 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICASSP 2026 URGENT Speech Enhancement Challenge
Jan 20, 2026The ICASSP 2026 URGENT Challenge advances the series by focusing on universal speech enhancement (SE) systems that handle diverse distortions, domains, and input conditions. This overview paper details the challenge's motivation, task definitions, datasets, baseline systems, evaluation protocols, and results. The challenge is divided into two complementary tracks. Track 1 focuses on universal speech enhancement, while Track 2 introduces speech quality assessment for enhanced speech. The challenge attracted over 80 team registrations, with 29 submitting valid entries, demonstrating significant community interest in robust SE technologies.
Interspeech 2025 URGENT Speech Enhancement Challenge
May 29, 2025There has been a growing effort to develop universal speech enhancement (SE) to handle inputs with various speech distortions and recording conditions. The URGENT Challenge series aims to foster such universal SE by embracing a broad range of distortion types, increasing data diversity, and incorporating extensive evaluation metrics. This work introduces the Interspeech 2025 URGENT Challenge, the second edition of the series, to explore several aspects that have received limited attention so far: language dependency, universality for more distortion types, data scalability, and the effectiveness of using noisy training data. We received 32 submissions, where the best system uses a discriminative model, while most other competitive ones are hybrid methods. Analysis reveals some key findings: (i) some generative or hybrid approaches are preferred in subjective evaluations over the top discriminative model, and (ii) purely generative SE models can exhibit language dependency.
Non-Causal to Causal SSL-Supported Transfer Learning: Towards a High-Performance Low-Latency Speech Vocode
Aug 07, 2024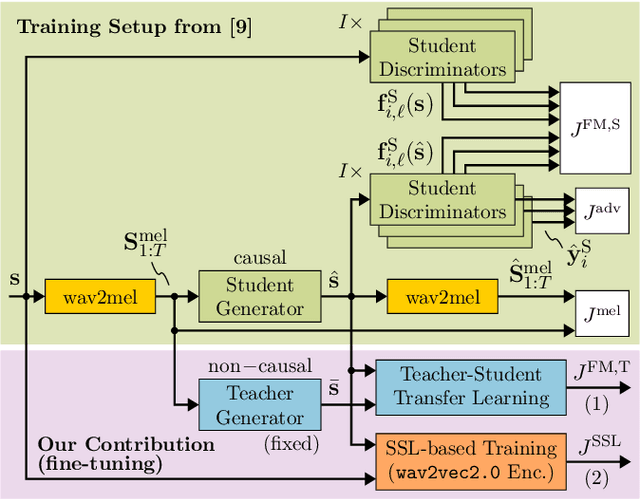
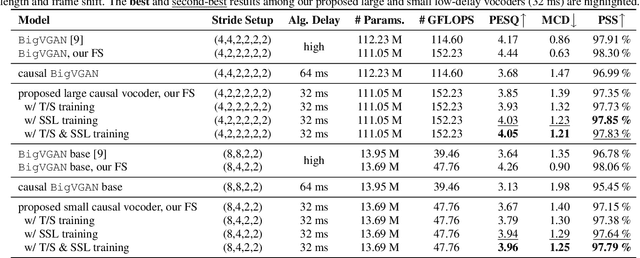
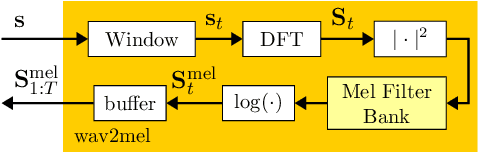

Recently, BigVGAN has emerged as high-performance speech vocoder. Its sequence-to-sequence-based synthesis, however, prohibits usage in low-latency conversational applications. Our work addresses this shortcoming in three steps. First, we introduce low latency into BigVGAN via implementing causal convolutions, yielding decreased performance. Second, to regain performance, we propose a teacher-student transfer learning scheme to distill the high-delay non-causal BigVGAN into our low-latency causal vocoder. Third, taking advantage of a self-supervised learning (SSL) model, in our case wav2vec 2.0, we align its encoder speech representations extracted from our low-latency causal vocoder to the ground truth ones. In speaker-independent settings, both proposed training schemes notably elevate the performance of our low-latency vocoder, closing up to the original high-delay BigVGAN. At only 21% higher complexity, our best small causal vocoder achieves 3.96 PESQ and 1.25 MCD, excelling even the original small non-causal BigVGAN (3.64 PESQ) by 0.32 PESQ and 0.1 MCD points, respectively.
URGENT Challenge: Universality, Robustness, and Generalizability For Speech Enhancement
Jun 07, 2024



The last decade has witnessed significant advancements in deep learning-based speech enhancement (SE). However, most existing SE research has limitations on the coverage of SE sub-tasks, data diversity and amount, and evaluation metrics. To fill this gap and promote research toward universal SE, we establish a new SE challenge, named URGENT, to focus on the universality, robustness, and generalizability of SE. We aim to extend the SE definition to cover different sub-tasks to explore the limits of SE models, starting from denoising, dereverberation, bandwidth extension, and declipping. A novel framework is proposed to unify all these sub-tasks in a single model, allowing the use of all existing SE approaches. We collected public speech and noise data from different domains to construct diverse evaluation data. Finally, we discuss the insights gained from our preliminary baseline experiments based on both generative and discriminative SE methods with 12 curated metrics.
Employing Real Training Data for Deep Noise Suppression
Sep 05, 2023


Most deep noise suppression (DNS) models are trained with reference-based losses requiring access to clean speech. However, sometimes an additive microphone model is insufficient for real-world applications. Accordingly, ways to use real training data in supervised learning for DNS models promise to reduce a potential training/inference mismatch. Employing real data for DNS training requires either generative approaches or a reference-free loss without access to the corresponding clean speech. In this work, we propose to employ an end-to-end non-intrusive deep neural network (DNN), named PESQ-DNN, to estimate perceptual evaluation of speech quality (PESQ) scores of enhanced real data. It provides a reference-free perceptual loss for employing real data during DNS training, maximizing the PESQ scores. Furthermore, we use an epoch-wise alternating training protocol, updating the DNS model on real data, followed by PESQ-DNN updating on synthetic data. The DNS model trained with the PESQ-DNN employing real data outperforms all reference methods employing only synthetic training data. On synthetic test data, our proposed method excels the Interspeech 2021 DNS Challenge baseline by a significant 0.32 PESQ points. Both on synthetic and real test data, the proposed method beats the baseline by 0.05 DNSMOS points - although PESQ-DNN optimizes for a different perceptual metric.
EffCRN: An Efficient Convolutional Recurrent Network for High-Performance Speech Enhancement
Jun 05, 2023Fully convolutional recurrent neural networks (FCRNs) have shown state-of-the-art performance in single-channel speech enhancement. However, the number of parameters and the FLOPs/second of the original FCRN are restrictively high. A further important class of efficient networks is the CRUSE topology, serving as reference in our work. By applying a number of topological changes at once, we propose both an efficient FCRN (FCRN15), and a new family of efficient convolutional recurrent neural networks (EffCRN23, EffCRN23lite). We show that our FCRN15 (875K parameters) and EffCRN23lite (396K) outperform the already efficient CRUSE5 (85M) and CRUSE4 (7.2M) networks, respectively, w.r.t. PESQ, DNSMOS and DeltaSNR, while requiring about 94% less parameters and about 20% less #FLOPs/frame. Thereby, according to these metrics, the FCRN/EffCRN class of networks provides new best-in-class network topologies for speech enhancement.