 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Rule Lists
Nov 10, 2024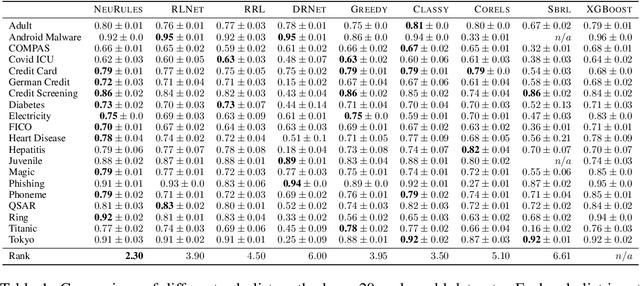
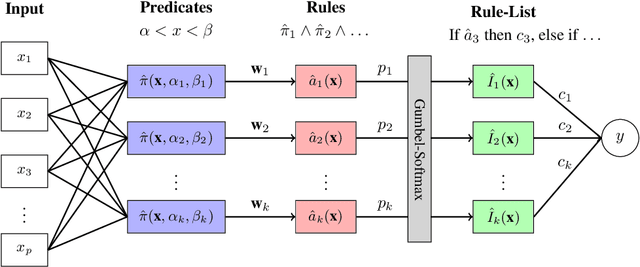
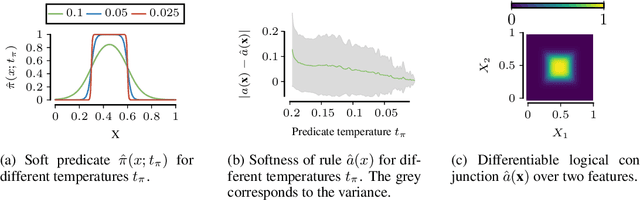
Machine learning models deployed in sensitive areas such as healthcare must be interpretable to ensure accountability and fairness. Rule lists (if Age < 35 $\wedge$ Priors > 0 then Recidivism = True, else if Next Condition . . . ) offer full transparency, making them well-suited for high-stakes decisions. However, learning such rule lists presents significant challenges. Existing methods based on combinatorial optimization require feature pre-discretization and impose restrictions on rule size. Neuro-symbolic methods use more scalable continuous optimization yet place similar pre-discretization constraints and suffer from unstable optimization. To address the existing limitations, we introduce NeuRules, an end-to-end trainable model that unifies discretization, rule learning, and rule order into a single differentiable framework. We formulate a continuous relaxation of the rule list learning problem that converges to a strict rule list through temperature annealing. NeuRules learns both the discretizations of individual features, as well as their combination into conjunctive rules without any pre-processing or restrictions. Extensive experiments demonstrate that NeuRules consistently outperforms both combinatorial and neuro-symbolic methods, effectively learning simple and complex rules, as well as their order, across a wide range of datasets.
Learning Exceptional Subgroups by End-to-End Maximizing KL-divergence
Feb 20, 2024



Finding and describing sub-populations that are exceptional regarding a target property has important applications in many scientific disciplines, from identifying disadvantaged demographic groups in census data to finding conductive molecules within gold nanoparticles. Current approaches to finding such subgroups require pre-discretized predictive variables, do not permit non-trivial target distributions, do not scale to large datasets, and struggle to find diverse results. To address these limitations, we propose Syflow, an end-to-end optimizable approach in which we leverage normalizing flows to model arbitrary target distributions, and introduce a novel neural layer that results in easily interpretable subgroup descriptions. We demonstrate on synthetic and real-world data, including a case study, that Syflow reliably finds highly exceptional subgroups accompanied by insightful descriptions.
Succint Interaction-Aware Explanations
Feb 08, 2024
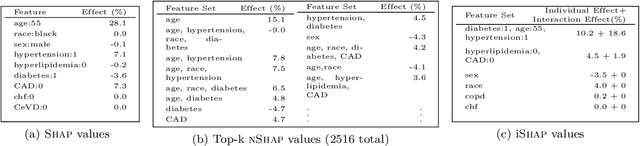
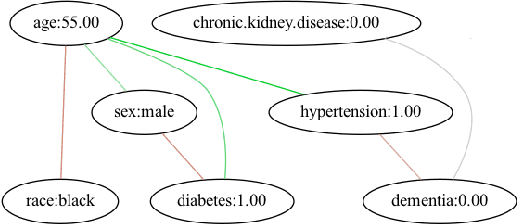

SHAP is a popular approach to explain black-box models by revealing the importance of individual features. As it ignores feature interactions, SHAP explanations can be confusing up to misleading. NSHAP, on the other hand, reports the additive importance for all subsets of features. While this does include all interacting sets of features, it also leads to an exponentially sized, difficult to interpret explanation. In this paper, we propose to combine the best of these two worlds, by partitioning the features into parts that significantly interact, and use these parts to compose a succinct, interpretable, additive explanation. We derive a criterion by which to measure the representativeness of such a partition for a models behavior, traded off against the complexity of the resulting explanation. To efficiently find the best partition out of super-exponentially many, we show how to prune sub-optimal solutions using a statistical test, which not only improves runtime but also helps to detect spurious interactions. Experiments on synthetic and real world data show that our explanations are both more accurate resp. more easily interpretable than those of SHAP and NSHAP.
CD2 : Combined Distances of Contrast Distributions for the Assessment of Perceptual Quality of Image Processing
Nov 18, 2019



The quality of visual input is very important for both human and machine perception. Consequently many processing techniques exist that deal with different distortions. Usually image processing is applied freely and lacks redundancy regarding safety. We propose a novel image comparison method called the Combined Distances of Contrast Distributions (CD2) to protect against errors that arise during processing. Based on the distribution of image contrasts a new reduced-reference image quality assessment (IQA) method is introduced. By combining various distance functions excellent performance on IQA benchmarks is achieved with only a small data and computation overhead.