 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideline for Trustworthy Artificial Intelligence -- AI Assessment Catalog
Jun 20, 2023Artificial Intelligence (AI) has made impressive progress in recent years and represents a key technology that has a crucial impact on the economy and society. However, it is clear that AI and business models based on it can only reach their full potential if AI applications are developed according to high quality standards and are effectively protected against new AI risks. For instance, AI bears the risk of unfair treatment of individuals when processing personal data e.g., to support credit lending or staff recruitment decisions. The emergence of these new risks is closely linked to the fact that the behavior of AI applications, particularly those based on Machine Learning (ML), is essentially learned from large volumes of data and is not predetermined by fixed programmed rules. Thus, the issue of the trustworthiness of AI applications is crucial and is the subject of numerous major publications by stakeholders in politics, business and society. In addition, there is mutual agreement that the requirements for trustworthy AI, which are often described in an abstract way, must now be made clear and tangible. One challenge to overcome here relates to the fact that the specific quality criteria for an AI application depend heavily on the application context and possible measures to fulfill them in turn depend heavily on the AI technology used. Lastly, practical assessment procedures are needed to evaluate whether specific AI applications have been developed according to adequate quality standards. This AI assessment catalog addresses exactly this point and is intended for two target groups: Firstly, it provides developers with a guideline for systematically making their AI applications trustworthy. Secondly, it guides assessors and auditors on how to examine AI applications for trustworthiness in a structured way.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
Plants Don't Walk on the Street: Common-Sense Reasoning for Reliable Semantic Segmentation
Apr 19, 2021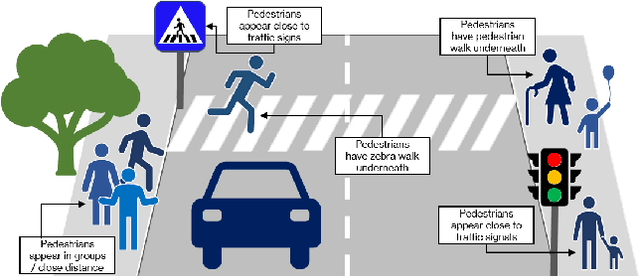

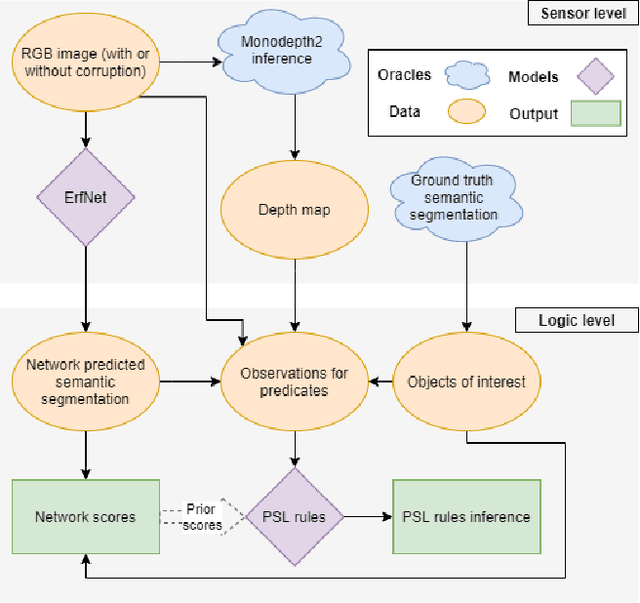

Data-driven sensor interpretation in autonomous driving can lead to highly implausible predictions as can most of the time be verified with common-sense knowledge. However, learning common knowledge only from data is hard and approaches for knowledge integration are an active research area. We propose to use a partly human-designed, partly learned set of rules to describe relations between objects of a traffic scene on a high level of abstraction. In doing so, we improve and robustify existing deep neural networks consuming low-level sensor information. We present an initial study adapting the well-established Probabilistic Soft Logic (PSL) framework to validate and improve on the problem of semantic segmentation. We describe in detail how we integrate common knowledge into the segmentation pipeline using PSL and verify our approach in a set of experiments demonstrating the increase in robustness against several severe image distortions applied to the A2D2 autonomous driving data set.