 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attack and Disturbance Detection by Hadamard-Coded Output Representations for Object Detection and Semantic Segmentation
Jun 08, 2026Conventional one-hot encodings often yield poorly calibrated models, being overconfident under attack, and letting entropy-based detection algorithms fail. Previous image classification works have demonstrated that Hadamard-coded output representations can improve adversarial robustness. However, attempts to integrate Hadamard codes into semantic segmentation fall far behind state-of-the-art models in mean intersection-over-union performance. Regarding object detection, such output encodings have not yet been investigated at all. Further, no prior art addressed intrinsic codeword inconsistencies or actually exploited intrinsic codeword redundancy. Accordingly, we first derive a novel decoding procedure for Hadamard codewords towards optimal class-wise probabilities, solving the underlying optimization problem by using the projection onto the probability simplex. Second, our optimization delivers a measure of prediction inconsistency. Third, we are the first to show how to exploit these inconsistencies for adversarial attack and disturbance detection. Fourth, we introduce HadamardNet, a framework employing Hadamard codes as output representations for semantic segmentation and object detection models and tasks. We conduct a comprehensive evaluation both on disturbances and adversarial attacks, achieving state-of-the-art perturbation detection performance for both tasks in only a single detection pass, while delivering equivalent or close-by reference performance on clean data.
Efficient Multi-View 3D Object Detection by Dynamic Token Selection and Fine-Tuning
Apr 15, 2026Existing multi-view three-dimensional (3D) object detection approaches widely adopt large-scale pre-trained vision transformer (ViT)-based foundation models as backbones, being computationally complex. To address this problem, current state-of-the-art (SOTA) \texttt{ToC3D} for efficient multi-view ViT-based 3D object detection employs ego-motion-based relevant token selection. However, there are two key limitations: (1) The fixed layer-individual token selection ratios limit computational efficiency during both training and inference. (2) Full end-to-end retraining of the ViT backbone is required for the multi-view 3D object detection method. In this work, we propose an image token compensator combined with a token selection for ViT backbones to accelerate multi-view 3D object detection. Unlike \texttt{ToC3D}, our approach enables dynamic layer-wise token selection within the ViT backbone. Furthermore, we introduce a parameter-efficient fine-tuning strategy, which trains only the proposed modules, thereby reducing the number of fine-tuned parameters from more than $300$ million (M) to only $1.6$ M. Experiments on the large-scale NuScenes dataset across three multi-view 3D object detection approaches demonstrate that our proposed method decreases computational complexity (GFLOPs) by $48\%$ ... $55\%$, inference latency (on an \texttt{NVIDIA-GV100} GPU) by $9\%$ ... $25\%$, while still improving mean average precision by $1.0\%$ ... $2.8\%$ absolute and NuScenes detection score by $0.4\%$ ... $1.2\%$ absolute compared to so-far SOTA \texttt{ToC3D}.
DisContSE: Single-Step Diffusion Speech Enhancement Based on Joint Discrete and Continuous Embeddings
Jan 29, 2026Diffusion speech enhancement on discrete audio codec features gain immense attention due to their improved speech component reconstruction capability. However, they usually suffer from high inference computational complexity due to multiple reverse process iterations. Furthermore, they generally achieve promising results on non-intrusive metrics but show poor performance on intrusive metrics, as they may struggle in reconstructing the correct phones. In this paper, we propose DisContSE, an efficient diffusion-based speech enhancement model on joint discrete codec tokens and continuous embeddings. Our contributions are three-fold. First, we formulate both a discrete and a continuous enhancement module operating on discrete audio codec tokens and continuous embeddings, respectively, to achieve improved fidelity and intelligibility simultaneously. Second, a semantic enhancement module is further adopted to achieve optimal phonetic accuracy. Third, we achieve a single-step efficient reverse process in inference with a novel quantization error mask initialization strategy, which, according to our knowledge, is the first successful single-step diffusion speech enhancement based on an audio codec. Trained and evaluated on URGENT 2024 Speech Enhancement Challenge data splits, the proposed DisContSE excels top-reported time- and frequency-domain diffusion baseline methods in PESQ, POLQA, UTMOS, and in a subjective ITU-T P.808 listening test, clearly achieving an overall top rank.
Noise-Robust AV-ASR Using Visual Features Both in the Whisper Encoder and Decoder
Jan 26, 2026In audiovisual automatic speech recognition (AV-ASR) systems, information fusion of visual features in a pre-trained ASR has been proven as a promising method to improve noise robustness. In this work, based on the prominent Whisper ASR, first, we propose a simple and effective visual fusion method -- use of visual features both in encoder and decoder (dual-use) -- to learn the audiovisual interactions in the encoder and to weigh modalities in the decoder. Second, we compare visual fusion methods in Whisper models of various sizes. Our proposed dual-use method shows consistent noise robustness improvement, e.g., a 35% relative improvement (WER: 4.41% vs. 6.83%) based on Whisper small, and a 57% relative improvement (WER: 4.07% vs. 9.53%) based on Whisper medium, compared to typical reference middle fusion in babble noise with a signal-to-noise ratio (SNR) of 0dB. Third, we conduct ablation studies examining the impact of various module designs and fusion options. Fine-tuned on 1929 hours of audiovisual data, our dual-use method using Whisper medium achieves 4.08% (MUSAN babble noise) and 4.43% (NoiseX babble noise) average WER across various SNRs, thereby establishing a new state-of-the-art in noisy conditions on the LRS3 AV-ASR benchmark. Our code is at https://github.com/ifnspaml/Dual-Use-AVASR
ICASSP 2026 URGENT Speech Enhancement Challenge
Jan 20, 2026The ICASSP 2026 URGENT Challenge advances the series by focusing on universal speech enhancement (SE) systems that handle diverse distortions, domains, and input conditions. This overview paper details the challenge's motivation, task definitions, datasets, baseline systems, evaluation protocols, and results. The challenge is divided into two complementary tracks. Track 1 focuses on universal speech enhancement, while Track 2 introduces speech quality assessment for enhanced speech. The challenge attracted over 80 team registrations, with 29 submitting valid entries, demonstrating significant community interest in robust SE technologies.
Engineering of Hallucination in Generative AI: It's not a Bug, it's a Feature
Jan 11, 2026Generative artificial intelligence (AI) is conquering our lives at lightning speed. Large language models such as ChatGPT answer our questions or write texts for us, large computer vision models such as GAIA-1 generate videos on the basis of text descriptions or continue prompted videos. These neural network models are trained using large amounts of text or video data, strictly according to the real data employed in training. However, there is a surprising observation: When we use these models, they only function satisfactorily when they are allowed a certain degree of fantasy (hallucination). While hallucination usually has a negative connotation in generative AI - after all, ChatGPT is expected to give a fact-based answer! - this article recapitulates some simple means of probability engineering that can be used to encourage generative AI to hallucinate to a limited extent and thus lead to the desired results. We have to ask ourselves: Is hallucination in gen-erative AI probably not a bug, but rather a feature?
OpenViGA: Video Generation for Automotive Driving Scenes by Streamlining and Fine-Tuning Open Source Models with Public Data
Sep 18, 2025

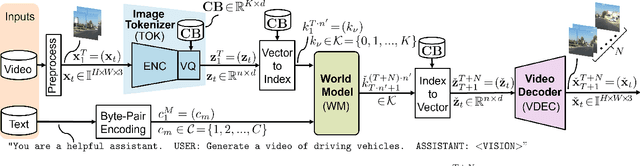

Recent successful video generation systems that predict and create realistic automotive driving scenes from short video inputs assign tokenization, future state prediction (world model), and video decoding to dedicated models. These approaches often utilize large models that require significant training resources, offer limited insight into design choices, and lack publicly available code and datasets. In this work, we address these deficiencies and present OpenViGA, an open video generation system for automotive driving scenes. Our contributions are: Unlike several earlier works for video generation, such as GAIA-1, we provide a deep analysis of the three components of our system by separate quantitative and qualitative evaluation: Image tokenizer, world model, video decoder. Second, we purely build upon powerful pre-trained open source models from various domains, which we fine-tune by publicly available automotive data (BDD100K) on GPU hardware at academic scale. Third, we build a coherent video generation system by streamlining interfaces of our components. Fourth, due to public availability of the underlying models and data, we allow full reproducibility. Finally, we also publish our code and models on Github. For an image size of 256x256 at 4 fps we are able to predict realistic driving scene videos frame-by-frame with only one frame of algorithmic latency.
Interspeech 2025 URGENT Speech Enhancement Challenge
May 29, 2025There has been a growing effort to develop universal speech enhancement (SE) to handle inputs with various speech distortions and recording conditions. The URGENT Challenge series aims to foster such universal SE by embracing a broad range of distortion types, increasing data diversity, and incorporating extensive evaluation metrics. This work introduces the Interspeech 2025 URGENT Challenge, the second edition of the series, to explore several aspects that have received limited attention so far: language dependency, universality for more distortion types, data scalability, and the effectiveness of using noisy training data. We received 32 submissions, where the best system uses a discriminative model, while most other competitive ones are hybrid methods. Analysis reveals some key findings: (i) some generative or hybrid approaches are preferred in subjective evaluations over the top discriminative model, and (ii) purely generative SE models can exhibit language dependency.
Improving Block-Wise LLM Quantization by 4-bit Block-Wise Optimal Float (BOF4): Analysis and Variations
May 10, 2025



Large language models (LLMs) demand extensive memory capacity during both fine-tuning and inference. To enable memory-efficient fine-tuning, existing methods apply block-wise quantization techniques, such as NF4 and AF4, to the network weights. We show that these quantization techniques incur suboptimal quantization errors. Therefore, as a first novelty, we propose an optimization approach for block-wise quantization. Using this method, we design a family of quantizers named 4-bit block-wise optimal float (BOF4), which consistently reduces the quantization error compared to both baseline methods. We provide both a theoretical and a data-driven solution for the optimization process and prove their practical equivalence. Secondly, we propose a modification to the employed normalization method based on the signed absolute block maximum (BOF4-S), enabling further reduction of the quantization error and empirically achieving less degradation in language modeling performance. Thirdly, we explore additional variations of block-wise quantization methods applied to LLMs through an experimental study on the importance of accurately representing zero and large-amplitude weights on the one hand, and optimization towards various error metrics on the other hand. Lastly, we introduce a mixed-precision quantization strategy dubbed outlier-preserving quantization (OPQ) to address the distributional mismatch induced by outlier weights in block-wise quantization. By storing outlier weights in 16-bit precision (OPQ) while applying BOF4-S, we achieve top performance among 4-bit block-wise quantization techniques w.r.t. perplexity.
A Lightweight Image Super-Resolution Transformer Trained on Low-Resolution Images Only
Mar 30, 2025Transformer architectures prominently lead single-image super-resolution (SISR) benchmarks, reconstructing high-resolution (HR) images from their low-resolution (LR) counterparts. Their strong representative power, however, comes with a higher demand for training data compared to convolutional neural networks (CNNs). For many real-world SR applications, the availability of high-quality HR training images is not given, sparking interest in LR-only training methods. The LR-only SISR benchmark mimics this condition by allowing only low-resolution (LR) images for model training. For a 4x super-resolution, this effectively reduces the amount of available training data to 6.25% of the HR image pixels, which puts the employment of a data-hungry transformer model into question. In this work, we are the first to utilize a lightweight vision transformer model with LR-only training methods addressing the unsupervised SISR LR-only benchmark. We adopt and configure a recent LR-only training method from microscopy image super-resolution to macroscopic real-world data, resulting in our multi-scale training method for bicubic degradation (MSTbic). Furthermore, we compare it with reference methods and prove its effectiveness both for a transformer and a CNN model. We evaluate on the classic SR benchmark datasets Set5, Set14, BSD100, Urban100, and Manga109, and show superior performance over state-of-the-art (so far: CNN-based) LR-only SISR methods. The code is available on GitHub: https://github.com/ifnspaml/SuperResolutionMultiscaleTraining.