 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models for Amodal Video Instance Segmentation in Automated Driving
Sep 21, 2024In this work, we study amodal video instance segmentation for automated driving. Previous works perform amodal video instance segmentation relying on methods trained on entirely labeled video data with techniques borrowed from standard video instance segmentation. Such amodally labeled video data is difficult and expensive to obtain and the resulting methods suffer from a trade-off between instance segmentation and tracking performance. To largely solve this issue, we propose to study the application of foundation models for this task. More precisely, we exploit the extensive knowledge of the Segment Anything Model (SAM), while fine-tuning it to the amodal instance segmentation task. Given an initial video instance segmentation, we sample points from the visible masks to prompt our amodal SAM. We use a point memory to store those points. If a previously observed instance is not predicted in a following frame, we retrieve its most recent points from the point memory and use a point tracking method to follow those points to the current frame, together with the corresponding last amodal instance mask. This way, while basing our method on an amodal instance segmentation, we nevertheless obtain video-level amodal instance segmentation results. Our resulting S-AModal method achieves state-of-the-art results in amodal video instance segmentation while resolving the need for amodal video-based labels. Code for S-AModal is available at https://github.com/ifnspaml/S-AModal.
Non-Causal to Causal SSL-Supported Transfer Learning: Towards a High-Performance Low-Latency Speech Vocode
Aug 07, 2024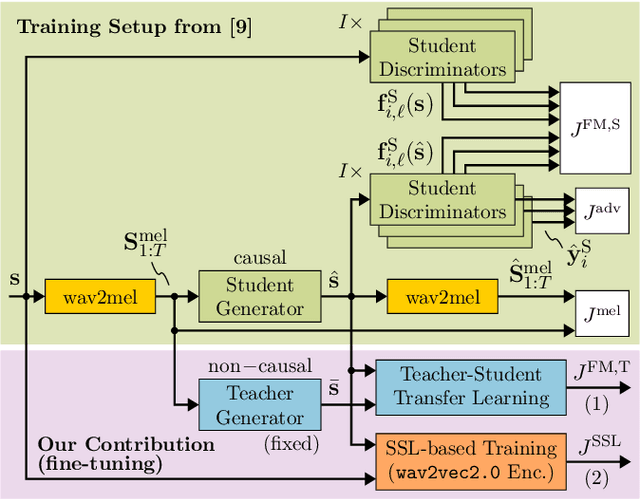
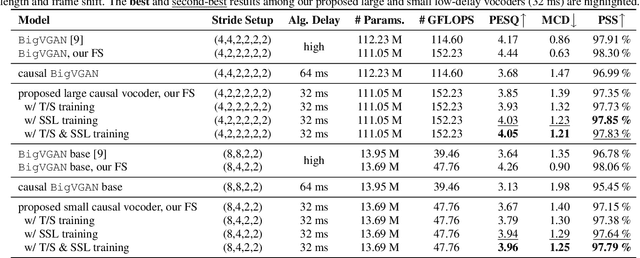
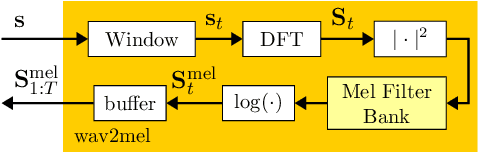

Recently, BigVGAN has emerged as high-performance speech vocoder. Its sequence-to-sequence-based synthesis, however, prohibits usage in low-latency conversational applications. Our work addresses this shortcoming in three steps. First, we introduce low latency into BigVGAN via implementing causal convolutions, yielding decreased performance. Second, to regain performance, we propose a teacher-student transfer learning scheme to distill the high-delay non-causal BigVGAN into our low-latency causal vocoder. Third, taking advantage of a self-supervised learning (SSL) model, in our case wav2vec 2.0, we align its encoder speech representations extracted from our low-latency causal vocoder to the ground truth ones. In speaker-independent settings, both proposed training schemes notably elevate the performance of our low-latency vocoder, closing up to the original high-delay BigVGAN. At only 21% higher complexity, our best small causal vocoder achieves 3.96 PESQ and 1.25 MCD, excelling even the original small non-causal BigVGAN (3.64 PESQ) by 0.32 PESQ and 0.1 MCD points, respectively.
Frozen Feature Augmentation for Few-Shot Image Classification
Mar 15, 2024
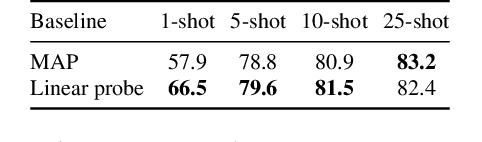
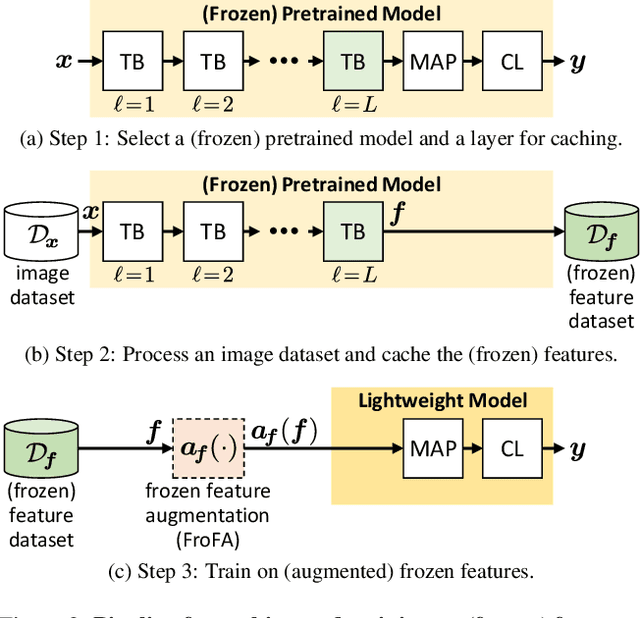
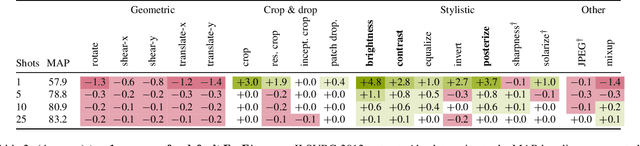
Training a linear classifier or lightweight model on top of pretrained vision model outputs, so-called 'frozen features', leads to impressive performance on a number of downstream few-shot tasks. Currently, frozen features are not modified during training. On the other hand, when networks are trained directly on images, data augmentation is a standard recipe that improves performance with no substantial overhead. In this paper, we conduct an extensive pilot study on few-shot image classification that explores applying data augmentations in the frozen feature space, dubbed 'frozen feature augmentation (FroFA)', covering twenty augmentations in total. Our study demonstrates that adopting a deceptively simple pointwise FroFA, such as brightness, can improve few-shot performance consistently across three network architectures, three large pretraining datasets, and eight transfer datasets.
Detecting Adversarial Perturbations in Multi-Task Perception
Mar 02, 2022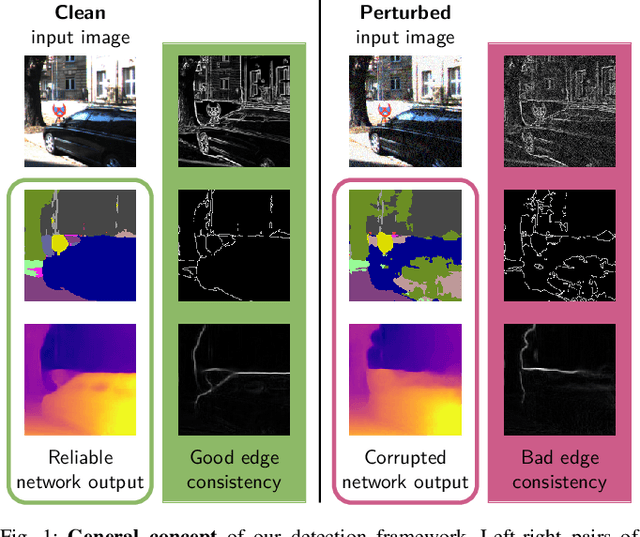
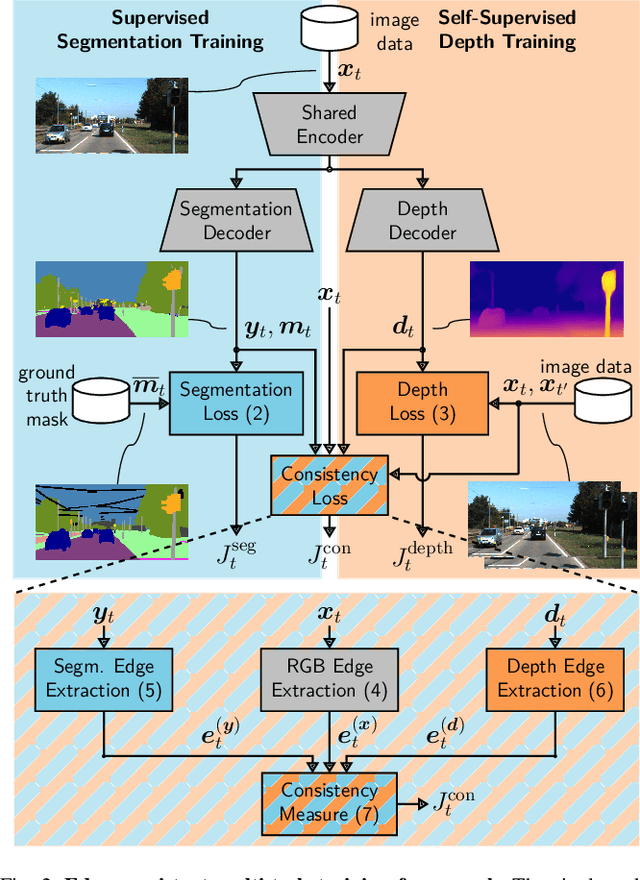
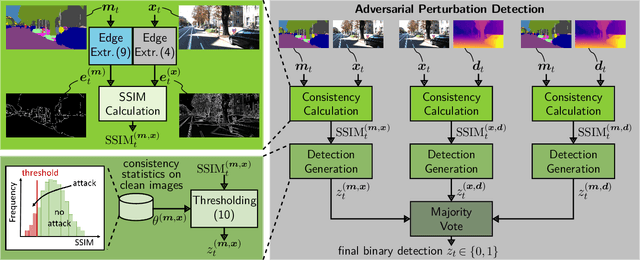
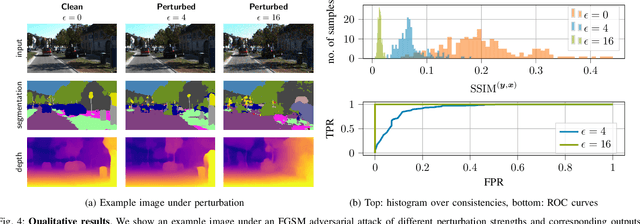
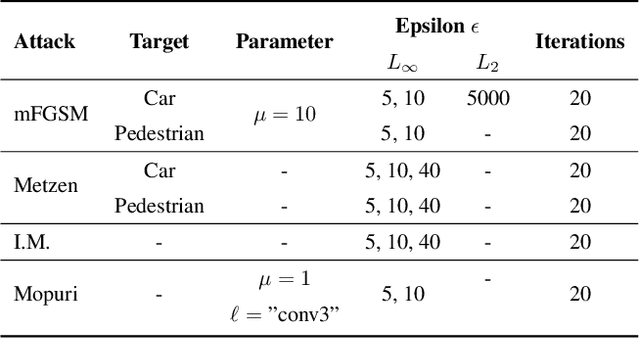
While deep neural networks (DNNs) achieve impressive performance on environment perception tasks, their sensitivity to adversarial perturbations limits their use in practical applications. In this paper, we (i) propose a novel adversarial perturbation detection scheme based on multi-task perception of complex vision tasks (i.e., depth estimation and semantic segmentation). Specifically, adversarial perturbations are detected by inconsistencies between extracted edges of the input image, the depth output, and the segmentation output. To further improve this technique, we (ii) develop a novel edge consistency loss between all three modalities, thereby improving their initial consistency which in turn supports our detection scheme. We verify our detection scheme's effectiveness by employing various known attacks and image noises. In addition, we (iii) develop a multi-task adversarial attack, aiming at fooling both tasks as well as our detection scheme. Experimental evaluation on the Cityscapes and KITTI datasets shows that under an assumption of a 5% false positive rate up to 100% of images are correctly detected as adversarially perturbed, depending on the strength of the perturbation. Code will be available on github. A short video at https://youtu.be/KKa6gOyWmH4 provides qualitative results.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
Improving Online Performance Prediction for Semantic Segmentation
Apr 12, 2021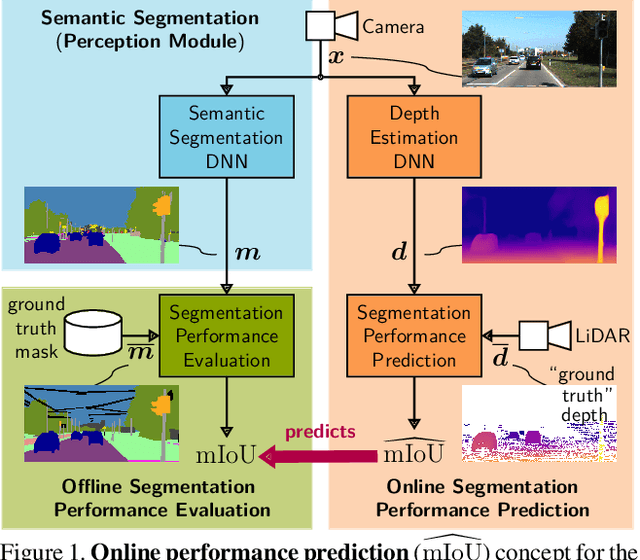
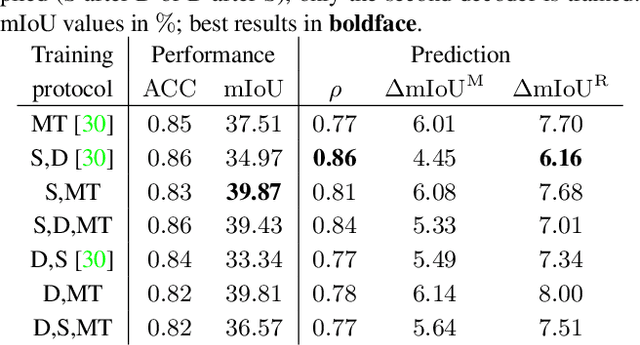
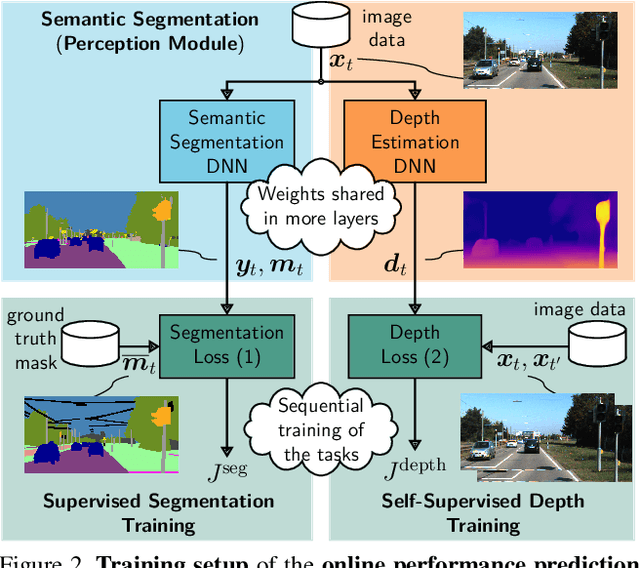
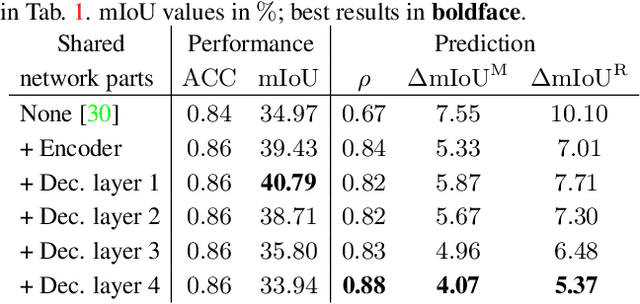
In this work we address the task of observing the performance of a semantic segmentation deep neural network (DNN) during online operation, i.e., during inference, which is of high importance in safety-critical applications such as autonomous driving. Here, many high-level decisions rely on such DNNs, which are usually evaluated offline, while their performance in online operation remains unknown. To solve this problem, we propose an improved online performance prediction scheme, building on a recently proposed concept of predicting the primary semantic segmentation task's performance. This can be achieved by evaluating the auxiliary task of monocular depth estimation with a measurement supplied by a LiDAR sensor and a subsequent regression to the semantic segmentation performance. In particular, we propose (i) sequential training methods for both tasks in a multi-task training setup, (ii) to share the encoder as well as parts of the decoder between both task's networks for improved efficiency, and (iii) a temporal statistics aggregation method, which significantly reduces the performance prediction error at the cost of a small algorithmic latency. Evaluation on the KITTI dataset shows that all three aspects improve the performance prediction compared to previous approaches.
The Vulnerability of Semantic Segmentation Networks to Adversarial Attacks in Autonomous Driving: Enhancing Extensive Environment Sensing
Jan 13, 2021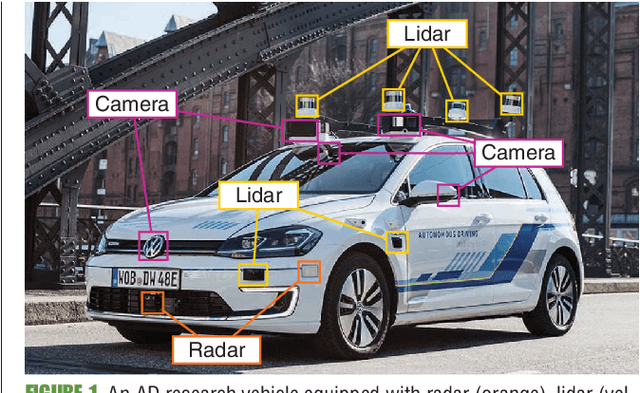

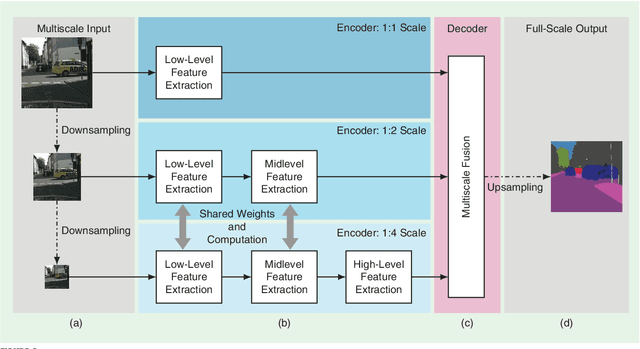
Enabling autonomous driving (AD) can be considered one of the biggest challenges in today's technology. AD is a complex task accomplished by several functionalities, with environment perception being one of its core functions. Environment perception is usually performed by combining the semantic information captured by several sensors, i.e., lidar or camera. The semantic information from the respective sensor can be extracted by using convolutional neural networks (CNNs) for dense prediction. In the past, CNNs constantly showed state-of-the-art performance on several vision-related tasks, such as semantic segmentation of traffic scenes using nothing but the red-green-blue (RGB) images provided by a camera. Although CNNs obtain state-of-the-art performance on clean images, almost imperceptible changes to the input, referred to as adversarial perturbations, may lead to fatal deception. The goal of this article is to illuminate the vulnerability aspects of CNNs used for semantic segmentation with respect to adversarial attacks, and share insights into some of the existing known adversarial defense strategies. We aim to clarify the advantages and disadvantages associated with applying CNNs for environment perception in AD to serve as a motivation for future research in this field.
From a Fourier-Domain Perspective on Adversarial Examples to a Wiener Filter Defense for Semantic Segmentation
Dec 02, 2020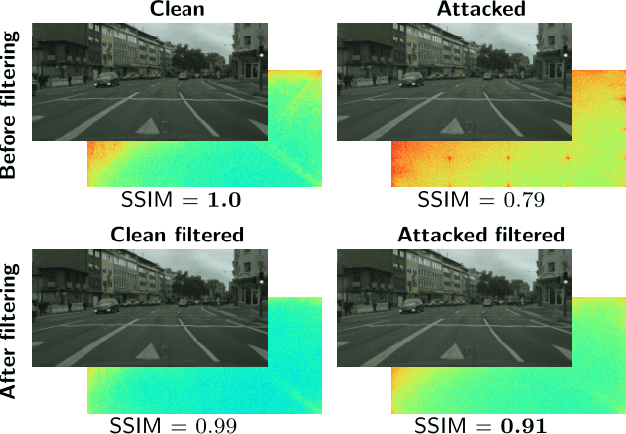
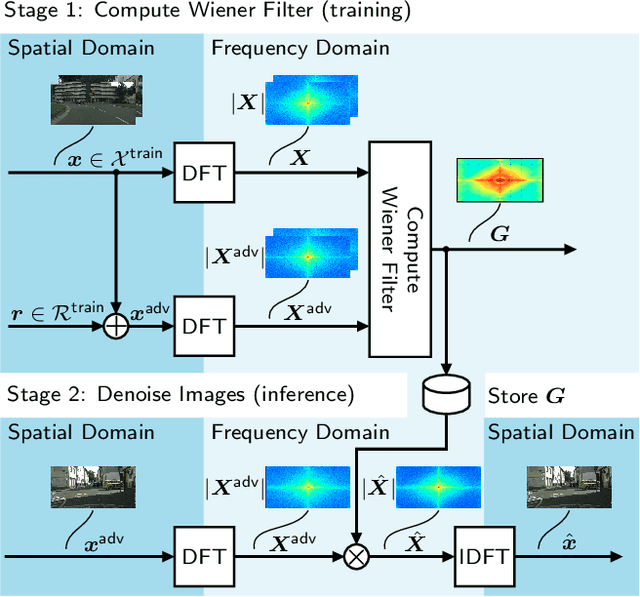
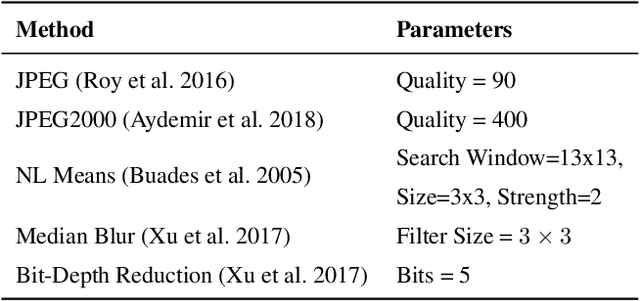
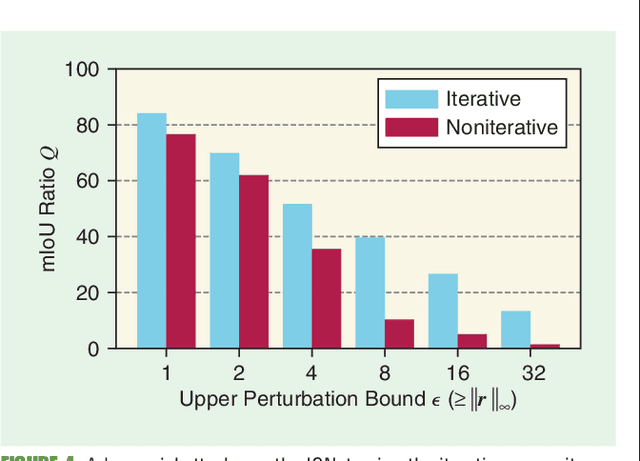
Despite recent advancements, deep neural networks are not robust against adversarial perturbations. Many of the proposed adversarial defense approaches use computationally expensive training mechanisms that do not scale to complex real-world tasks such as semantic segmentation, and offer only marginal improvements. In addition, fundamental questions on the nature of adversarial perturbations and their relation to the network architecture are largely understudied. In this work, we study the adversarial problem from a frequency domain perspective. More specifically, we analyze discrete Fourier transform (DFT) spectra of several adversarial images and report two major findings: First, there exists a strong connection between a model architecture and the nature of adversarial perturbations that can be observed and addressed in the frequency domain. Second, the observed frequency patterns are largely image- and attack-type independent, which is important for the practical impact of any defense making use of such patterns. Motivated by these findings, we additionally propose an adversarial defense method based on the well-known Wiener filters that captures and suppresses adversarial frequencies in a data-driven manner. Our proposed method not only generalizes across unseen attacks but also beats five existing state-of-the-art methods across two models in a variety of attack settings.
Transferable Universal Adversarial Perturbations Using Generative Models
Oct 29, 2020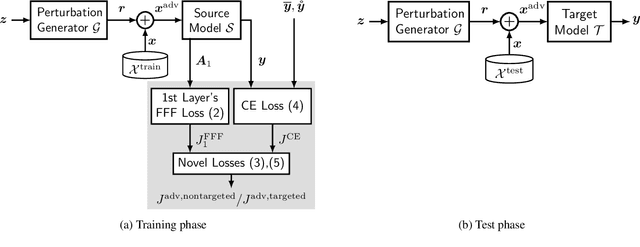
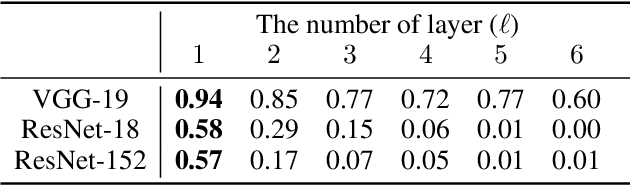

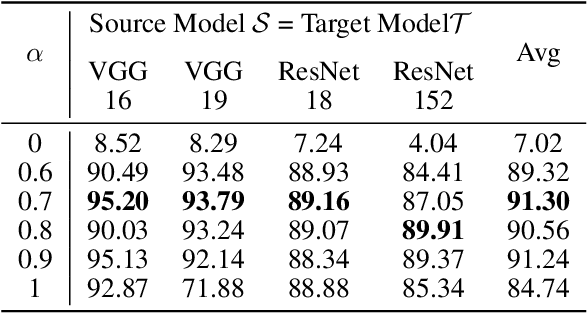
Deep neural networks tend to be vulnerable to adversarial perturbations, which by adding to a natural image can fool a respective model with high confidence. Recently, the existence of image-agnostic perturbations, also known as universal adversarial perturbations (UAPs), were discovered. However, existing UAPs still lack a sufficiently high fooling rate, when being applied to an unknown target model. In this paper, we propose a novel deep learning technique for generating more transferable UAPs. We utilize a perturbation generator and some given pretrained networks so-called source models to generate UAPs using the ImageNet dataset. Due to the similar feature representation of various model architectures in the first layer, we propose a loss formulation that focuses on the adversarial energy only in the respective first layer of the source models. This supports the transferability of our generated UAPs to any other target model. We further empirically analyze our generated UAPs and demonstrate that these perturbations generalize very well towards different target models. Surpassing the current state of the art in both, fooling rate and model-transferability, we can show the superiority of our proposed approach. Using our generated non-targeted UAPs, we obtain an average fooling rate of 93.36% on the source models (state of the art: 82.16%). Generating our UAPs on the deep ResNet-152, we obtain about a 12% absolute fooling rate advantage vs. cutting-edge methods on VGG-16 and VGG-19 target models.
Class-Incremental Learning for Semantic Segmentation Re-Using Neither Old Data Nor Old Labels
May 12, 2020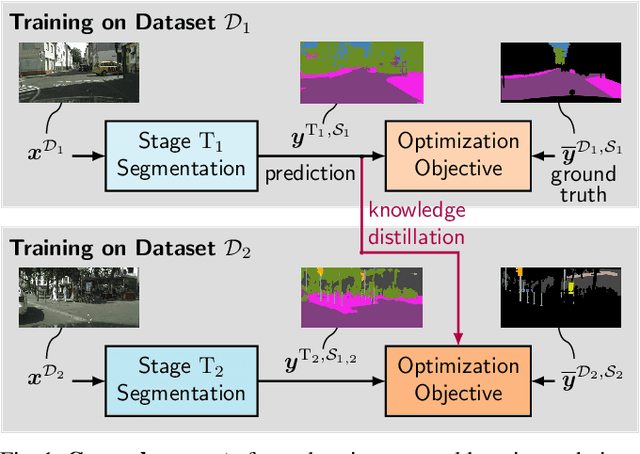
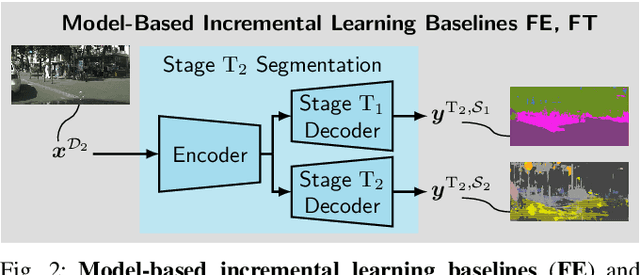
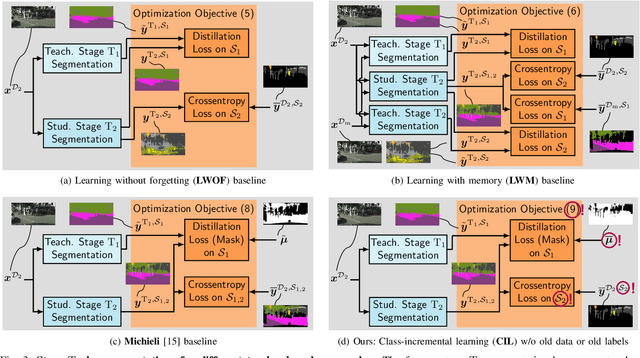
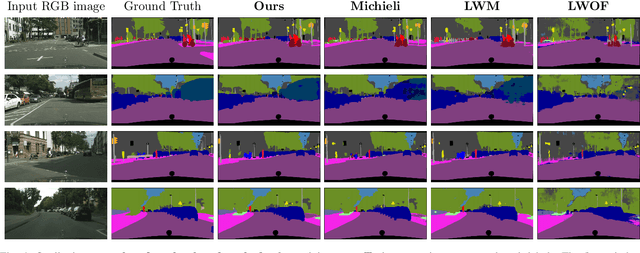
While neural networks trained for semantic segmentation are essential for perception in autonomous driving, most current algorithms assume a fixed number of classes, presenting a major limitation when developing new autonomous driving systems with the need of additional classes. In this paper we present a technique implementing class-incremental learning for semantic segmentation without using the labeled data the model was initially trained on. Previous approaches still either rely on labels for both old and new classes, or fail to properly distinguish between them. We show how to overcome these problems with a novel class-incremental learning technique, which nonetheless requires labels only for the new classes. Specifically, (i) we introduce a new loss function that neither relies on old data nor on old labels, (ii) we show how new classes can be integrated in a modular fashion into pretrained semantic segmentation models, and finally (iii) we re-implement previous approaches in a unified setting to compare them to ours. We evaluate our method on the Cityscapes dataset, where we exceed the mIoU performance of all baselines by 3.5% absolute reaching a result, which is only 2.2% absolute below the upper performance limit of single-stage training, relying on all data and labels simultaneously.