 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Incremental Learning for Semantic Segmentation Re-Using Neither Old Data Nor Old Labels
May 12, 2020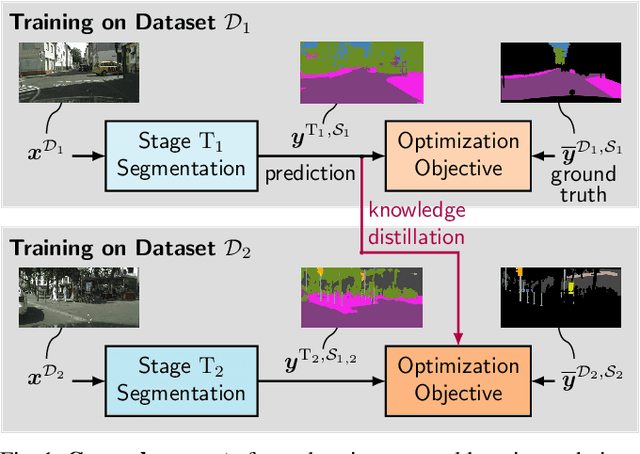
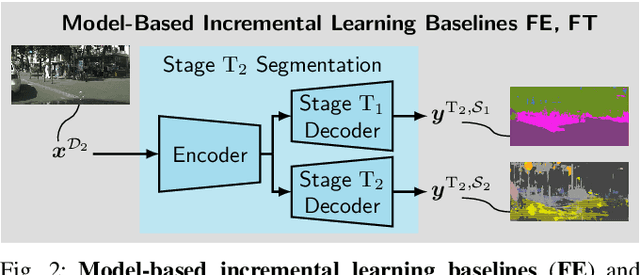
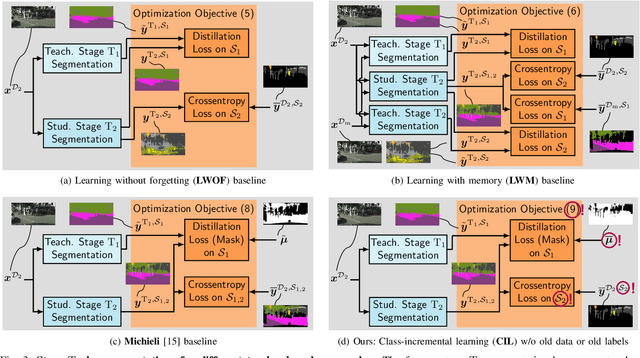
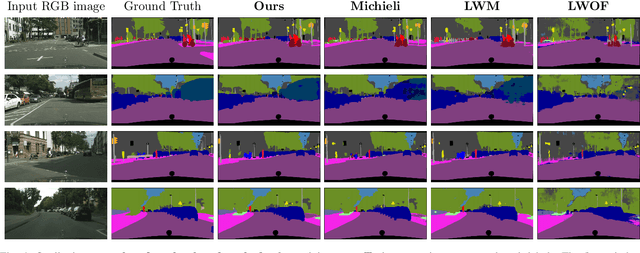
While neural networks trained for semantic segmentation are essential for perception in autonomous driving, most current algorithms assume a fixed number of classes, presenting a major limitation when developing new autonomous driving systems with the need of additional classes. In this paper we present a technique implementing class-incremental learning for semantic segmentation without using the labeled data the model was initially trained on. Previous approaches still either rely on labels for both old and new classes, or fail to properly distinguish between them. We show how to overcome these problems with a novel class-incremental learning technique, which nonetheless requires labels only for the new classes. Specifically, (i) we introduce a new loss function that neither relies on old data nor on old labels, (ii) we show how new classes can be integrated in a modular fashion into pretrained semantic segmentation models, and finally (iii) we re-implement previous approaches in a unified setting to compare them to ours. We evaluate our method on the Cityscapes dataset, where we exceed the mIoU performance of all baselines by 3.5% absolute reaching a result, which is only 2.2% absolute below the upper performance limit of single-stage training, relying on all data and labels simultaneously.