 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and Naming Subgroups with Exceptional Survival Characteristics
Feb 25, 2026In many applications, it is important to identify subpopulations that survive longer or shorter than the rest of the population. In medicine, for example, it allows determining which patients benefit from treatment, and in predictive maintenance, which components are more likely to fail. Existing methods for discovering subgroups with exceptional survival characteristics require restrictive assumptions about the survival model (e.g. proportional hazards), pre-discretized features, and, as they compare average statistics, tend to overlook individual deviations. In this paper, we propose Sysurv, a fully differentiable, non-parametric method that leverages random survival forests to learn individual survival curves, automatically learns conditions and how to combine these into inherently interpretable rules, so as to select subgroups with exceptional survival characteristics. Empirical evaluation on a wide range of datasets and settings, including a case study on cancer data, shows that Sysurv reveals insightful and actionable survival subgroups.
When Flatness Does (Not) Guarantee Adversarial Robustness
Oct 16, 2025Despite their empirical success, neural networks remain vulnerable to small, adversarial perturbations. A longstanding hypothesis suggests that flat minima, regions of low curvature in the loss landscape, offer increased robustness. While intuitive, this connection has remained largely informal and incomplete. By rigorously formalizing the relationship, we show this intuition is only partially correct: flatness implies local but not global adversarial robustness. To arrive at this result, we first derive a closed-form expression for relative flatness in the penultimate layer, and then show we can use this to constrain the variation of the loss in input space. This allows us to formally analyze the adversarial robustness of the entire network. We then show that to maintain robustness beyond a local neighborhood, the loss needs to curve sharply away from the data manifold. We validate our theoretical predictions empirically across architectures and datasets, uncovering the geometric structure that governs adversarial vulnerability, and linking flatness to model confidence: adversarial examples often lie in large, flat regions where the model is confidently wrong. Our results challenge simplified views of flatness and provide a nuanced understanding of its role in robustness.
Now you see me! A framework for obtaining class-relevant saliency maps
Mar 10, 2025



Neural networks are part of daily-life decision-making, including in high-stakes settings where understanding and transparency are key. Saliency maps have been developed to gain understanding into which input features neural networks use for a specific prediction. Although widely employed, these methods often result in overly general saliency maps that fail to identify the specific information that triggered the classification. In this work, we suggest a framework that allows to incorporate attributions across classes to arrive at saliency maps that actually capture the class-relevant information. On established benchmarks for attribution methods, including the grid-pointing game and randomization-based sanity checks, we show that our framework heavily boosts the performance of standard saliency map approaches. It is, by design, agnostic to model architectures and attribution methods and now allows to identify the distinguishing and shared features used for a model prediction.
Neuro-Symbolic Rule Lists
Nov 10, 2024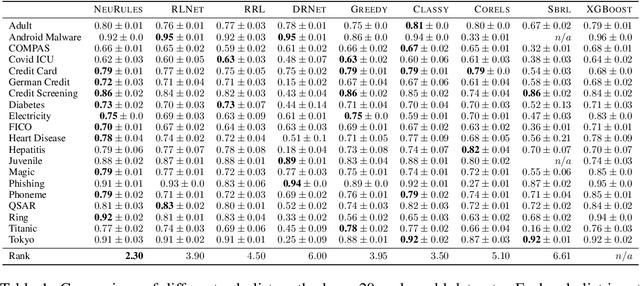
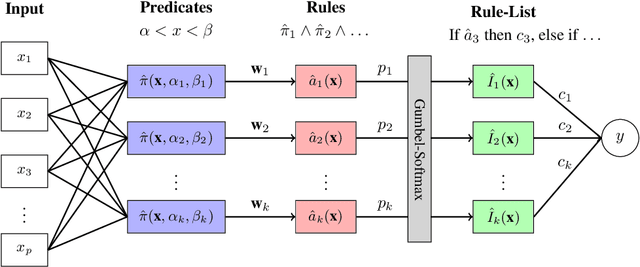
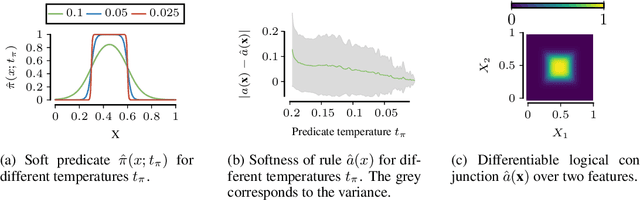
Machine learning models deployed in sensitive areas such as healthcare must be interpretable to ensure accountability and fairness. Rule lists (if Age < 35 $\wedge$ Priors > 0 then Recidivism = True, else if Next Condition . . . ) offer full transparency, making them well-suited for high-stakes decisions. However, learning such rule lists presents significant challenges. Existing methods based on combinatorial optimization require feature pre-discretization and impose restrictions on rule size. Neuro-symbolic methods use more scalable continuous optimization yet place similar pre-discretization constraints and suffer from unstable optimization. To address the existing limitations, we introduce NeuRules, an end-to-end trainable model that unifies discretization, rule learning, and rule order into a single differentiable framework. We formulate a continuous relaxation of the rule list learning problem that converges to a strict rule list through temperature annealing. NeuRules learns both the discretizations of individual features, as well as their combination into conjunctive rules without any pre-processing or restrictions. Extensive experiments demonstrate that NeuRules consistently outperforms both combinatorial and neuro-symbolic methods, effectively learning simple and complex rules, as well as their order, across a wide range of datasets.
The Uncanny Valley: Exploring Adversarial Robustness from a Flatness Perspective
May 27, 2024



Flatness of the loss surface not only correlates positively with generalization but is also related to adversarial robustness, since perturbations of inputs relate non-linearly to perturbations of weights. In this paper, we empirically analyze the relation between adversarial examples and relative flatness with respect to the parameters of one layer. We observe a peculiar property of adversarial examples: during an iterative first-order white-box attack, the flatness of the loss surface measured around the adversarial example first becomes sharper until the label is flipped, but if we keep the attack running it runs into a flat uncanny valley where the label remains flipped. We find this phenomenon across various model architectures and datasets. Our results also extend to large language models (LLMs), but due to the discrete nature of the input space and comparatively weak attacks, the adversarial examples rarely reach a truly flat region. Most importantly, this phenomenon shows that flatness alone cannot explain adversarial robustness unless we can also guarantee the behavior of the function around the examples. We theoretically connect relative flatness to adversarial robustness by bounding the third derivative of the loss surface, underlining the need for flatness in combination with a low global Lipschitz constant for a robust model.
Learning Exceptional Subgroups by End-to-End Maximizing KL-divergence
Feb 20, 2024



Finding and describing sub-populations that are exceptional regarding a target property has important applications in many scientific disciplines, from identifying disadvantaged demographic groups in census data to finding conductive molecules within gold nanoparticles. Current approaches to finding such subgroups require pre-discretized predictive variables, do not permit non-trivial target distributions, do not scale to large datasets, and struggle to find diverse results. To address these limitations, we propose Syflow, an end-to-end optimizable approach in which we leverage normalizing flows to model arbitrary target distributions, and introduce a novel neural layer that results in easily interpretable subgroup descriptions. We demonstrate on synthetic and real-world data, including a case study, that Syflow reliably finds highly exceptional subgroups accompanied by insightful descriptions.
Finding Interpretable Class-Specific Patterns through Efficient Neural Search
Dec 07, 2023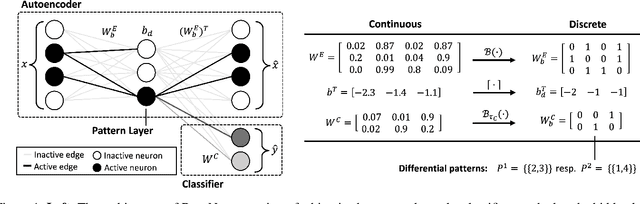
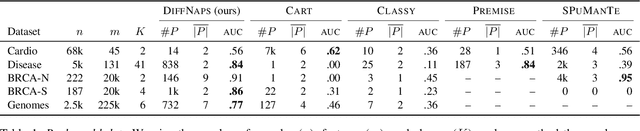
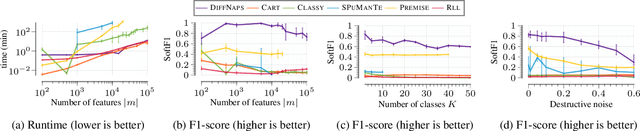
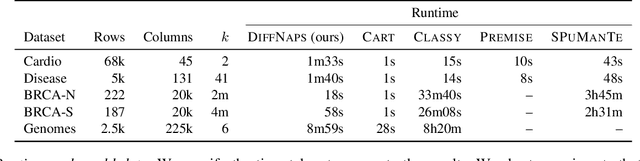
Discovering patterns in data that best describe the differences between classes allows to hypothesize and reason about class-specific mechanisms. In molecular biology, for example, this bears promise of advancing the understanding of cellular processes differing between tissues or diseases, which could lead to novel treatments. To be useful in practice, methods that tackle the problem of finding such differential patterns have to be readily interpretable by domain experts, and scalable to the extremely high-dimensional data. In this work, we propose a novel, inherently interpretable binary neural network architecture DIFFNAPS that extracts differential patterns from data. DiffNaps is scalable to hundreds of thousands of features and robust to noise, thus overcoming the limitations of current state-of-the-art methods in large-scale applications such as in biology. We show on synthetic and real world data, including three biological applications, that, unlike its competitors, DiffNaps consistently yields accurate, succinct, and interpretable class descriptions
On Fragile Features and Batch Normalization in Adversarial Training
Apr 26, 2022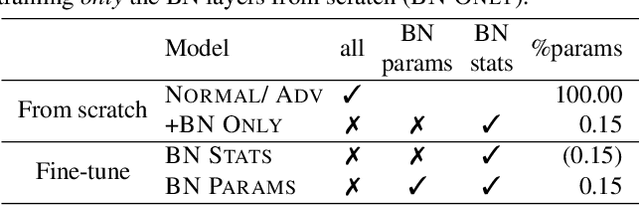
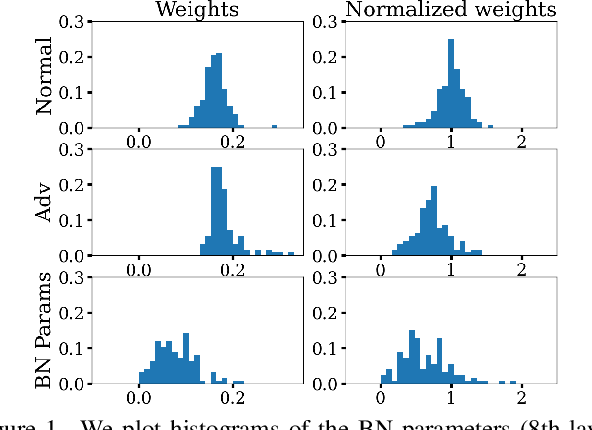
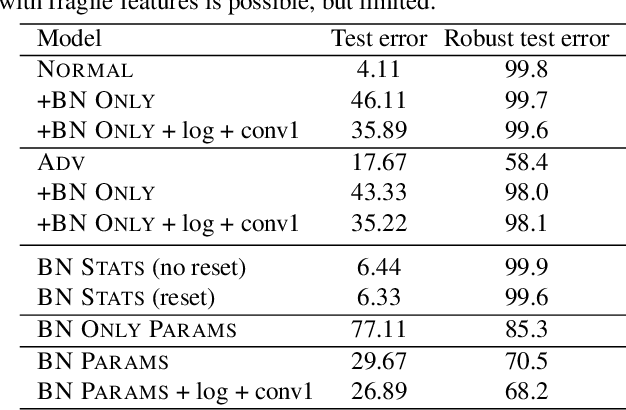
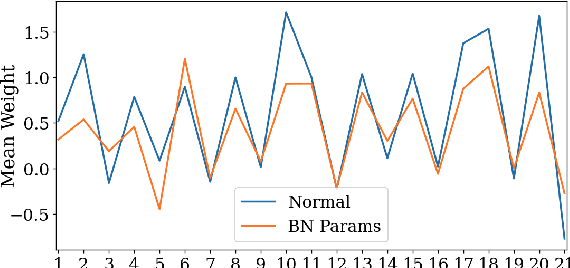
Modern deep learning architecture utilize batch normalization (BN) to stabilize training and improve accuracy. It has been shown that the BN layers alone are surprisingly expressive. In the context of robustness against adversarial examples, however, BN is argued to increase vulnerability. That is, BN helps to learn fragile features. Nevertheless, BN is still used in adversarial training, which is the de-facto standard to learn robust features. In order to shed light on the role of BN in adversarial training, we investigate to what extent the expressiveness of BN can be used to robustify fragile features in comparison to random features. On CIFAR10, we find that adversarially fine-tuning just the BN layers can result in non-trivial adversarial robustness. Adversarially training only the BN layers from scratch, in contrast, is not able to convey meaningful adversarial robustness. Our results indicate that fragile features can be used to learn models with moderate adversarial robustness, while random features cannot