 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Systematic Weaknesses in Vision Models along Predefined Human-Understandable Dimensions
Feb 17, 2025Studying systematic weaknesses of DNNs has gained prominence in the last few years with the rising focus on building safe AI systems. Slice discovery methods (SDMs) are prominent algorithmic approaches for finding such systematic weaknesses. They identify top-k semantically coherent slices/subsets of data where a DNN-under-test has low performance. For being directly useful, e.g., as evidences in a safety argumentation, slices should be aligned with human-understandable (safety-relevant) dimensions, which, for example, are defined by safety and domain experts as parts of the operational design domain (ODD). While straightforward for structured data, the lack of semantic metadata makes these investigations challenging for unstructured data. Therefore, we propose a complete workflow which combines contemporary foundation models with algorithms for combinatorial search that consider structured data and DNN errors for finding systematic weaknesses in images. In contrast to existing approaches, ours identifies weak slices that are in line with predefined human-understandable dimensions. As the workflow includes foundation models, its intermediate and final results may not always be exact. Therefore, we build into our workflow an approach to address the impact of noisy metadata. We evaluate our approach w.r.t. its quality on four popular computer vision datasets, including autonomous driving datasets like Cityscapes, BDD100k, and RailSem19, while using multiple state-of-the-art models as DNNs-under-test.
Assessing Systematic Weaknesses of DNNs using Counterfactuals
Aug 03, 2023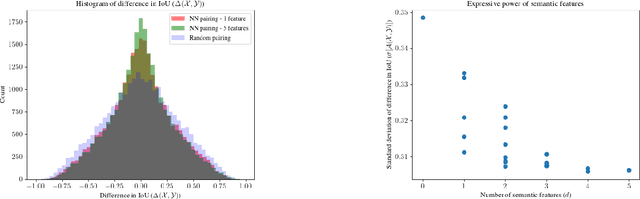
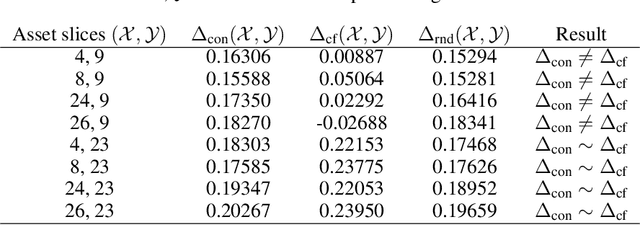
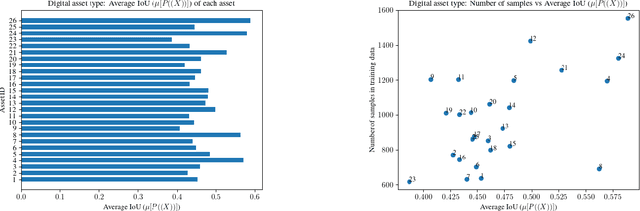

With the advancement of DNNs into safety-critical applications, testing approaches for such models have gained more attention. A current direction is the search for and identification of systematic weaknesses that put safety assumptions based on average performance values at risk. Such weaknesses can take on the form of (semantically coherent) subsets or areas in the input space where a DNN performs systematically worse than its expected average. However, it is non-trivial to attribute the reason for such observed low performances to the specific semantic features that describe the subset. For instance, inhomogeneities within the data w.r.t. other (non-considered) attributes might distort results. However, taking into account all (available) attributes and their interaction is often computationally highly expensive. Inspired by counterfactual explanations, we propose an effective and computationally cheap algorithm to validate the semantic attribution of existing subsets, i.e., to check whether the identified attribute is likely to have caused the degraded performance. We demonstrate this approach on an example from the autonomous driving domain using highly annotated simulated data, where we show for a semantic segmentation model that (i) performance differences among the different pedestrian assets exist, but (ii) only in some cases is the asset type itself the reason for this reduction in the performance.
Guideline for Trustworthy Artificial Intelligence -- AI Assessment Catalog
Jun 20, 2023Artificial Intelligence (AI) has made impressive progress in recent years and represents a key technology that has a crucial impact on the economy and society. However, it is clear that AI and business models based on it can only reach their full potential if AI applications are developed according to high quality standards and are effectively protected against new AI risks. For instance, AI bears the risk of unfair treatment of individuals when processing personal data e.g., to support credit lending or staff recruitment decisions. The emergence of these new risks is closely linked to the fact that the behavior of AI applications, particularly those based on Machine Learning (ML), is essentially learned from large volumes of data and is not predetermined by fixed programmed rules. Thus, the issue of the trustworthiness of AI applications is crucial and is the subject of numerous major publications by stakeholders in politics, business and society. In addition, there is mutual agreement that the requirements for trustworthy AI, which are often described in an abstract way, must now be made clear and tangible. One challenge to overcome here relates to the fact that the specific quality criteria for an AI application depend heavily on the application context and possible measures to fulfill them in turn depend heavily on the AI technology used. Lastly, practical assessment procedures are needed to evaluate whether specific AI applications have been developed according to adequate quality standards. This AI assessment catalog addresses exactly this point and is intended for two target groups: Firstly, it provides developers with a guideline for systematically making their AI applications trustworthy. Secondly, it guides assessors and auditors on how to examine AI applications for trustworthiness in a structured way.
A Survey on Uncertainty Toolkits for Deep Learning
May 02, 2022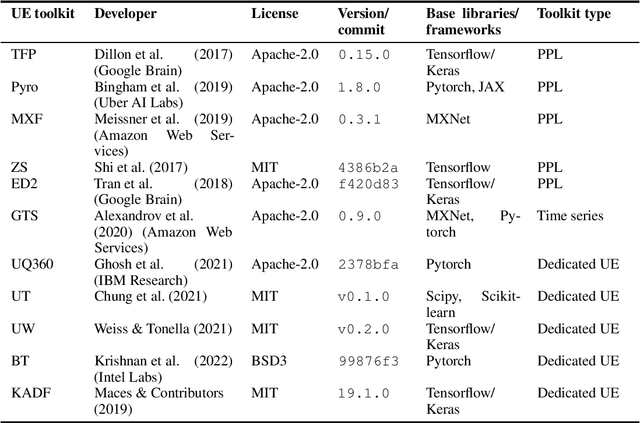
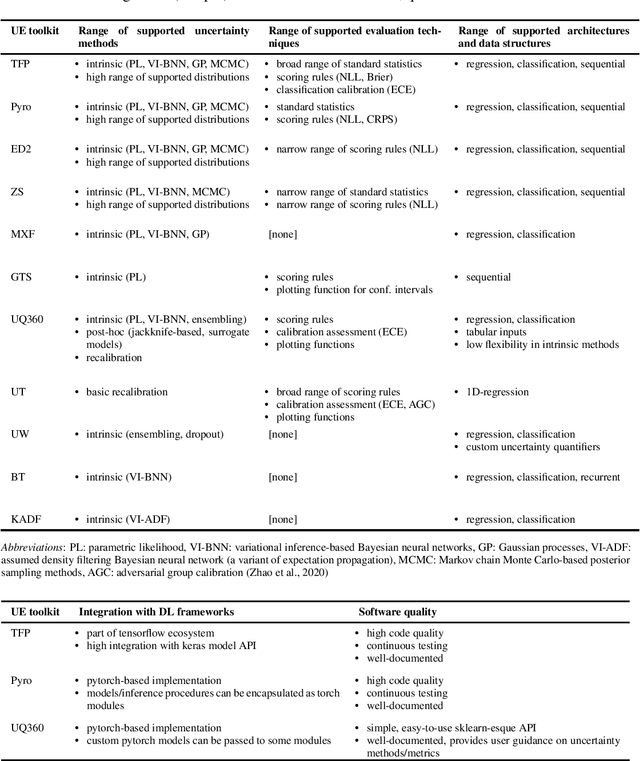
The success of deep learning (DL) fostered the creation of unifying frameworks such as tensorflow or pytorch as much as it was driven by their creation in return. Having common building blocks facilitates the exchange of, e.g., models or concepts and makes developments easier replicable. Nonetheless, robust and reliable evaluation and assessment of DL models has often proven challenging. This is at odds with their increasing safety relevance, which recently culminated in the field of "trustworthy ML". We believe that, among others, further unification of evaluation and safeguarding methodologies in terms of toolkits, i.e., small and specialized framework derivatives, might positively impact problems of trustworthiness as well as reproducibility. To this end, we present the first survey on toolkits for uncertainty estimation (UE) in DL, as UE forms a cornerstone in assessing model reliability. We investigate 11 toolkits with respect to modeling and evaluation capabilities, providing an in-depth comparison for the three most promising ones, namely Pyro, Tensorflow Probability, and Uncertainty Quantification 360. While the first two provide a large degree of flexibility and seamless integration into their respective framework, the last one has the larger methodological scope.
Tailored Uncertainty Estimation for Deep Learning Systems
Apr 29, 2022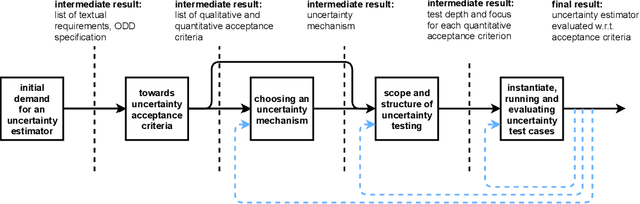

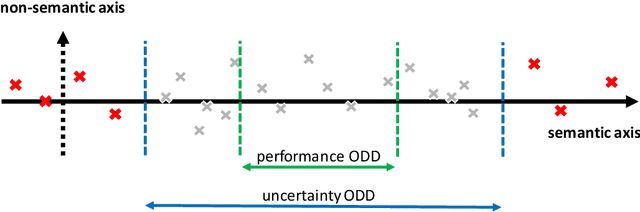
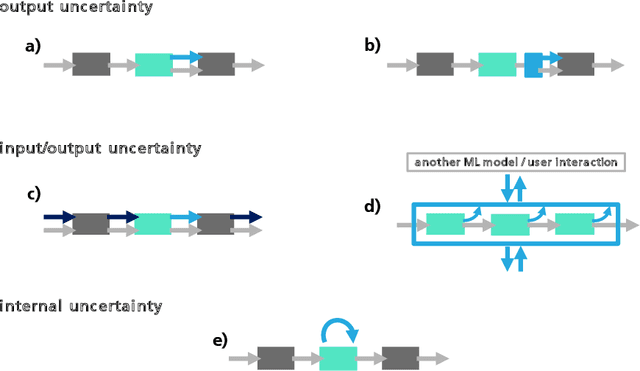
Uncertainty estimation bears the potential to make deep learning (DL) systems more reliable. Standard techniques for uncertainty estimation, however, come along with specific combinations of strengths and weaknesses, e.g., with respect to estimation quality, generalization abilities and computational complexity. To actually harness the potential of uncertainty quantification, estimators are required whose properties closely match the requirements of a given use case. In this work, we propose a framework that, firstly, structures and shapes these requirements, secondly, guides the selection of a suitable uncertainty estimation method and, thirdly, provides strategies to validate this choice and to uncover structural weaknesses. By contributing tailored uncertainty estimation in this sense, our framework helps to foster trustworthy DL systems. Moreover, it anticipates prospective machine learning regulations that require, e.g., in the EU, evidences for the technical appropriateness of machine learning systems. Our framework provides such evidences for system components modeling uncertainty.
Validation of Simulation-Based Testing: Bypassing Domain Shift with Label-to-Image Synthesis
Jun 10, 2021
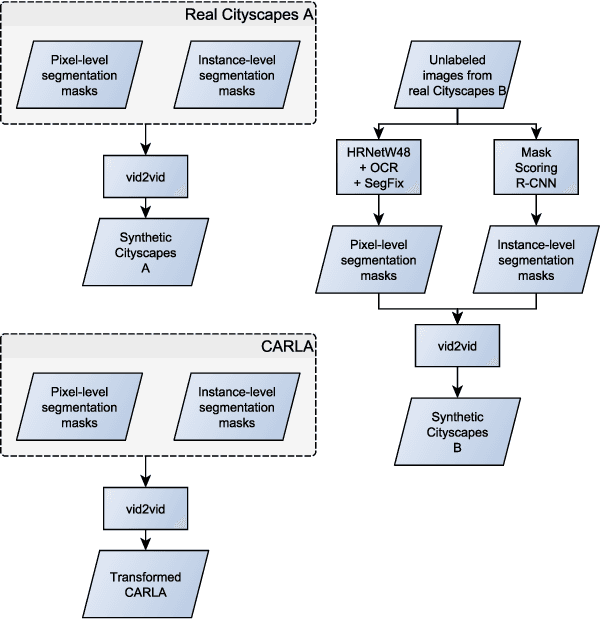


Many machine learning applications can benefit from simulated data for systematic validation - in particular if real-life data is difficult to obtain or annotate. However, since simulations are prone to domain shift w.r.t. real-life data, it is crucial to verify the transferability of the obtained results. We propose a novel framework consisting of a generative label-to-image synthesis model together with different transferability measures to inspect to what extent we can transfer testing results of semantic segmentation models from synthetic data to equivalent real-life data. With slight modifications, our approach is extendable to, e.g., general multi-class classification tasks. Grounded on the transferability analysis, our approach additionally allows for extensive testing by incorporating controlled simulations. We validate our approach empirically on a semantic segmentation task on driving scenes. Transferability is tested using correlation analysis of IoU and a learned discriminator. Although the latter can distinguish between real-life and synthetic tests, in the former we observe surprisingly strong correlations of 0.7 for both cars and pedestrians.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
Patch Shortcuts: Interpretable Proxy Models Efficiently Find Black-Box Vulnerabilities
Apr 22, 2021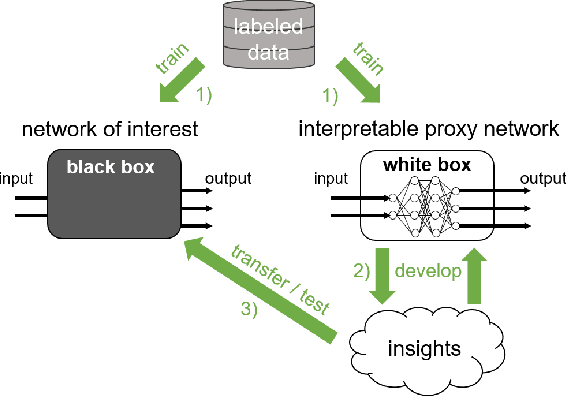
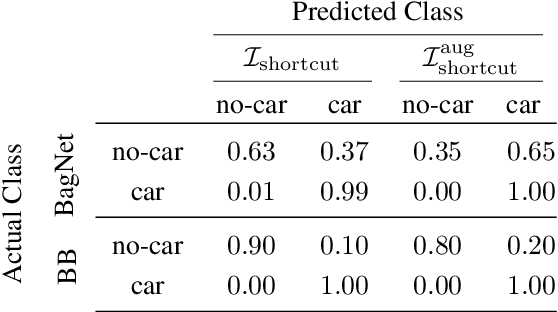

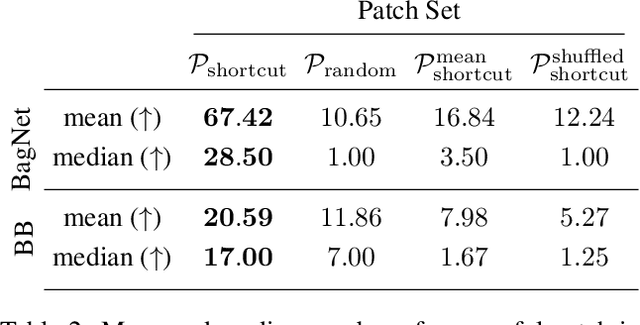
An important pillar for safe machine learning (ML) is the systematic mitigation of weaknesses in neural networks to afford their deployment in critical applications. An ubiquitous class of safety risks are learned shortcuts, i.e. spurious correlations a network exploits for its decisions that have no semantic connection to the actual task. Networks relying on such shortcuts bear the risk of not generalizing well to unseen inputs. Explainability methods help to uncover such network vulnerabilities. However, many of these techniques are not directly applicable if access to the network is constrained, in so-called black-box setups. These setups are prevalent when using third-party ML components. To address this constraint, we present an approach to detect learned shortcuts using an interpretable-by-design network as a proxy to the black-box model of interest. Leveraging the proxy's guarantees on introspection we automatically extract candidates for learned shortcuts. Their transferability to the black box is validated in a systematic fashion. Concretely, as proxy model we choose a BagNet, which bases its decisions purely on local image patches. We demonstrate on the autonomous driving dataset A2D2 that extracted patch shortcuts significantly influence the black box model. By efficiently identifying such patch-based vulnerabilities, we contribute to safer ML models.
Plants Don't Walk on the Street: Common-Sense Reasoning for Reliable Semantic Segmentation
Apr 19, 2021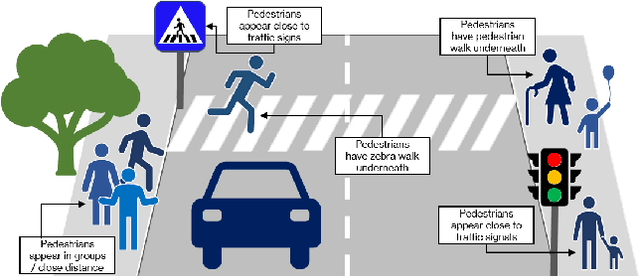

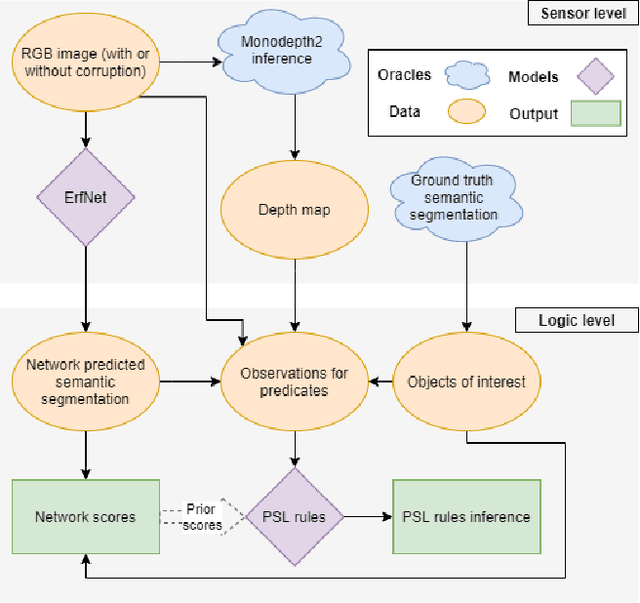

Data-driven sensor interpretation in autonomous driving can lead to highly implausible predictions as can most of the time be verified with common-sense knowledge. However, learning common knowledge only from data is hard and approaches for knowledge integration are an active research area. We propose to use a partly human-designed, partly learned set of rules to describe relations between objects of a traffic scene on a high level of abstraction. In doing so, we improve and robustify existing deep neural networks consuming low-level sensor information. We present an initial study adapting the well-established Probabilistic Soft Logic (PSL) framework to validate and improve on the problem of semantic segmentation. We describe in detail how we integrate common knowledge into the segmentation pipeline using PSL and verify our approach in a set of experiments demonstrating the increase in robustness against several severe image distortions applied to the A2D2 autonomous driving data set.
A Novel Regression Loss for Non-Parametric Uncertainty Optimization
Jan 07, 2021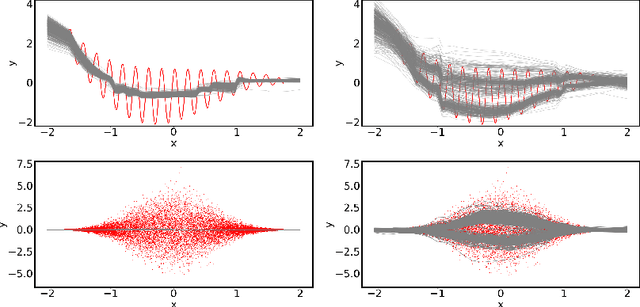
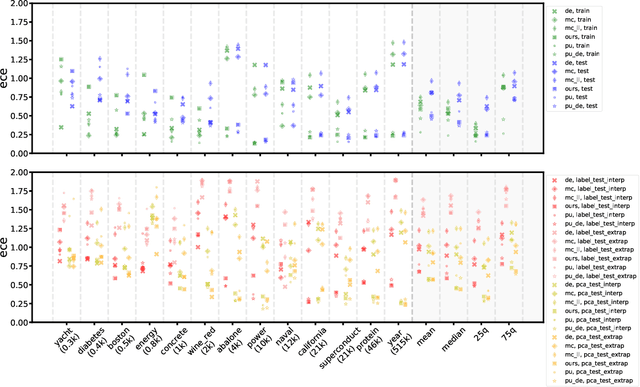
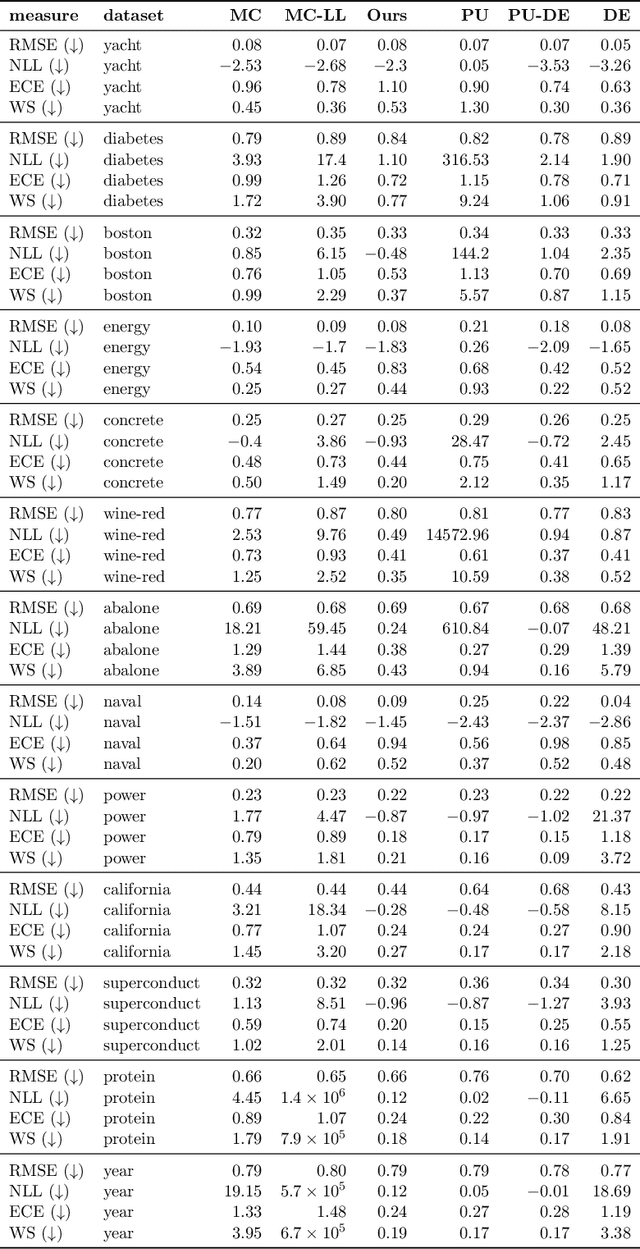
Quantification of uncertainty is one of the most promising approaches to establish safe machine learning. Despite its importance, it is far from being generally solved, especially for neural networks. One of the most commonly used approaches so far is Monte Carlo dropout, which is computationally cheap and easy to apply in practice. However, it can underestimate the uncertainty. We propose a new objective, referred to as second-moment loss (SML), to address this issue. While the full network is encouraged to model the mean, the dropout networks are explicitly used to optimize the model variance. We intensively study the performance of the new objective on various UCI regression datasets. Comparing to the state-of-the-art of deep ensembles, SML leads to comparable prediction accuracies and uncertainty estimates while only requiring a single model. Under distribution shift, we observe moderate improvements. As a side result, we introduce an intuitive Wasserstein distance-based uncertainty measure that is non-saturating and thus allows to resolve quality differences between any two uncertainty estimates.