 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFishRoPE: Projective Rotary Position Embeddings for Omnidirectional Visual Perception
Apr 12, 2026Vision foundation models (VFMs) and Bird's Eye View (BEV) representation have advanced visual perception substantially, yet their internal spatial representations assume the rectilinear geometry of pinhole cameras. Fisheye cameras, widely deployed on production autonomous vehicles for their surround-view coverage, exhibit severe radial distortion that renders these representations geometrically inconsistent. At the same time, the scarcity of large-scale fisheye annotations makes retraining foundation models from scratch impractical. We present \ours, a lightweight framework that adapts frozen VFMs to fisheye geometry through two components: a frozen DINOv2 backbone with Low-Rank Adaptation (LoRA) that transfers rich self-supervised features to fisheye without task-specific pretraining, and Fisheye Rotary Position Embedding (FishRoPE), which reparameterizes the attention mechanism in the spherical coordinates of the fisheye projection so that both self-attention and cross-attention operate on angular separation rather than pixel distance. FishRoPE is architecture-agnostic, introduces negligible computational overhead, and naturally reduces to the standard formulation under pinhole geometry. We evaluate \ours on WoodScape 2D detection (54.3 mAP) and SynWoodScapes BEV segmentation (65.1 mIoU), where it achieves state-of-the-art results on both benchmarks.
MambaFusion: Adaptive State-Space Fusion for Multimodal 3D Object Detection
Feb 08, 2026Reliable 3D object detection is fundamental to autonomous driving, and multimodal fusion algorithms using cameras and LiDAR remain a persistent challenge. Cameras provide dense visual cues but ill posed depth; LiDAR provides a precise 3D structure but sparse coverage. Existing BEV-based fusion frameworks have made good progress, but they have difficulties including inefficient context modeling, spatially invariant fusion, and reasoning under uncertainty. We introduce MambaFusion, a unified multi-modal detection framework that achieves efficient, adaptive, and physically grounded 3D perception. MambaFusion interleaves selective state-space models (SSMs) with windowed transformers to propagate the global context in linear time while preserving local geometric fidelity. A multi-modal token alignment (MTA) module and reliability-aware fusion gates dynamically re-weight camera-LiDAR features based on spatial confidence and calibration consistency. Finally, a structure-conditioned diffusion head integrates graph-based reasoning with uncertainty-aware denoising, enforcing physical plausibility, and calibrated confidence. MambaFusion establishes new state-of-the-art performance on nuScenes benchmarks while operating with linear-time complexity. The framework demonstrates that coupling SSM-based efficiency with reliability-driven fusion yields robust, temporally stable, and interpretable 3D perception for real-world autonomous driving systems.
DaF-BEVSeg: Distortion-aware Fisheye Camera based Bird's Eye View Segmentation with Occlusion Reasoning
Apr 09, 2024



Semantic segmentation is an effective way to perform scene understanding. Recently, segmentation in 3D Bird's Eye View (BEV) space has become popular as its directly used by drive policy. However, there is limited work on BEV segmentation for surround-view fisheye cameras, commonly used in commercial vehicles. As this task has no real-world public dataset and existing synthetic datasets do not handle amodal regions due to occlusion, we create a synthetic dataset using the Cognata simulator comprising diverse road types, weather, and lighting conditions. We generalize the BEV segmentation to work with any camera model; this is useful for mixing diverse cameras. We implement a baseline by applying cylindrical rectification on the fisheye images and using a standard LSS-based BEV segmentation model. We demonstrate that we can achieve better performance without undistortion, which has the adverse effects of increased runtime due to pre-processing, reduced field-of-view, and resampling artifacts. Further, we introduce a distortion-aware learnable BEV pooling strategy that is more effective for the fisheye cameras. We extend the model with an occlusion reasoning module, which is critical for estimating in BEV space. Qualitative performance of DaF-BEVSeg is showcased in the video at https://streamable.com/ge4v51.
X$^3$KD: Knowledge Distillation Across Modalities, Tasks and Stages for Multi-Camera 3D Object Detection
Mar 03, 2023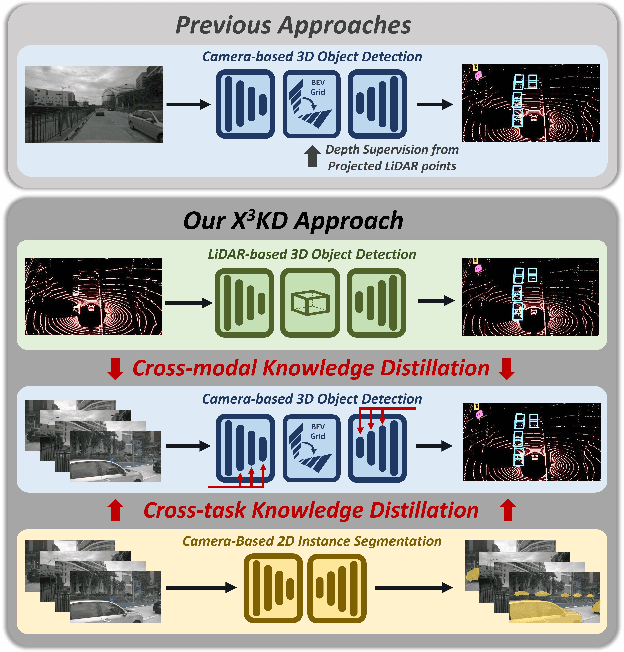
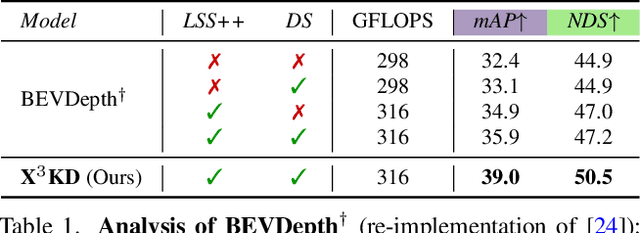
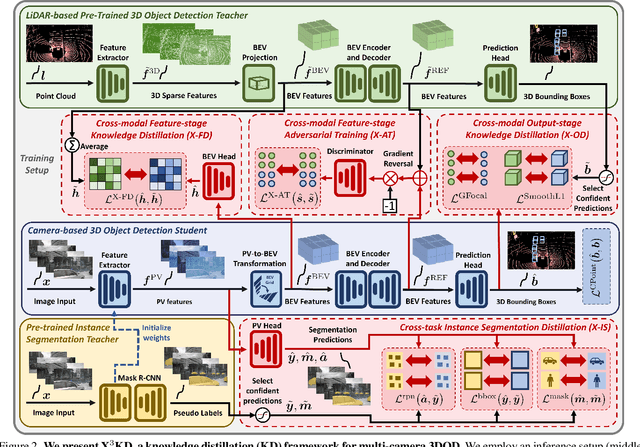
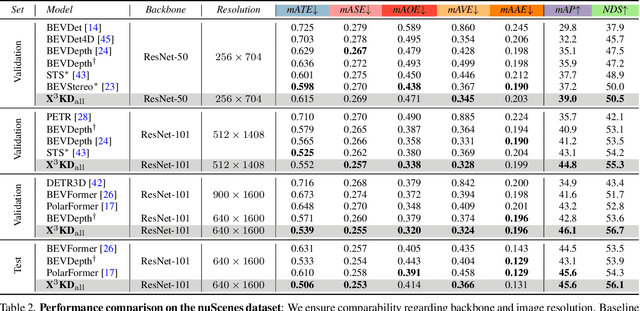
Recent advances in 3D object detection (3DOD) have obtained remarkably strong results for LiDAR-based models. In contrast, surround-view 3DOD models based on multiple camera images underperform due to the necessary view transformation of features from perspective view (PV) to a 3D world representation which is ambiguous due to missing depth information. This paper introduces X$^3$KD, a comprehensive knowledge distillation framework across different modalities, tasks, and stages for multi-camera 3DOD. Specifically, we propose cross-task distillation from an instance segmentation teacher (X-IS) in the PV feature extraction stage providing supervision without ambiguous error backpropagation through the view transformation. After the transformation, we apply cross-modal feature distillation (X-FD) and adversarial training (X-AT) to improve the 3D world representation of multi-camera features through the information contained in a LiDAR-based 3DOD teacher. Finally, we also employ this teacher for cross-modal output distillation (X-OD), providing dense supervision at the prediction stage. We perform extensive ablations of knowledge distillation at different stages of multi-camera 3DOD. Our final X$^3$KD model outperforms previous state-of-the-art approaches on the nuScenes and Waymo datasets and generalizes to RADAR-based 3DOD. Qualitative results video at https://youtu.be/1do9DPFmr38.
EWareNet: Emotion Aware Human Intent Prediction and Adaptive Spatial Profile Fusion for Social Robot Navigation
Dec 01, 2020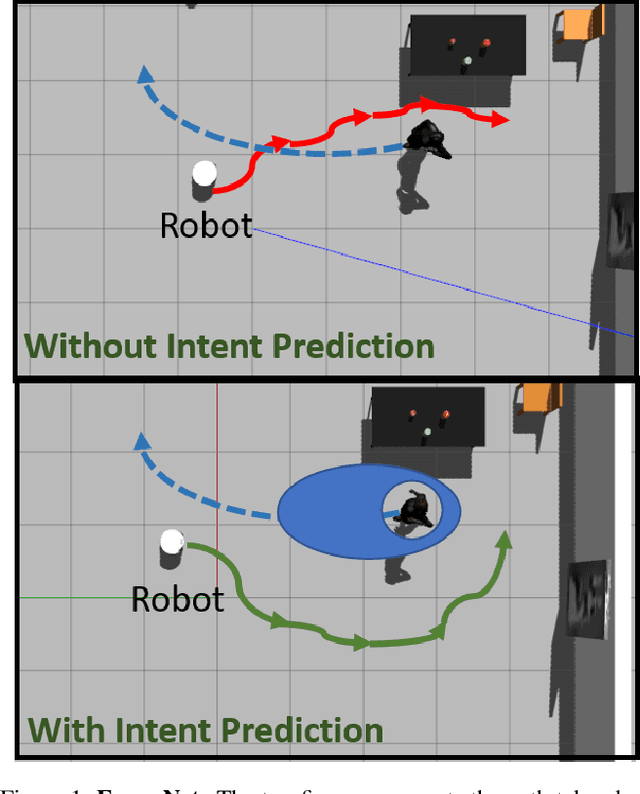
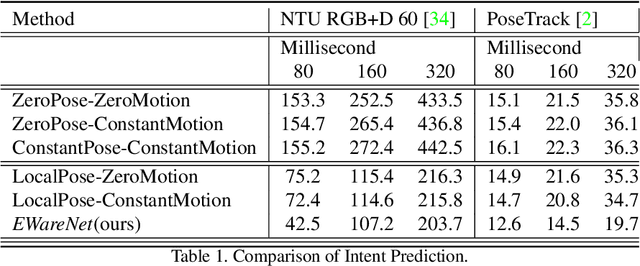
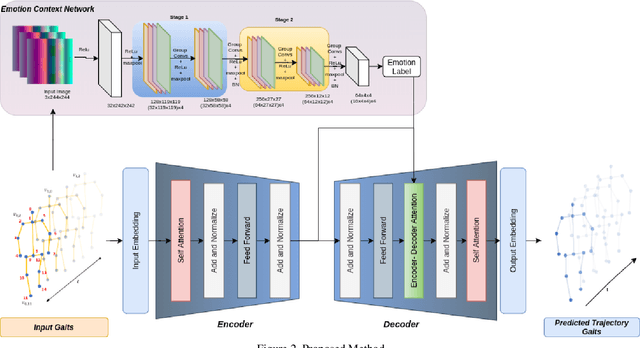
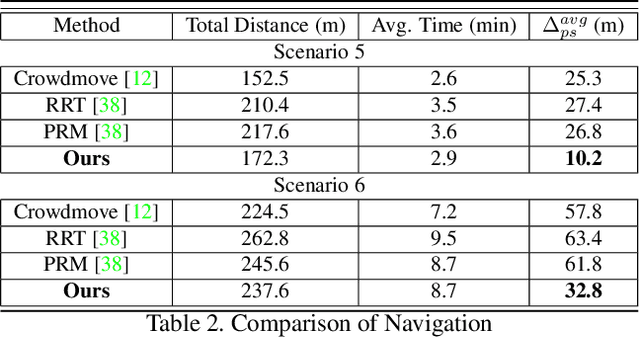
We present EWareNet, a novel intent-aware social robot navigation algorithm among pedestrians. Our approach predicts the trajectory-based pedestrian intent from historical gaits, which is then used for intent-guided navigation taking into account social and proxemic constraints. To predict pedestrian intent, we propose a transformer-based model that works on a commodity RGB-D camera mounted onto a moving robot. Our intent prediction routine is integrated into a mapless navigation scheme and makes no assumptions about the environment of pedestrian motion. Our navigation scheme consists of a novel obstacle profile representation methodology that is dynamically adjusted based on the pedestrian pose, intent, and emotion. The navigation scheme is based on a reinforcement learning algorithm that takes into consideration human intent and robot's impact on human intent, in addition to the environmental configuration. We outperform current state-of-art algorithms for intent prediction from 3D gaits.
SeekNet: Improved Human Instance Segmentation via Reinforcement Learning Based Optimized Robot Relocation
Nov 17, 2020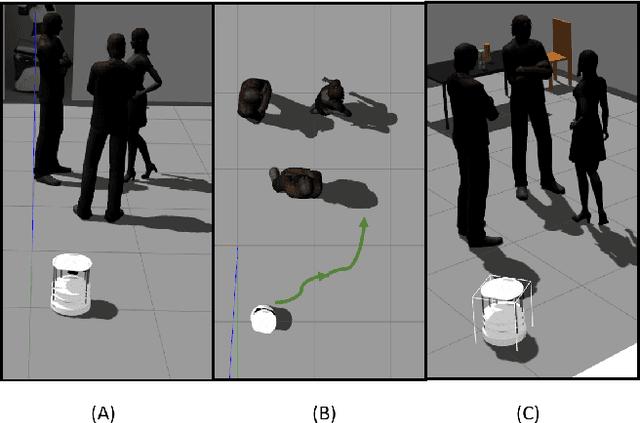
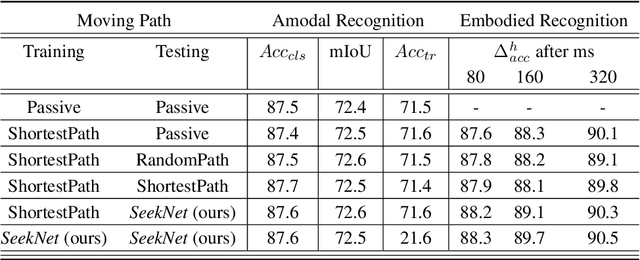
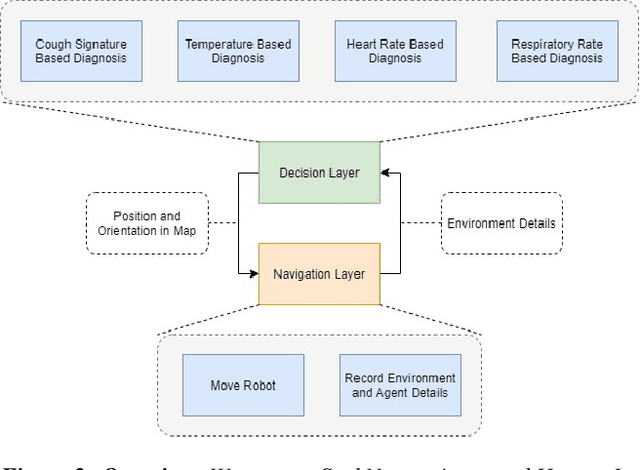
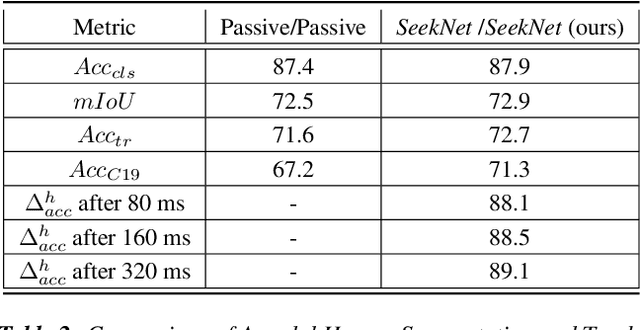
Amodal recognition is the ability of the system to detect occluded objects. Most state-of-the-art Visual Recognition systems lack the ability to perform amodal recognition. Few studies have achieved amodal recognition through passive prediction or embodied recognition approaches. However, these approaches suffer from challenges in real-world applications, such as dynamic objects. We propose SeekNet, an improved optimization method for amodal recognition through embodied visual recognition. Additionally, we implement SeekNet for social robots, where there are multiple interactions with crowded humans. Hence, we focus on occluded human detection & tracking and showcase the superiority of our algorithm over other baselines. We also experiment with SeekNet to improve the confidence of COVID-19 symptoms pre-screening algorithms using our efficient embodied recognition system.
Learning Panoptic Segmentation from Instance Contours
Oct 16, 2020
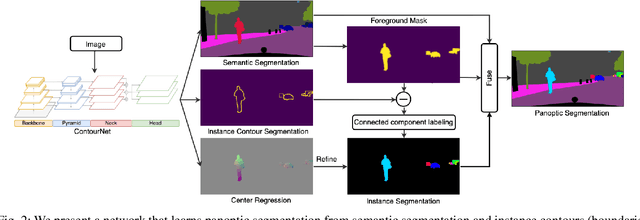
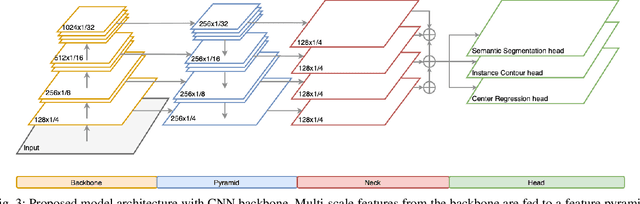
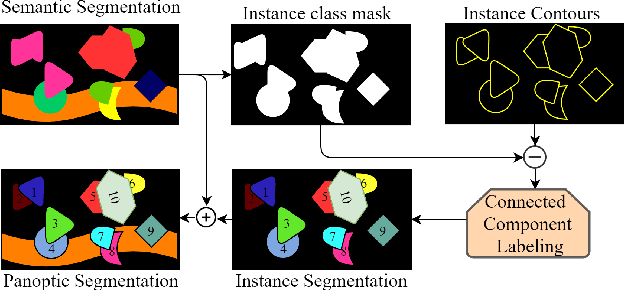
Panoptic Segmentation aims to provide an understanding of background (stuff) and instances of objects (things) at a pixel level. It combines the separate tasks of semantic segmentation (pixel-level classification) and instance segmentation to build a single unified scene understanding task. Typically, panoptic segmentation is derived by combining semantic and instance segmentation tasks that are learned separately or jointly (multi-task networks). In general, instance segmentation networks are built by adding a foreground mask estimation layer on top of object detectors or using instance clustering methods that assign a pixel to an instance center. In this work, we present a fully convolution neural network that learns instance segmentation from semantic segmentation and instance contours (boundaries of things). Instance contours along with semantic segmentation yield a boundary-aware semantic segmentation of things. Connected component labeling on these results produces instance segmentation. We merge semantic and instance segmentation results to output panoptic segmentation. We evaluate our proposed method on the CityScapes dataset to demonstrate qualitative and quantitative performances along with several ablation studies.
ProxEmo: Gait-based Emotion Learning and Multi-view Proxemic Fusion for Socially-Aware Robot Navigation
Mar 02, 2020
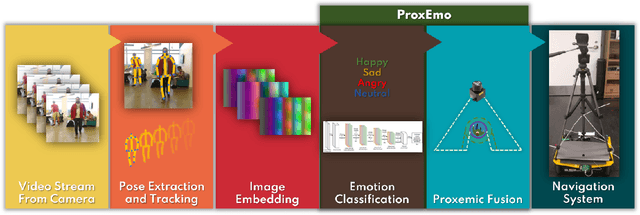
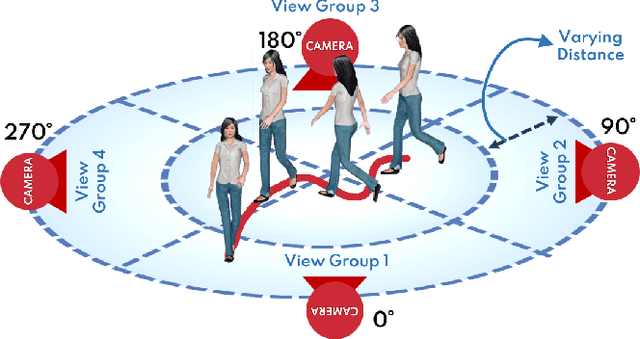
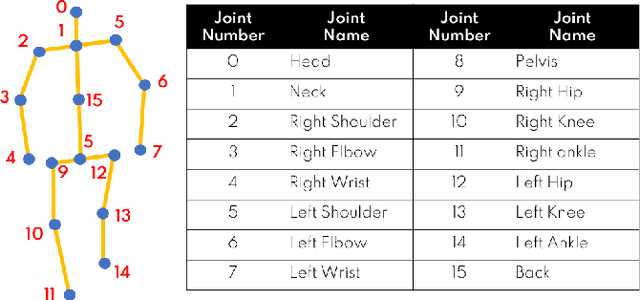
We present ProxEmo, a novel end-to-end emotion prediction algorithm for socially aware robot navigation among pedestrians. Our approach predicts the perceived emotions of a pedestrian from walking gaits, which is then used for emotion-guided navigation taking into account social and proxemic constraints. To classify emotions, we propose a multi-view skeleton graph convolution-based model that works on a commodity camera mounted onto a moving robot. Our emotion recognition is integrated into a mapless navigation scheme and makes no assumptions about the environment of pedestrian motion. It achieves a mean average emotion prediction precision of 82.47% on the Emotion-Gait benchmark dataset. We outperform current state-of-art algorithms for emotion recognition from 3D gaits. We highlight its benefits in terms of navigation in indoor scenes using a Clearpath Jackal robot.
PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes
May 26, 2018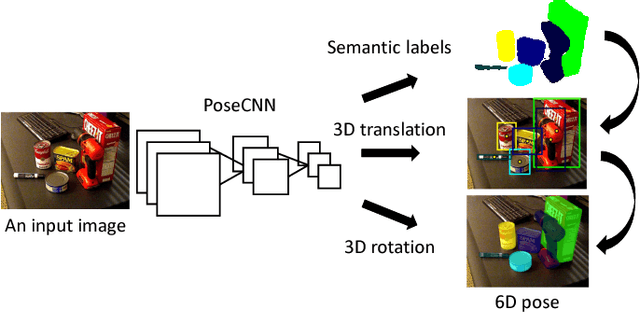
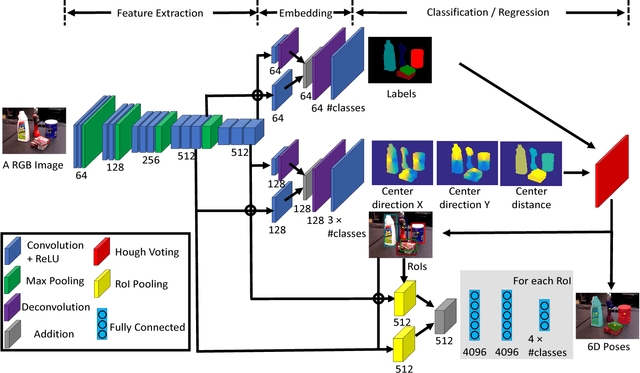
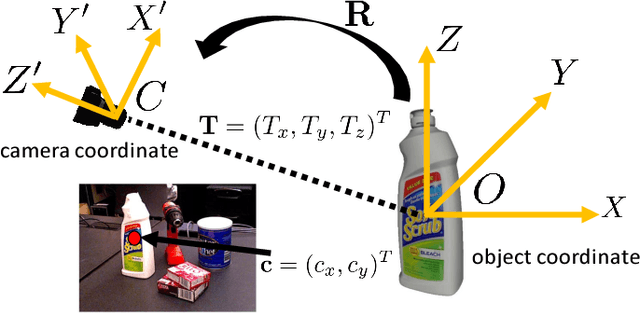
Estimating the 6D pose of known objects is important for robots to interact with the real world. The problem is challenging due to the variety of objects as well as the complexity of a scene caused by clutter and occlusions between objects. In this work, we introduce PoseCNN, a new Convolutional Neural Network for 6D object pose estimation. PoseCNN estimates the 3D translation of an object by localizing its center in the image and predicting its distance from the camera. The 3D rotation of the object is estimated by regressing to a quaternion representation. We also introduce a novel loss function that enables PoseCNN to handle symmetric objects. In addition, we contribute a large scale video dataset for 6D object pose estimation named the YCB-Video dataset. Our dataset provides accurate 6D poses of 21 objects from the YCB dataset observed in 92 videos with 133,827 frames. We conduct extensive experiments on our YCB-Video dataset and the OccludedLINEMOD dataset to show that PoseCNN is highly robust to occlusions, can handle symmetric objects, and provide accurate pose estimation using only color images as input. When using depth data to further refine the poses, our approach achieves state-of-the-art results on the challenging OccludedLINEMOD dataset. Our code and dataset are available at https://rse-lab.cs.washington.edu/projects/posecnn/.
PERCH: Perception via Search for Multi-Object Recognition and Localization
Mar 16, 2016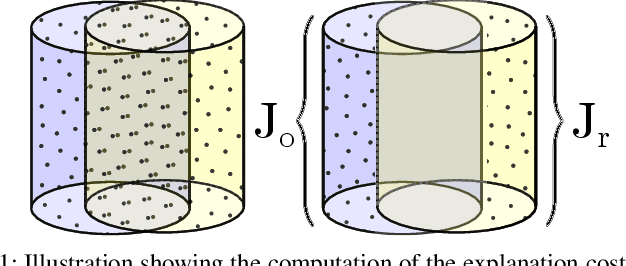
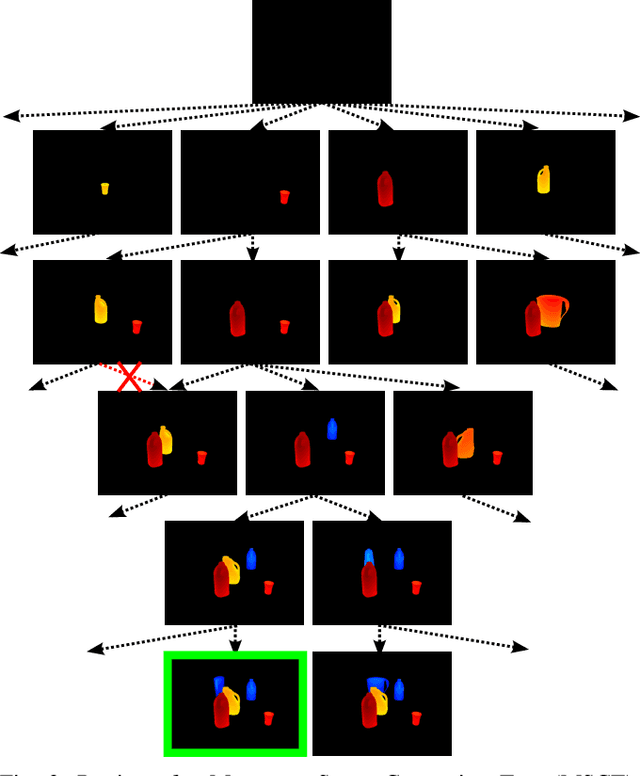

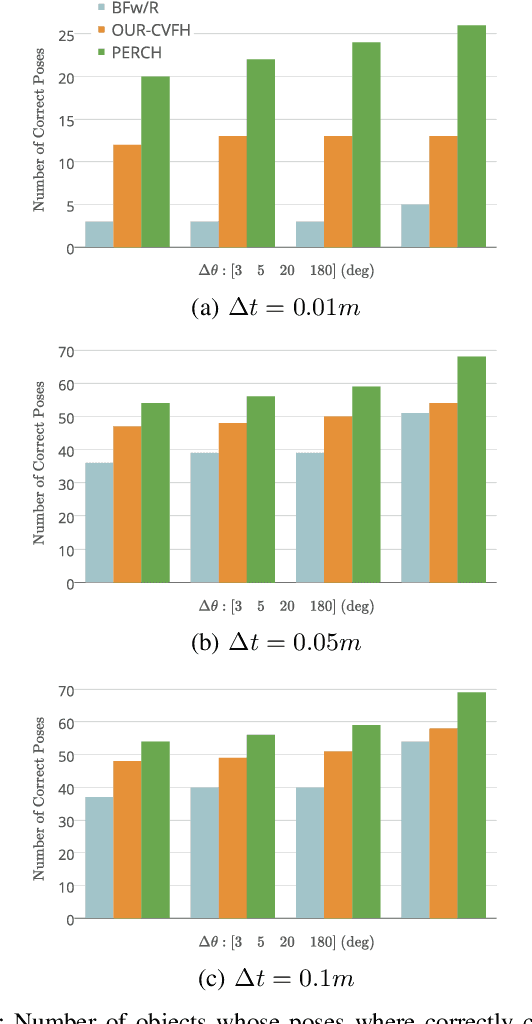
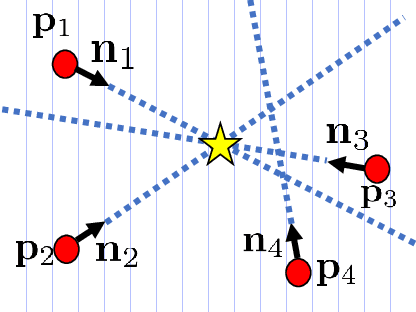
In many robotic domains such as flexible automated manufacturing or personal assistance, a fundamental perception task is that of identifying and localizing objects whose 3D models are known. Canonical approaches to this problem include discriminative methods that find correspondences between feature descriptors computed over the model and observed data. While these methods have been employed successfully, they can be unreliable when the feature descriptors fail to capture variations in observed data; a classic cause being occlusion. As a step towards deliberative reasoning, we present PERCH: PErception via SeaRCH, an algorithm that seeks to find the best explanation of the observed sensor data by hypothesizing possible scenes in a generative fashion. Our contributions are: i) formulating the multi-object recognition and localization task as an optimization problem over the space of hypothesized scenes, ii) exploiting structure in the optimization to cast it as a combinatorial search problem on what we call the Monotone Scene Generation Tree, and iii) leveraging parallelization and recent advances in multi-heuristic search in making combinatorial search tractable. We prove that our system can guaranteedly produce the best explanation of the scene under the chosen cost function, and validate our claims on real world RGB-D test data. Our experimental results show that we can identify and localize objects under heavy occlusion--cases where state-of-the-art methods struggle.