 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemCtrl: Using MLLMs as Active Memory Controllers on Embodied Agents
Jan 28, 2026Foundation models rely on in-context learning for personalized decision making. The limited size of this context window necessitates memory compression and retrieval systems like RAG. These systems however often treat memory as large offline storage spaces, which is unfavorable for embodied agents that are expected to operate under strict memory and compute constraints, online. In this work, we propose MemCtrl, a novel framework that uses Multimodal Large Language Models (MLLMs) for pruning memory online. MemCtrl augments MLLMs with a trainable memory head μthat acts as a gate to determine which observations or reflections to retain, update, or discard during exploration. We evaluate with training two types of μ, 1) via an offline expert, and 2) via online RL, and observe significant improvement in overall embodied task completion ability on μ-augmented MLLMs. In particular, on augmenting two low performing MLLMs with MemCtrl on multiple subsets of the EmbodiedBench benchmark, we observe that μ-augmented MLLMs show an improvement of around 16% on average, with over 20% on specific instruction subsets. Finally, we present a qualitative analysis on the memory fragments collected by μ, noting the superior performance of μaugmented MLLMs on long and complex instruction types.
Is Generative Communication between Embodied Agents Good for Zero-Shot ObjectNav?
Aug 03, 2024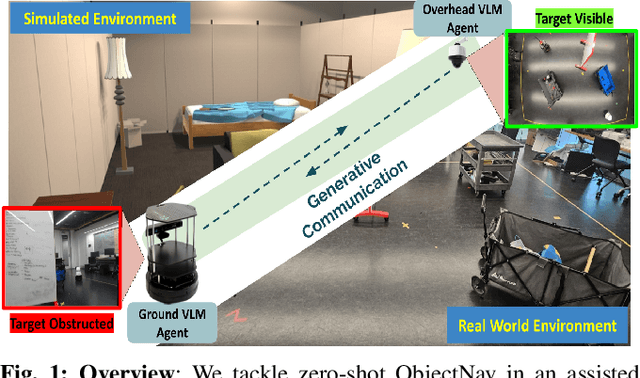
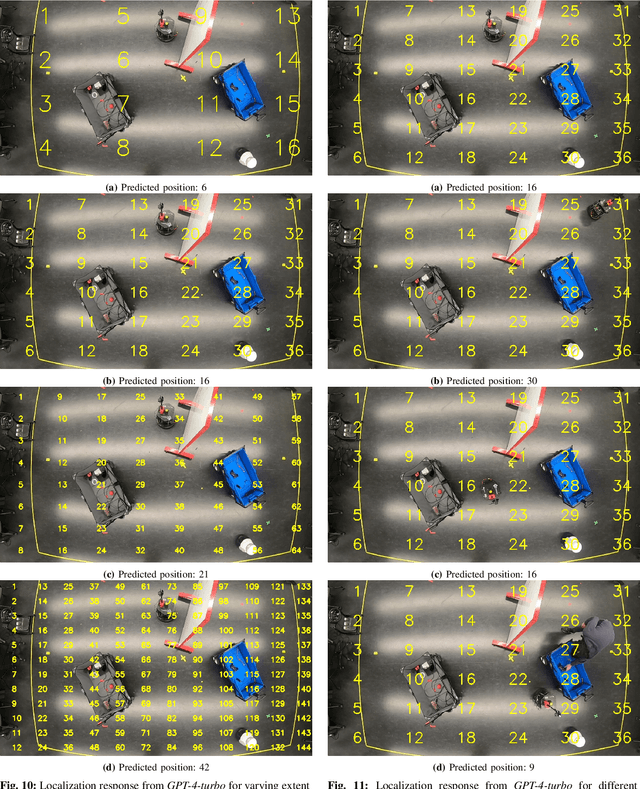


In Zero-Shot ObjectNav, an embodied ground agent is expected to navigate to a target object specified by a natural language label without any environment-specific fine-tuning. This is challenging, given the limited view of a ground agent and its independent exploratory behavior. To address these issues, we consider an assistive overhead agent with a bounded global view alongside the ground agent and present two coordinated navigation schemes for judicious exploration. We establish the influence of the Generative Communication (GC) between the embodied agents equipped with Vision-Language Models (VLMs) in improving zero-shot ObjectNav, achieving a 10% improvement in the ground agent's ability to find the target object in comparison with an unassisted setup in simulation. We further analyze the GC for unique traits quantifying the presence of hallucination and cooperation. In particular, we identify a unique trait of "preemptive hallucination" specific to our embodied setting, where the overhead agent assumes that the ground agent has executed an action in the dialogue when it is yet to move. Finally, we conduct real-world inferences with GC and showcase qualitative examples where countering pre-emptive hallucination via prompt finetuning improves real-world ObjectNav performance.
Embodied Question Answering via Multi-LLM Systems
Jun 18, 2024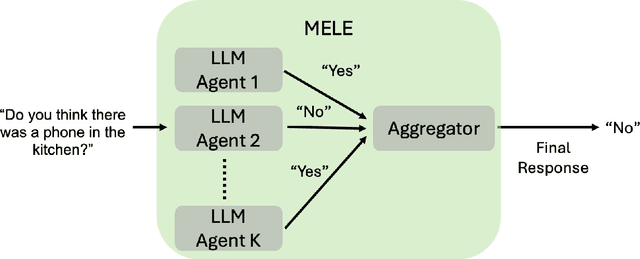
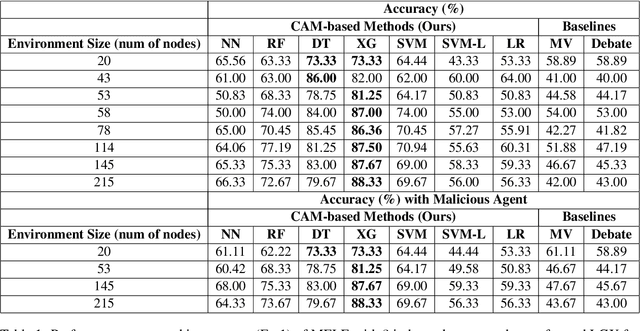
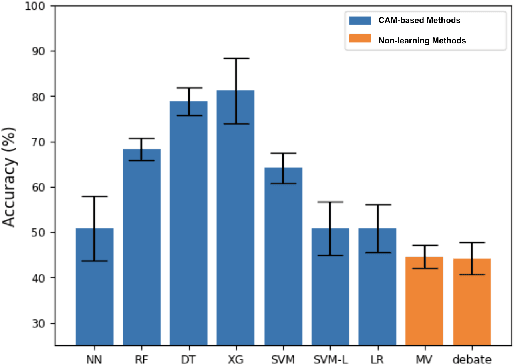
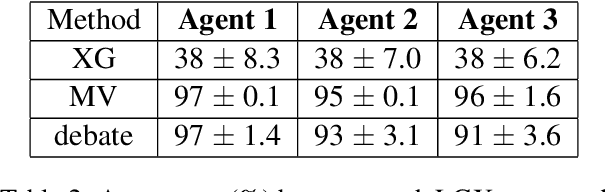
Embodied Question Answering (EQA) is an important problem, which involves an agent exploring the environment to answer user queries. In the existing literature, EQA has exclusively been studied in single-agent scenarios, where exploration can be time-consuming and costly. In this work, we consider EQA in a multi-agent framework involving multiple large language models (LLM) based agents independently answering queries about a household environment. To generate one answer for each query, we use the individual responses to train a Central Answer Model (CAM) that aggregates responses for a robust answer. Using CAM, we observe a $50\%$ higher EQA accuracy when compared against aggregation methods for ensemble LLM, such as voting schemes and debates. CAM does not require any form of agent communication, alleviating it from the associated costs. We ablate CAM with various nonlinear (neural network, random forest, decision tree, XGBoost) and linear (logistic regression classifier, SVM) algorithms. Finally, we present a feature importance analysis for CAM via permutation feature importance (PFI), quantifying CAMs reliance on each independent agent and query context.
S-EQA: Tackling Situational Queries in Embodied Question Answering
May 08, 2024We present and tackle the problem of Embodied Question Answering (EQA) with Situational Queries (S-EQA) in a household environment. Unlike prior EQA work tackling simple queries that directly reference target objects and quantifiable properties pertaining them, EQA with situational queries (such as "Is the bathroom clean and dry?") is more challenging, as the agent needs to figure out not just what the target objects pertaining to the query are, but also requires a consensus on their states to be answerable. Towards this objective, we first introduce a novel Prompt-Generate-Evaluate (PGE) scheme that wraps around an LLM's output to create a dataset of unique situational queries, corresponding consensus object information, and predicted answers. PGE maintains uniqueness among the generated queries, using multiple forms of semantic similarity. We validate the generated dataset via a large scale user-study conducted on M-Turk, and introduce it as S-EQA, the first dataset tackling EQA with situational queries. Our user study establishes the authenticity of S-EQA with a high 97.26% of the generated queries being deemed answerable, given the consensus object data. Conversely, we observe a low correlation of 46.2% on the LLM-predicted answers to human-evaluated ones; indicating the LLM's poor capability in directly answering situational queries, while establishing S-EQA's usability in providing a human-validated consensus for an indirect solution. We evaluate S-EQA via Visual Question Answering (VQA) on VirtualHome, which unlike other simulators, contains several objects with modifiable states that also visually appear different upon modification -- enabling us to set a quantitative benchmark for S-EQA. To the best of our knowledge, this is the first work to introduce EQA with situational queries, and also the first to use a generative approach for query creation.
Can LLMs Generate Human-Like Wayfinding Instructions? Towards Platform-Agnostic Embodied Instruction Synthesis
Mar 31, 2024We present a novel approach to automatically synthesize "wayfinding instructions" for an embodied robot agent. In contrast to prior approaches that are heavily reliant on human-annotated datasets designed exclusively for specific simulation platforms, our algorithm uses in-context learning to condition an LLM to generate instructions using just a few references. Using an LLM-based Visual Question Answering strategy, we gather detailed information about the environment which is used by the LLM for instruction synthesis. We implement our approach on multiple simulation platforms including Matterport3D, AI Habitat and ThreeDWorld, thereby demonstrating its platform-agnostic nature. We subjectively evaluate our approach via a user study and observe that 83.3% of users find the synthesized instructions accurately capture the details of the environment and show characteristics similar to those of human-generated instructions. Further, we conduct zero-shot navigation with multiple approaches on the REVERIE dataset using the generated instructions, and observe very close correlation with the baseline on standard success metrics (< 1% change in SR), quantifying the viability of generated instructions in replacing human-annotated data. We finally discuss the applicability of our approach in enabling a generalizable evaluation of embodied navigation policies. To the best of our knowledge, ours is the first LLM-driven approach capable of generating "human-like" instructions in a platform-agnostic manner, without training.
Right Place, Right Time! Towards ObjectNav for Non-Stationary Goals
Mar 14, 2024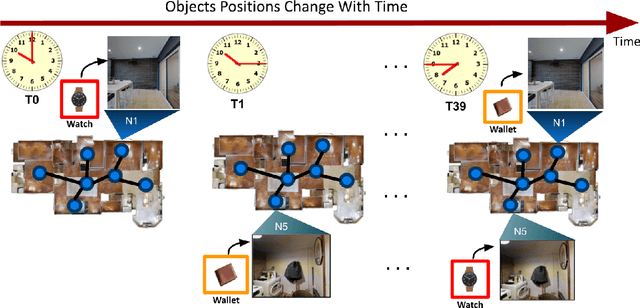

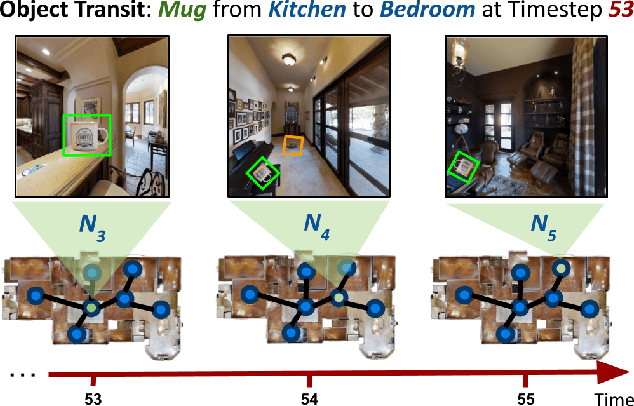

We present a novel approach to tackle the ObjectNav task for non-stationary and potentially occluded targets in an indoor environment. We refer to this task Portable ObjectNav (or P-ObjectNav), and in this work, present its formulation, feasibility, and a navigation benchmark using a novel memory-enhanced LLM-based policy. In contrast to ObjNav where target object locations are fixed for each episode, P-ObjectNav tackles the challenging case where the target objects move during the episode. This adds a layer of time-sensitivity to navigation, and is particularly relevant in scenarios where the agent needs to find portable targets (e.g. misplaced wallets) in human-centric environments. The agent needs to estimate not just the correct location of the target, but also the time at which the target is at that location for visual grounding -- raising the question about the feasibility of the task. We address this concern by inferring results on two cases for object placement: one where the objects placed follow a routine or a path, and the other where they are placed at random. We dynamize Matterport3D for these experiments, and modify PPO and LLM-based navigation policies for evaluation. Using PPO, we observe that agent performance in the random case stagnates, while the agent in the routine-following environment continues to improve, allowing us to infer that P-ObjectNav is solvable in environments with routine-following object placement. Using memory-enhancement on an LLM-based policy, we set a benchmark for P-ObjectNav. Our memory-enhanced agent significantly outperforms their non-memory-based counterparts across object placement scenarios by 71.76% and 74.68% on average when measured by Success Rate (SR) and Success Rate weighted by Path Length (SRPL), showing the influence of memory on improving P-ObjectNav performance. Our code and dataset will be made publicly available.
Can an Embodied Agent Find Your "Cat-shaped Mug"? LLM-Based Zero-Shot Object Navigation
Mar 06, 2023We present LGX, a novel algorithm for Object Goal Navigation in a "language-driven, zero-shot manner", where an embodied agent navigates to an arbitrarily described target object in a previously unexplored environment. Our approach leverages the capabilities of Large Language Models (LLMs) for making navigational decisions by mapping the LLMs implicit knowledge about the semantic context of the environment into sequential inputs for robot motion planning. Simultaneously, we also conduct generalized target object detection using a pre-trained Vision-Language grounding model. We achieve state-of-the-art zero-shot object navigation results on RoboTHOR with a success rate (SR) improvement of over 27% over the current baseline of the OWL-ViT CLIP on Wheels (OWL CoW). Furthermore, we study the usage of LLMs for robot navigation and present an analysis of the various semantic factors affecting model output. Finally, we showcase the benefits of our approach via real-world experiments that indicate the superior performance of LGX when navigating to and detecting visually unique objects.
CLIP-Nav: Using CLIP for Zero-Shot Vision-and-Language Navigation
Nov 30, 2022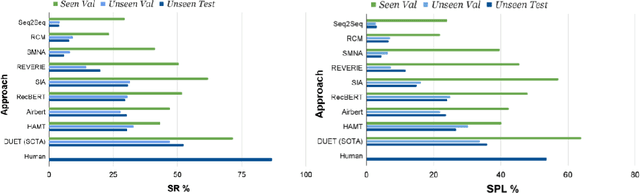
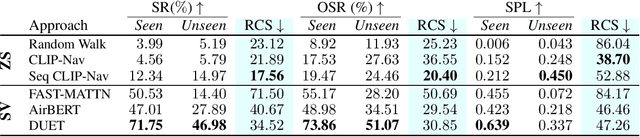


Household environments are visually diverse. Embodied agents performing Vision-and-Language Navigation (VLN) in the wild must be able to handle this diversity, while also following arbitrary language instructions. Recently, Vision-Language models like CLIP have shown great performance on the task of zero-shot object recognition. In this work, we ask if these models are also capable of zero-shot language grounding. In particular, we utilize CLIP to tackle the novel problem of zero-shot VLN using natural language referring expressions that describe target objects, in contrast to past work that used simple language templates describing object classes. We examine CLIP's capability in making sequential navigational decisions without any dataset-specific finetuning, and study how it influences the path that an agent takes. Our results on the coarse-grained instruction following task of REVERIE demonstrate the navigational capability of CLIP, surpassing the supervised baseline in terms of both success rate (SR) and success weighted by path length (SPL). More importantly, we quantitatively show that our CLIP-based zero-shot approach generalizes better to show consistent performance across environments when compared to SOTA, fully supervised learning approaches when evaluated via Relative Change in Success (RCS).
Can a Robot Trust You? A DRL-Based Approach to Trust-Driven Human-Guided Navigation
Nov 01, 2020
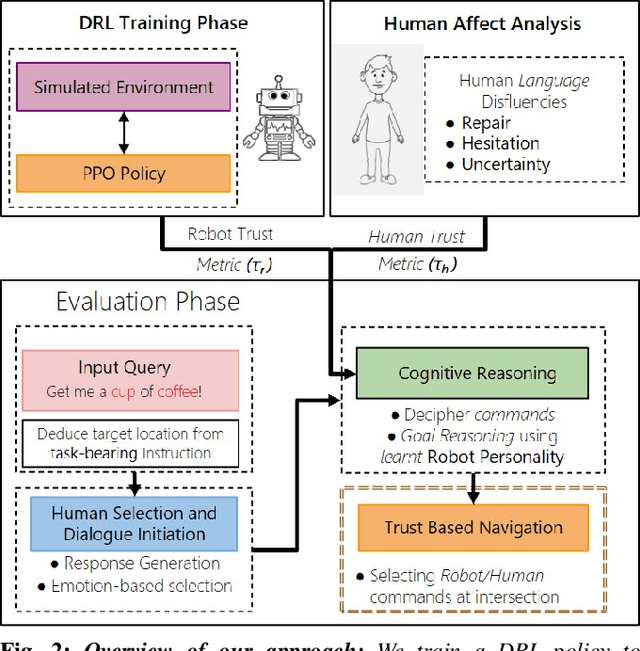
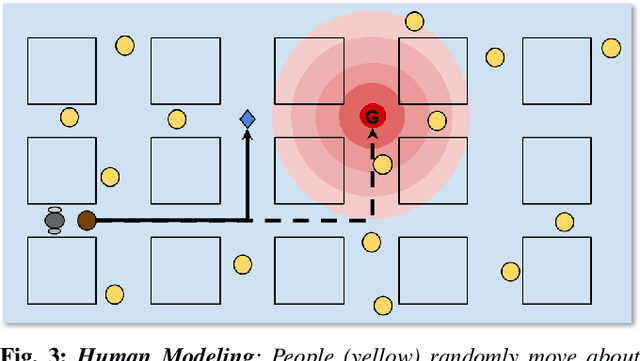
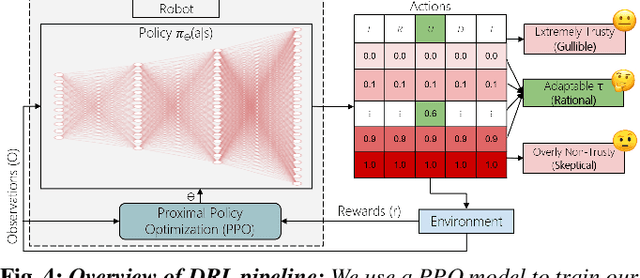
Humans are known to construct cognitive maps of their everyday surroundings using a variety of perceptual inputs. As such, when a human is asked for directions to a particular location, their wayfinding capability in converting this cognitive map into directional instructions is challenged. Owing to spatial anxiety, the language used in the spoken instructions can be vague and often unclear. To account for this unreliability in navigational guidance, we propose a novel Deep Reinforcement Learning (DRL) based trust-driven robot navigation algorithm that learns humans' trustworthiness to perform a language guided navigation task. Our approach seeks to answer the question as to whether a robot can trust a human's navigational guidance or not. To this end, we look at training a policy that learns to navigate towards a goal location using only trustworthy human guidance, driven by its own robot trust metric. We look at quantifying various affective features from language-based instructions and incorporate them into our policy's observation space in the form of a human trust metric. We utilize both these trust metrics into an optimal cognitive reasoning scheme that decides when and when not to trust the given guidance. Our results show that the learned policy can navigate the environment in an optimal, time-efficient manner as opposed to an explorative approach that performs the same task. We showcase the efficacy of our results both in simulation and a real-world environment.
ProxEmo: Gait-based Emotion Learning and Multi-view Proxemic Fusion for Socially-Aware Robot Navigation
Mar 02, 2020
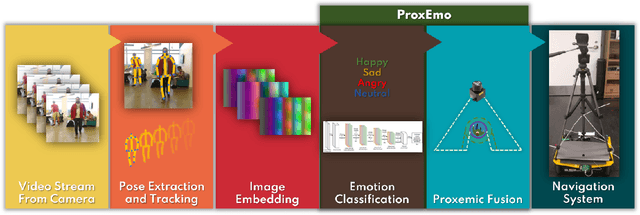
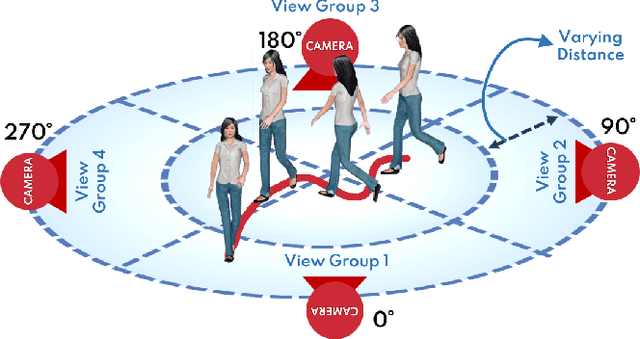
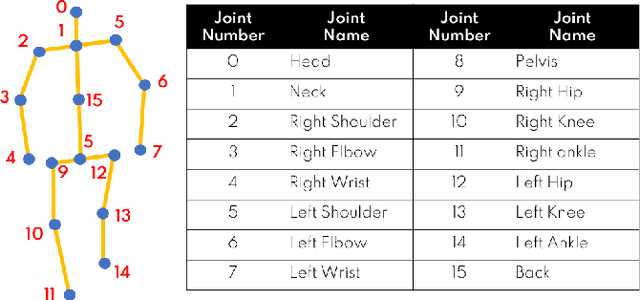
We present ProxEmo, a novel end-to-end emotion prediction algorithm for socially aware robot navigation among pedestrians. Our approach predicts the perceived emotions of a pedestrian from walking gaits, which is then used for emotion-guided navigation taking into account social and proxemic constraints. To classify emotions, we propose a multi-view skeleton graph convolution-based model that works on a commodity camera mounted onto a moving robot. Our emotion recognition is integrated into a mapless navigation scheme and makes no assumptions about the environment of pedestrian motion. It achieves a mean average emotion prediction precision of 82.47% on the Emotion-Gait benchmark dataset. We outperform current state-of-art algorithms for emotion recognition from 3D gaits. We highlight its benefits in terms of navigation in indoor scenes using a Clearpath Jackal robot.