 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFishRoPE: Projective Rotary Position Embeddings for Omnidirectional Visual Perception
Apr 12, 2026Vision foundation models (VFMs) and Bird's Eye View (BEV) representation have advanced visual perception substantially, yet their internal spatial representations assume the rectilinear geometry of pinhole cameras. Fisheye cameras, widely deployed on production autonomous vehicles for their surround-view coverage, exhibit severe radial distortion that renders these representations geometrically inconsistent. At the same time, the scarcity of large-scale fisheye annotations makes retraining foundation models from scratch impractical. We present \ours, a lightweight framework that adapts frozen VFMs to fisheye geometry through two components: a frozen DINOv2 backbone with Low-Rank Adaptation (LoRA) that transfers rich self-supervised features to fisheye without task-specific pretraining, and Fisheye Rotary Position Embedding (FishRoPE), which reparameterizes the attention mechanism in the spherical coordinates of the fisheye projection so that both self-attention and cross-attention operate on angular separation rather than pixel distance. FishRoPE is architecture-agnostic, introduces negligible computational overhead, and naturally reduces to the standard formulation under pinhole geometry. We evaluate \ours on WoodScape 2D detection (54.3 mAP) and SynWoodScapes BEV segmentation (65.1 mIoU), where it achieves state-of-the-art results on both benchmarks.
MambaFusion: Adaptive State-Space Fusion for Multimodal 3D Object Detection
Feb 08, 2026Reliable 3D object detection is fundamental to autonomous driving, and multimodal fusion algorithms using cameras and LiDAR remain a persistent challenge. Cameras provide dense visual cues but ill posed depth; LiDAR provides a precise 3D structure but sparse coverage. Existing BEV-based fusion frameworks have made good progress, but they have difficulties including inefficient context modeling, spatially invariant fusion, and reasoning under uncertainty. We introduce MambaFusion, a unified multi-modal detection framework that achieves efficient, adaptive, and physically grounded 3D perception. MambaFusion interleaves selective state-space models (SSMs) with windowed transformers to propagate the global context in linear time while preserving local geometric fidelity. A multi-modal token alignment (MTA) module and reliability-aware fusion gates dynamically re-weight camera-LiDAR features based on spatial confidence and calibration consistency. Finally, a structure-conditioned diffusion head integrates graph-based reasoning with uncertainty-aware denoising, enforcing physical plausibility, and calibrated confidence. MambaFusion establishes new state-of-the-art performance on nuScenes benchmarks while operating with linear-time complexity. The framework demonstrates that coupling SSM-based efficiency with reliability-driven fusion yields robust, temporally stable, and interpretable 3D perception for real-world autonomous driving systems.
DaF-BEVSeg: Distortion-aware Fisheye Camera based Bird's Eye View Segmentation with Occlusion Reasoning
Apr 09, 2024



Semantic segmentation is an effective way to perform scene understanding. Recently, segmentation in 3D Bird's Eye View (BEV) space has become popular as its directly used by drive policy. However, there is limited work on BEV segmentation for surround-view fisheye cameras, commonly used in commercial vehicles. As this task has no real-world public dataset and existing synthetic datasets do not handle amodal regions due to occlusion, we create a synthetic dataset using the Cognata simulator comprising diverse road types, weather, and lighting conditions. We generalize the BEV segmentation to work with any camera model; this is useful for mixing diverse cameras. We implement a baseline by applying cylindrical rectification on the fisheye images and using a standard LSS-based BEV segmentation model. We demonstrate that we can achieve better performance without undistortion, which has the adverse effects of increased runtime due to pre-processing, reduced field-of-view, and resampling artifacts. Further, we introduce a distortion-aware learnable BEV pooling strategy that is more effective for the fisheye cameras. We extend the model with an occlusion reasoning module, which is critical for estimating in BEV space. Qualitative performance of DaF-BEVSeg is showcased in the video at https://streamable.com/ge4v51.
Impact of Video Compression Artifacts on Fisheye Camera Visual Perception Tasks
Mar 25, 2024



Autonomous driving systems require extensive data collection schemes to cover the diverse scenarios needed for building a robust and safe system. The data volumes are in the order of Exabytes and have to be stored for a long period of time (i.e., more than 10 years of the vehicle's life cycle). Lossless compression doesn't provide sufficient compression ratios, hence, lossy video compression has been explored. It is essential to prove that lossy video compression artifacts do not impact the performance of the perception algorithms. However, there is limited work in this area to provide a solid conclusion. In particular, there is no such work for fisheye cameras, which have high radial distortion and where compression may have higher artifacts. Fisheye cameras are commonly used in automotive systems for 3D object detection task. In this work, we provide the first analysis of the impact of standard video compression codecs on wide FOV fisheye camera images. We demonstrate that the achievable compression with negligible impact depends on the dataset and temporal prediction of the video codec. We propose a radial distortion-aware zonal metric to evaluate the performance of artifacts in fisheye images. In addition, we present a novel method for estimating affine mode parameters of the latest VVC codec, and suggest some areas for improvement in video codecs for the application to fisheye imagery.
Neural Rendering based Urban Scene Reconstruction for Autonomous Driving
Feb 09, 2024Dense 3D reconstruction has many applications in automated driving including automated annotation validation, multimodal data augmentation, providing ground truth annotations for systems lacking LiDAR, as well as enhancing auto-labeling accuracy. LiDAR provides highly accurate but sparse depth, whereas camera images enable estimation of dense depth but noisy particularly at long ranges. In this paper, we harness the strengths of both sensors and propose a multimodal 3D scene reconstruction using a framework combining neural implicit surfaces and radiance fields. In particular, our method estimates dense and accurate 3D structures and creates an implicit map representation based on signed distance fields, which can be further rendered into RGB images, and depth maps. A mesh can be extracted from the learned signed distance field and culled based on occlusion. Dynamic objects are efficiently filtered on the fly during sampling using 3D object detection models. We demonstrate qualitative and quantitative results on challenging automotive scenes.
Multi-camera Bird's Eye View Perception for Autonomous Driving
Sep 19, 2023Most automated driving systems comprise a diverse sensor set, including several cameras, Radars, and LiDARs, ensuring a complete 360\deg coverage in near and far regions. Unlike Radar and LiDAR, which measure directly in 3D, cameras capture a 2D perspective projection with inherent depth ambiguity. However, it is essential to produce perception outputs in 3D to enable the spatial reasoning of other agents and structures for optimal path planning. The 3D space is typically simplified to the BEV space by omitting the less relevant Z-coordinate, which corresponds to the height dimension.The most basic approach to achieving the desired BEV representation from a camera image is IPM, assuming a flat ground surface. Surround vision systems that are pretty common in new vehicles use the IPM principle to generate a BEV image and to show it on display to the driver. However, this approach is not suited for autonomous driving since there are severe distortions introduced by this too-simplistic transformation method. More recent approaches use deep neural networks to output directly in BEV space. These methods transform camera images into BEV space using geometric constraints implicitly or explicitly in the network. As CNN has more context information and a learnable transformation can be more flexible and adapt to image content, the deep learning-based methods set the new benchmark for BEV transformation and achieve state-of-the-art performance. First, this chapter discusses the contemporary trends of multi-camera-based DNN (deep neural network) models outputting object representations directly in the BEV space. Then, we discuss how this approach can extend to effective sensor fusion and coupling downstream tasks like situation analysis and prediction. Finally, we show challenges and open problems in BEV perception.
LiDAR-BEVMTN: Real-Time LiDAR Bird's-Eye View Multi-Task Perception Network for Autonomous Driving
Jul 17, 2023



LiDAR is crucial for robust 3D scene perception in autonomous driving. LiDAR perception has the largest body of literature after camera perception. However, multi-task learning across tasks like detection, segmentation, and motion estimation using LiDAR remains relatively unexplored, especially on automotive-grade embedded platforms. We present a real-time multi-task convolutional neural network for LiDAR-based object detection, semantics, and motion segmentation. The unified architecture comprises a shared encoder and task-specific decoders, enabling joint representation learning. We propose a novel Semantic Weighting and Guidance (SWAG) module to transfer semantic features for improved object detection selectively. Our heterogeneous training scheme combines diverse datasets and exploits complementary cues between tasks. The work provides the first embedded implementation unifying these key perception tasks from LiDAR point clouds achieving 3ms latency on the embedded NVIDIA Xavier platform. We achieve state-of-the-art results for two tasks, semantic and motion segmentation, and close to state-of-the-art performance for 3D object detection. By maximizing hardware efficiency and leveraging multi-task synergies, our method delivers an accurate and efficient solution tailored for real-world automated driving deployment. Qualitative results can be seen at https://youtu.be/H-hWRzv2lIY.
X$^3$KD: Knowledge Distillation Across Modalities, Tasks and Stages for Multi-Camera 3D Object Detection
Mar 03, 2023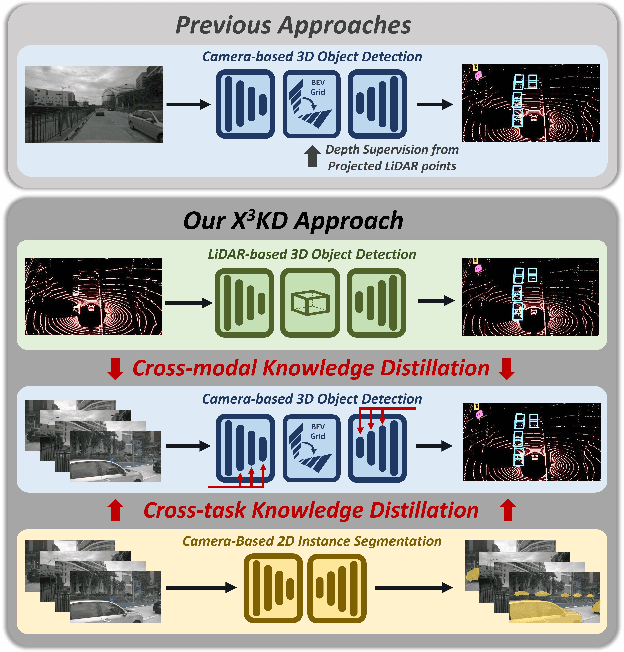
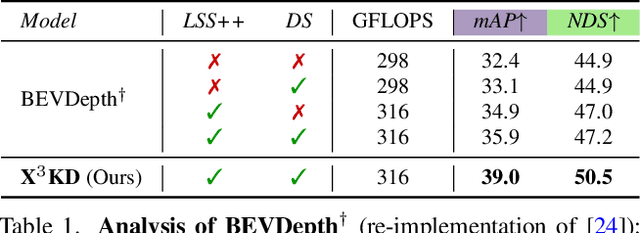
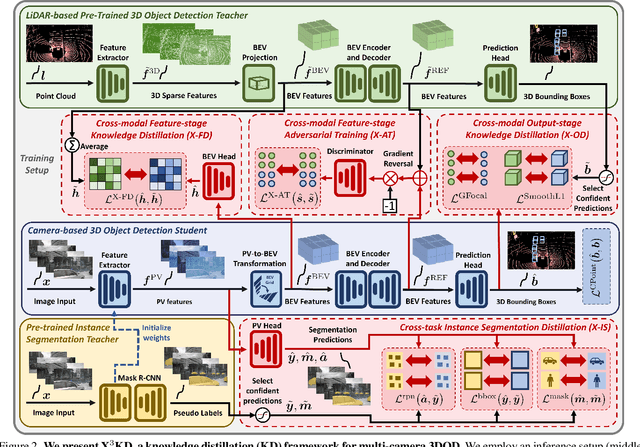
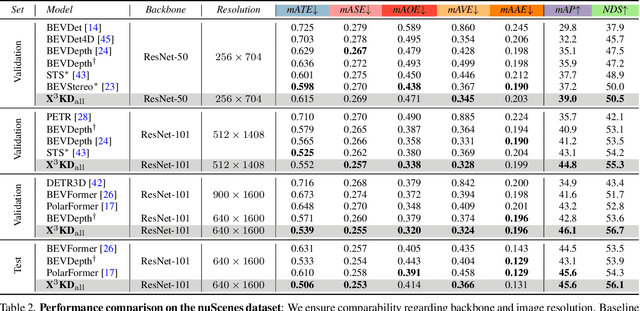
Recent advances in 3D object detection (3DOD) have obtained remarkably strong results for LiDAR-based models. In contrast, surround-view 3DOD models based on multiple camera images underperform due to the necessary view transformation of features from perspective view (PV) to a 3D world representation which is ambiguous due to missing depth information. This paper introduces X$^3$KD, a comprehensive knowledge distillation framework across different modalities, tasks, and stages for multi-camera 3DOD. Specifically, we propose cross-task distillation from an instance segmentation teacher (X-IS) in the PV feature extraction stage providing supervision without ambiguous error backpropagation through the view transformation. After the transformation, we apply cross-modal feature distillation (X-FD) and adversarial training (X-AT) to improve the 3D world representation of multi-camera features through the information contained in a LiDAR-based 3DOD teacher. Finally, we also employ this teacher for cross-modal output distillation (X-OD), providing dense supervision at the prediction stage. We perform extensive ablations of knowledge distillation at different stages of multi-camera 3DOD. Our final X$^3$KD model outperforms previous state-of-the-art approaches on the nuScenes and Waymo datasets and generalizes to RADAR-based 3DOD. Qualitative results video at https://youtu.be/1do9DPFmr38.
X-Align: Cross-Modal Cross-View Alignment for Bird's-Eye-View Segmentation
Oct 13, 2022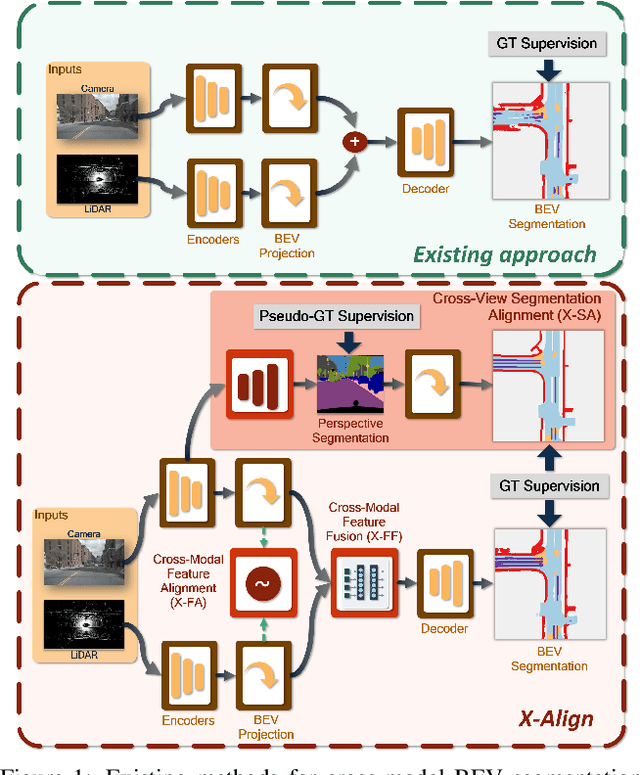
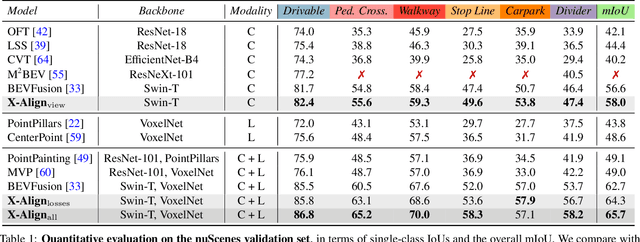
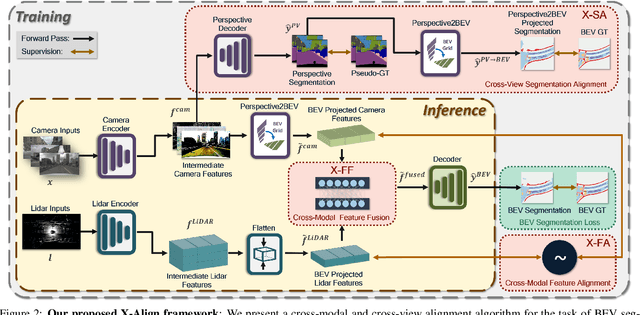

Bird's-eye-view (BEV) grid is a common representation for the perception of road components, e.g., drivable area, in autonomous driving. Most existing approaches rely on cameras only to perform segmentation in BEV space, which is fundamentally constrained by the absence of reliable depth information. Latest works leverage both camera and LiDAR modalities, but sub-optimally fuse their features using simple, concatenation-based mechanisms. In this paper, we address these problems by enhancing the alignment of the unimodal features in order to aid feature fusion, as well as enhancing the alignment between the cameras' perspective view (PV) and BEV representations. We propose X-Align, a novel end-to-end cross-modal and cross-view learning framework for BEV segmentation consisting of the following components: (i) a novel Cross-Modal Feature Alignment (X-FA) loss, (ii) an attention-based Cross-Modal Feature Fusion (X-FF) module to align multi-modal BEV features implicitly, and (iii) an auxiliary PV segmentation branch with Cross-View Segmentation Alignment (X-SA) losses to improve the PV-to-BEV transformation. We evaluate our proposed method across two commonly used benchmark datasets, i.e., nuScenes and KITTI-360. Notably, X-Align significantly outperforms the state-of-the-art by 3 absolute mIoU points on nuScenes. We also provide extensive ablation studies to demonstrate the effectiveness of the individual components.
Woodscape Fisheye Object Detection for Autonomous Driving -- CVPR 2022 OmniCV Workshop Challenge
Jun 26, 2022



Object detection is a comprehensively studied problem in autonomous driving. However, it has been relatively less explored in the case of fisheye cameras. The strong radial distortion breaks the translation invariance inductive bias of Convolutional Neural Networks. Thus, we present the WoodScape fisheye object detection challenge for autonomous driving which was held as part of the CVPR 2022 Workshop on Omnidirectional Computer Vision (OmniCV). This is one of the first competitions focused on fisheye camera object detection. We encouraged the participants to design models which work natively on fisheye images without rectification. We used CodaLab to host the competition based on the publicly available WoodScape fisheye dataset. In this paper, we provide a detailed analysis on the competition which attracted the participation of 120 global teams and a total of 1492 submissions. We briefly discuss the details of the winning methods and analyze their qualitative and quantitative results.