 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization by Adaptation: Diffusion-Based Domain Extension for Domain-Generalized Semantic Segmentation
Dec 04, 2023When models, e.g., for semantic segmentation, are applied to images that are vastly different from training data, the performance will drop significantly. Domain adaptation methods try to overcome this issue, but need samples from the target domain. However, this might not always be feasible for various reasons and therefore domain generalization methods are useful as they do not require any target data. We present a new diffusion-based domain extension (DIDEX) method and employ a diffusion model to generate a pseudo-target domain with diverse text prompts. In contrast to existing methods, this allows to control the style and content of the generated images and to introduce a high diversity. In a second step, we train a generalizing model by adapting towards this pseudo-target domain. We outperform previous approaches by a large margin across various datasets and architectures without using any real data. For the generalization from GTA5, we improve state-of-the-art mIoU performance by 3.8% absolute on average and for SYNTHIA by 11.8% absolute, marking a big step for the generalization performance on these benchmarks. Code is available at https://github.com/JNiemeijer/DIDEX
Survey on Unsupervised Domain Adaptation for Semantic Segmentation for Visual Perception in Automated Driving
Apr 24, 2023Deep neural networks (DNNs) have proven their capabilities in many areas in the past years, such as robotics, or automated driving, enabling technological breakthroughs. DNNs play a significant role in environment perception for the challenging application of automated driving and are employed for tasks such as detection, semantic segmentation, and sensor fusion. Despite this progress and tremendous research efforts, several issues still need to be addressed that limit the applicability of DNNs in automated driving. The bad generalization of DNNs to new, unseen domains is a major problem on the way to a safe, large-scale application, because manual annotation of new domains is costly, particularly for semantic segmentation. For this reason, methods are required to adapt DNNs to new domains without labeling effort. The task, which these methods aim to solve is termed unsupervised domain adaptation (UDA). While several different domain shifts can challenge DNNs, the shift between synthetic and real data is of particular importance for automated driving, as it allows the use of simulation environments for DNN training. In this work, we present an overview of the current state of the art in this field of research. We categorize and explain the different approaches for UDA. The number of considered publications is larger than any other survey on this topic. The scope of this survey goes far beyond the description of the UDA state-of-the-art. Based on our large data and knowledge base, we present a quantitative comparison of the approaches and use the observations to point out the latest trends in this field. In the following, we conduct a critical analysis of the state-of-the-art and highlight promising future research directions. With this survey, we aim to facilitate UDA research further and encourage scientists to exploit novel research directions to generalize DNNs better.
Augmentation-based Domain Generalization for Semantic Segmentation
Apr 24, 2023


Unsupervised Domain Adaptation (UDA) and domain generalization (DG) are two research areas that aim to tackle the lack of generalization of Deep Neural Networks (DNNs) towards unseen domains. While UDA methods have access to unlabeled target images, domain generalization does not involve any target data and only learns generalized features from a source domain. Image-style randomization or augmentation is a popular approach to improve network generalization without access to the target domain. Complex methods are often proposed that disregard the potential of simple image augmentations for out-of-domain generalization. For this reason, we systematically study the in- and out-of-domain generalization capabilities of simple, rule-based image augmentations like blur, noise, color jitter and many more. Based on a full factorial design of experiment design we provide a systematic statistical evaluation of augmentations and their interactions. Our analysis provides both, expected and unexpected, outcomes. Expected, because our experiments confirm the common scientific standard that combination of multiple different augmentations out-performs single augmentations. Unexpected, because combined augmentations perform competitive to state-of-the-art domain generalization approaches, while being significantly simpler and without training overhead. On the challenging synthetic-to-real domain shift between Synthia and Cityscapes we reach 39.5% mIoU compared to 40.9% mIoU of the best previous work. When additionally employing the recent vision transformer architecture DAFormer we outperform these benchmarks with a performance of 44.2% mIoU
Validation of Simulation-Based Testing: Bypassing Domain Shift with Label-to-Image Synthesis
Jun 10, 2021
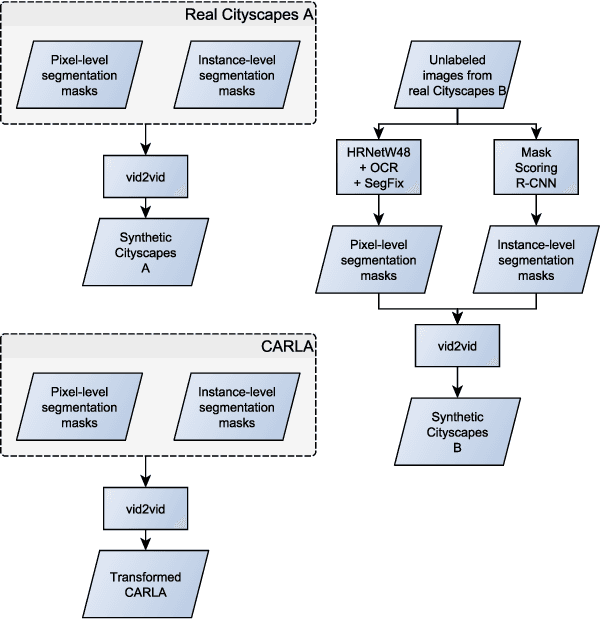


Many machine learning applications can benefit from simulated data for systematic validation - in particular if real-life data is difficult to obtain or annotate. However, since simulations are prone to domain shift w.r.t. real-life data, it is crucial to verify the transferability of the obtained results. We propose a novel framework consisting of a generative label-to-image synthesis model together with different transferability measures to inspect to what extent we can transfer testing results of semantic segmentation models from synthetic data to equivalent real-life data. With slight modifications, our approach is extendable to, e.g., general multi-class classification tasks. Grounded on the transferability analysis, our approach additionally allows for extensive testing by incorporating controlled simulations. We validate our approach empirically on a semantic segmentation task on driving scenes. Transferability is tested using correlation analysis of IoU and a learned discriminator. Although the latter can distinguish between real-life and synthetic tests, in the former we observe surprisingly strong correlations of 0.7 for both cars and pedestrians.
Self-Supervised Domain Mismatch Estimation for Autonomous Perception
Jun 15, 2020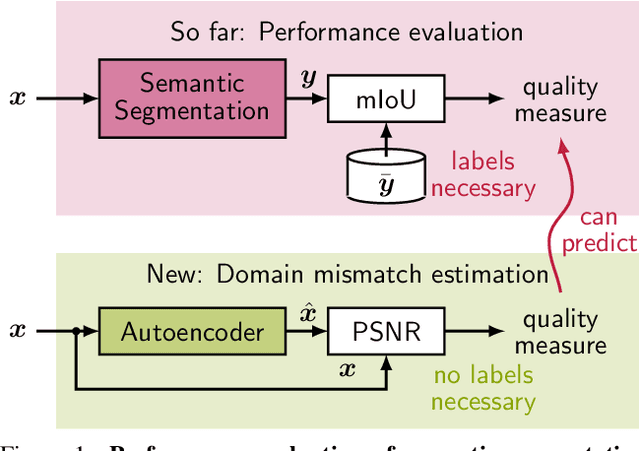
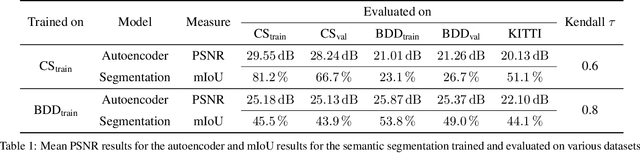
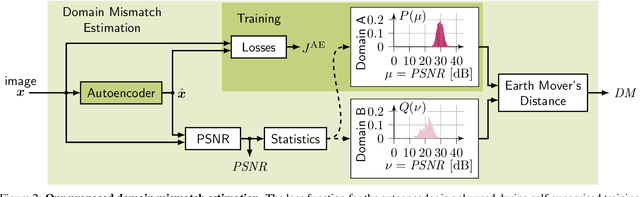
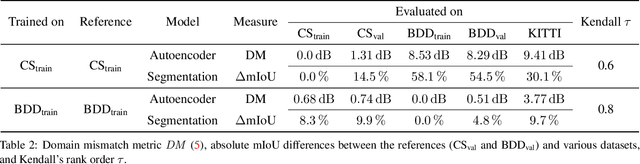
Autonomous driving requires self awareness of its perception functions. Technically spoken, this can be realized by observers, which monitor the performance indicators of various perception modules. In this work we choose, exemplarily, a semantic segmentation to be monitored, and propose an autoencoder, trained in a self-supervised fashion on the very same training data as the semantic segmentation to be monitored. While the autoencoder's image reconstruction performance (PSNR) during online inference shows already a good predictive power w.r.t. semantic segmentation performance, we propose a novel domain mismatch metric DM as the earth mover's distance between a pre-stored PSNR distribution on training (source) data, and an online-acquired PSNR distribution on any inference (target) data. We are able to show by experiments that the DM metric has a strong rank order correlation with the semantic segmentation within its functional scope. We also propose a training domain-dependent threshold for the DM metric to define this functional scope.
GAN- vs. JPEG2000 Image Compression for Distributed Automotive Perception: Higher Peak SNR Does Not Mean Better Semantic Segmentation
Feb 12, 2019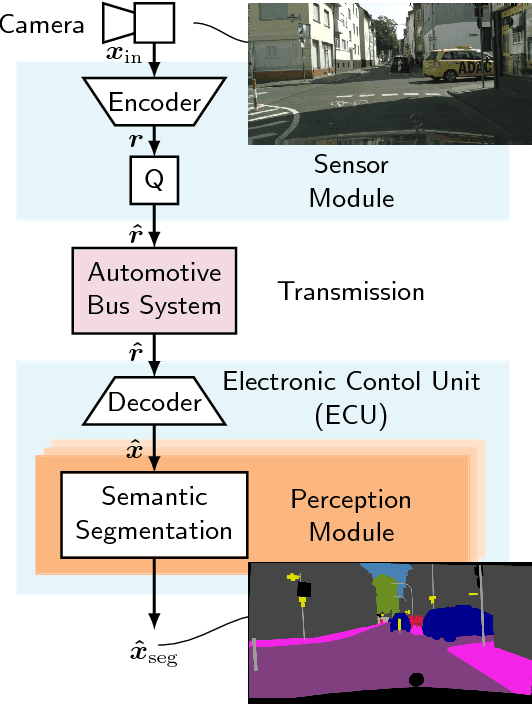
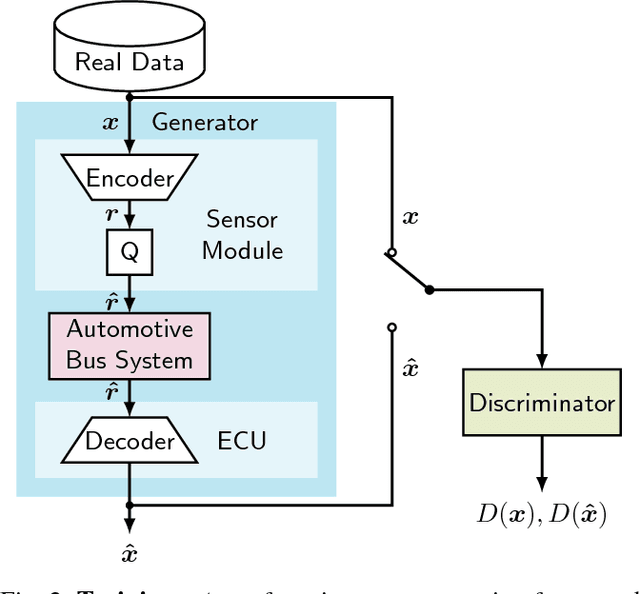
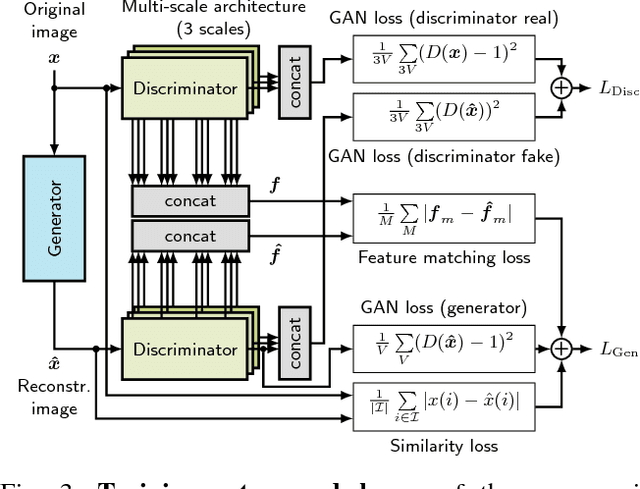

The high amount of sensors required for autonomous driving poses enormous challenges on the capacity of automotive bus systems. There is a need to understand tradeoffs between bitrate and perception performance. In this paper, we compare the image compression standards JPEG, JPEG2000, and WebP to a modern encoder/decoder image compression approach based on generative adversarial networks (GANs). We evaluate both the pure compression performance using typical metrics such as peak signal-to-noise ratio (PSNR), structural similarity (SSIM) and others, but also the performance of a subsequent perception function, namely a semantic segmentation (characterized by the mean intersection over union (mIoU) measure). Not surprisingly, for all investigated compression methods, a higher bitrate means better results in all investigated quality metrics. Interestingly, however, we show that the semantic segmentation mIoU of the GAN autoencoder in the highly relevant low-bitrate regime (at 0.0625 bit/pixel) is better by 3.9% absolute than JPEG2000, although the latter still is considerably better in terms of PSNR (5.91 dB difference). This effect can greatly be enlarged by training the semantic segmentation model with images originating from the decoder, so that the mIoU using the segmentation model trained by GAN reconstructions exceeds the use of the model trained with original images by almost 20% absolute. We conclude that distributed perception in future autonomous driving will most probably not provide a solution to the automotive bus capacity bottleneck by using standard compression schemes such as JPEG2000, but requires modern coding approaches, with the GAN encoder/decoder method being a promising candidate.