, rule learning, and rule order into a single differentiable framework. We formulate a continuous relaxation of the rule list learning problem that converges to a strict rule list through temperature annealing. NeuRules learns both the discretizations of individual features, as well as their combination into conjunctive rules without any pre-processing or restrictions. Extensive experiments demonstrate that NeuRules consistently outperforms both combinatorial and neuro-symbolic methods, effectively learning simple and complex rules, as well as their order, across a wide range of datasets.
Federated Binary Matrix Factorization using Proximal Optimization
Jul 01, 2024Identifying informative components in binary data is an essential task in many research areas, including life sciences, social sciences, and recommendation systems. Boolean matrix factorization (BMF) is a family of methods that performs this task by efficiently factorizing the data. In real-world settings, the data is often distributed across stakeholders and required to stay private, prohibiting the straightforward application of BMF. To adapt BMF to this context, we approach the problem from a federated-learning perspective, while building on a state-of-the-art continuous binary matrix factorization relaxation to BMF that enables efficient gradient-based optimization. We propose to only share the relaxed component matrices, which are aggregated centrally using a proximal operator that regularizes for binary outcomes. We show the convergence of our federated proximal gradient descent algorithm and provide differential privacy guarantees. Our extensive empirical evaluation demonstrates that our algorithm outperforms, in terms of quality and efficacy, federation schemes of state-of-the-art BMF methods on a diverse set of real-world and synthetic data.
The Uncanny Valley: Exploring Adversarial Robustness from a Flatness Perspective
May 27, 2024



Flatness of the loss surface not only correlates positively with generalization but is also related to adversarial robustness, since perturbations of inputs relate non-linearly to perturbations of weights. In this paper, we empirically analyze the relation between adversarial examples and relative flatness with respect to the parameters of one layer. We observe a peculiar property of adversarial examples: during an iterative first-order white-box attack, the flatness of the loss surface measured around the adversarial example first becomes sharper until the label is flipped, but if we keep the attack running it runs into a flat uncanny valley where the label remains flipped. We find this phenomenon across various model architectures and datasets. Our results also extend to large language models (LLMs), but due to the discrete nature of the input space and comparatively weak attacks, the adversarial examples rarely reach a truly flat region. Most importantly, this phenomenon shows that flatness alone cannot explain adversarial robustness unless we can also guarantee the behavior of the function around the examples. We theoretically connect relative flatness to adversarial robustness by bounding the third derivative of the loss surface, underlining the need for flatness in combination with a low global Lipschitz constant for a robust model.
Learning Exceptional Subgroups by End-to-End Maximizing KL-divergence
Feb 20, 2024



Finding and describing sub-populations that are exceptional regarding a target property has important applications in many scientific disciplines, from identifying disadvantaged demographic groups in census data to finding conductive molecules within gold nanoparticles. Current approaches to finding such subgroups require pre-discretized predictive variables, do not permit non-trivial target distributions, do not scale to large datasets, and struggle to find diverse results. To address these limitations, we propose Syflow, an end-to-end optimizable approach in which we leverage normalizing flows to model arbitrary target distributions, and introduce a novel neural layer that results in easily interpretable subgroup descriptions. We demonstrate on synthetic and real-world data, including a case study, that Syflow reliably finds highly exceptional subgroups accompanied by insightful descriptions.