 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering the Representation Geometry of Minimal Cores in Overcomplete Reasoning Traces
May 14, 2026Language models often generate long chain-of-thought traces, but it remains unclear how much of this reasoning is necessary for preserving the final prediction. We study this through the lens of overcomplete reasoning traces: generated traces that contain more intermediate steps than are needed to support the model's answer. We define the minimal core as the smallest subset of steps that preserves either the final answer or predictive distribution, and introduce metrics for compression ratio, redundancy mass, step necessity, and necessity concentration. Across six deliberative reasoning benchmarks spanning arithmetic, competition mathematics, expert scientific reasoning, and commonsense multi-hop QA, we find substantial overcompleteness: on average, 46% of steps are removable under greedy minimal-core extraction while preserving the original answer in 86% of cases. We also find that predictive support is concentrated: the top three steps account for 65% of measured necessity mass on average. Beyond compression, minimal cores expose a cleaner geometry of reasoning: compared with full traces, they improve correct-incorrect trace separation by 11 points, reduce estimated intrinsic dimensionality by 34%, and transfer across model families with 85% off-diagonal answer retention. Theoretically, we establish existence of minimal sufficient subsets, local irreducibility guarantees for greedy elimination, and certificates of overcompleteness and sparse necessity. Together, these results suggest that full reasoning traces are often verbose and overcomplete, while minimal cores isolate the effective support underlying language-model predictions.
AMUSE: Audio-Visual Benchmark and Alignment Framework for Agentic Multi-Speaker Understanding
Dec 18, 2025

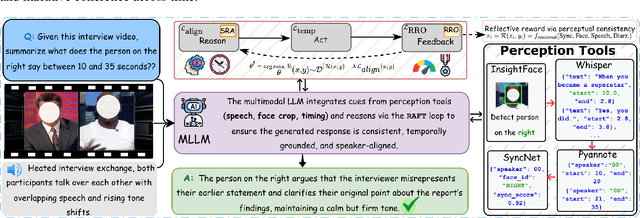
Recent multimodal large language models (MLLMs) such as GPT-4o and Qwen3-Omni show strong perception but struggle in multi-speaker, dialogue-centric settings that demand agentic reasoning tracking who speaks, maintaining roles, and grounding events across time. These scenarios are central to multimodal audio-video understanding, where models must jointly reason over audio and visual streams in applications such as conversational video assistants and meeting analytics. We introduce AMUSE, a benchmark designed around tasks that are inherently agentic, requiring models to decompose complex audio-visual interactions into planning, grounding, and reflection steps. It evaluates MLLMs across three modes zero-shot, guided, and agentic and six task families, including spatio-temporal speaker grounding and multimodal dialogue summarization. Across all modes, current models exhibit weak multi-speaker reasoning and inconsistent behavior under both non-agentic and agentic evaluation. Motivated by the inherently agentic nature of these tasks and recent advances in LLM agents, we propose RAFT, a data-efficient agentic alignment framework that integrates reward optimization with intrinsic multimodal self-evaluation as reward and selective parameter adaptation for data and parameter efficient updates. Using RAFT, we achieve up to 39.52\% relative improvement in accuracy on our benchmark. Together, AMUSE and RAFT provide a practical platform for examining agentic reasoning in multimodal models and improving their capabilities.
AURA: A Fine-Grained Benchmark and Decomposed Metric for Audio-Visual Reasoning
Aug 10, 2025Current audio-visual (AV) benchmarks focus on final answer accuracy, overlooking the underlying reasoning process. This makes it difficult to distinguish genuine comprehension from correct answers derived through flawed reasoning or hallucinations. To address this, we introduce AURA (Audio-visual Understanding and Reasoning Assessment), a benchmark for evaluating the cross-modal reasoning capabilities of Audio-Visual Large Language Models (AV-LLMs) and Omni-modal Language Models (OLMs). AURA includes questions across six challenging cognitive domains, such as causality, timbre and pitch, tempo and AV synchronization, unanswerability, implicit distractions, and skill profiling, explicitly designed to be unanswerable from a single modality. This forces models to construct a valid logical path grounded in both audio and video, setting AURA apart from AV datasets that allow uni-modal shortcuts. To assess reasoning traces, we propose a novel metric, AuraScore, which addresses the lack of robust tools for evaluating reasoning fidelity. It decomposes reasoning into two aspects: (i) Factual Consistency - whether reasoning is grounded in perceptual evidence, and (ii) Core Inference - the logical validity of each reasoning step. Evaluations of SOTA models on AURA reveal a critical reasoning gap: although models achieve high accuracy (up to 92% on some tasks), their Factual Consistency and Core Inference scores fall below 45%. This discrepancy highlights that models often arrive at correct answers through flawed logic, underscoring the need for our benchmark and paving the way for more robust multimodal evaluation.
MAGNET: A Multi-agent Framework for Finding Audio-Visual Needles by Reasoning over Multi-Video Haystacks
Jun 08, 2025Large multimodal models (LMMs) have shown remarkable progress in audio-visual understanding, yet they struggle with real-world scenarios that require complex reasoning across extensive video collections. Existing benchmarks for video question answering remain limited in scope, typically involving one clip per query, which falls short of representing the challenges of large-scale, audio-visual retrieval and reasoning encountered in practical applications. To bridge this gap, we introduce a novel task named AV-HaystacksQA, where the goal is to identify salient segments across different videos in response to a query and link them together to generate the most informative answer. To this end, we present AVHaystacks, an audio-visual benchmark comprising 3100 annotated QA pairs designed to assess the capabilities of LMMs in multi-video retrieval and temporal grounding task. Additionally, we propose a model-agnostic, multi-agent framework MAGNET to address this challenge, achieving up to 89% and 65% relative improvements over baseline methods on BLEU@4 and GPT evaluation scores in QA task on our proposed AVHaystacks. To enable robust evaluation of multi-video retrieval and temporal grounding for optimal response generation, we introduce two new metrics, STEM, which captures alignment errors between a ground truth and a predicted step sequence and MTGS, to facilitate balanced and interpretable evaluation of segment-level grounding performance. Project: https://schowdhury671.github.io/magnet_project/
Aurelia: Test-time Reasoning Distillation in Audio-Visual LLMs
Mar 29, 2025Recent advancements in reasoning optimization have greatly enhanced the performance of large language models (LLMs). However, existing work fails to address the complexities of audio-visual scenarios, underscoring the need for further research. In this paper, we introduce AURELIA, a novel actor-critic based audio-visual (AV) reasoning framework that distills structured, step-by-step reasoning into AVLLMs at test time, improving their ability to process complex multi-modal inputs without additional training or fine-tuning. To further advance AVLLM reasoning skills, we present AVReasonBench, a challenging benchmark comprising 4500 audio-visual questions, each paired with detailed step-by-step reasoning. Our benchmark spans six distinct tasks, including AV-GeoIQ, which evaluates AV reasoning combined with geographical and cultural knowledge. Evaluating 18 AVLLMs on AVReasonBench reveals significant limitations in their multi-modal reasoning capabilities. Using AURELIA, we achieve up to a 100% relative improvement, demonstrating its effectiveness. This performance gain highlights the potential of reasoning-enhanced data generation for advancing AVLLMs in real-world applications. Our code and data will be publicly released at: https: //github.com/schowdhury671/aurelia.
AVTrustBench: Assessing and Enhancing Reliability and Robustness in Audio-Visual LLMs
Jan 03, 2025



With the rapid advancement of Multi-modal Large Language Models (MLLMs), several diagnostic benchmarks have recently been developed to assess these models' multi-modal reasoning proficiency. However, these benchmarks are restricted to assessing primarily the visual aspect and do not examine the holistic audio-visual (AV) understanding. Moreover, currently, there are no benchmarks that investigate the capabilities of AVLLMs to calibrate their responses when presented with perturbed inputs. To this end, we introduce Audio-Visual Trustworthiness assessment Benchmark (AVTrustBench), comprising 600K samples spanning over 9 meticulously crafted tasks, evaluating the capabilities of AVLLMs across three distinct dimensions: Adversarial attack, Compositional reasoning, and Modality-specific dependency. Using our benchmark we extensively evaluate 13 state-of-the-art AVLLMs. The findings reveal that the majority of existing models fall significantly short of achieving human-like comprehension, offering valuable insights for future research directions. To alleviate the limitations in the existing approaches, we further propose a robust, model-agnostic calibrated audio-visual preference optimization based training strategy CAVPref, obtaining a gain up to 30.19% across all 9 tasks. We will publicly release our code and benchmark to facilitate future research in this direction.
Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time
Jul 01, 2024



Leveraging Large Language Models' remarkable proficiency in text-based tasks, recent works on Multi-modal LLMs (MLLMs) extend them to other modalities like vision and audio. However, the progress in these directions has been mostly focused on tasks that only require a coarse-grained understanding of the audio-visual semantics. We present Meerkat, an audio-visual LLM equipped with a fine-grained understanding of image and audio both spatially and temporally. With a new modality alignment module based on optimal transport and a cross-attention module that enforces audio-visual consistency, Meerkat can tackle challenging tasks such as audio referred image grounding, image guided audio temporal localization, and audio-visual fact-checking. Moreover, we carefully curate a large dataset AVFIT that comprises 3M instruction tuning samples collected from open-source datasets, and introduce MeerkatBench that unifies five challenging audio-visual tasks. We achieve state-of-the-art performance on all these downstream tasks with a relative improvement of up to 37.12%.
MeLFusion: Synthesizing Music from Image and Language Cues using Diffusion Models
Jun 07, 2024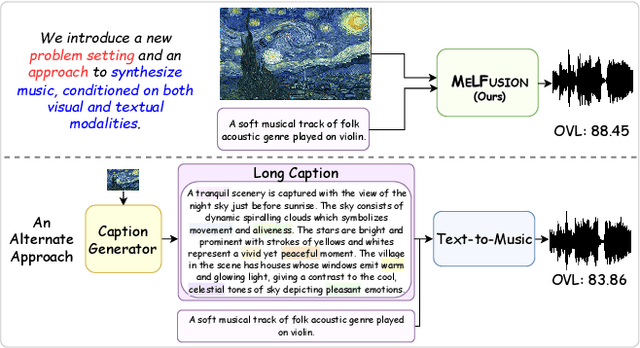
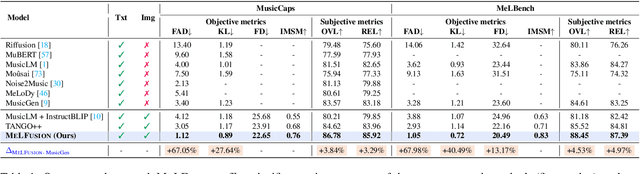
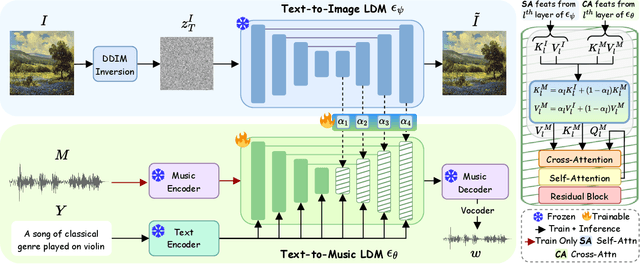
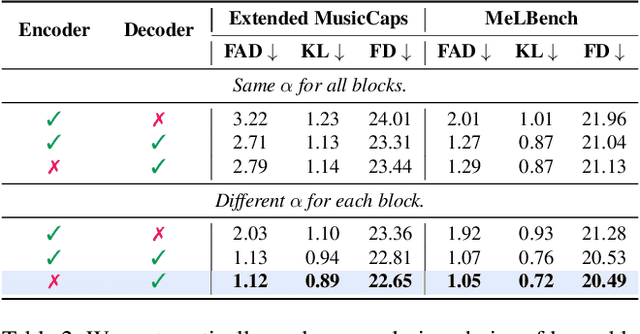
Music is a universal language that can communicate emotions and feelings. It forms an essential part of the whole spectrum of creative media, ranging from movies to social media posts. Machine learning models that can synthesize music are predominantly conditioned on textual descriptions of it. Inspired by how musicians compose music not just from a movie script, but also through visualizations, we propose MeLFusion, a model that can effectively use cues from a textual description and the corresponding image to synthesize music. MeLFusion is a text-to-music diffusion model with a novel "visual synapse", which effectively infuses the semantics from the visual modality into the generated music. To facilitate research in this area, we introduce a new dataset MeLBench, and propose a new evaluation metric IMSM. Our exhaustive experimental evaluation suggests that adding visual information to the music synthesis pipeline significantly improves the quality of generated music, measured both objectively and subjectively, with a relative gain of up to 67.98% on the FAD score. We hope that our work will gather attention to this pragmatic, yet relatively under-explored research area.
Can LLMs Generate Human-Like Wayfinding Instructions? Towards Platform-Agnostic Embodied Instruction Synthesis
Mar 31, 2024We present a novel approach to automatically synthesize "wayfinding instructions" for an embodied robot agent. In contrast to prior approaches that are heavily reliant on human-annotated datasets designed exclusively for specific simulation platforms, our algorithm uses in-context learning to condition an LLM to generate instructions using just a few references. Using an LLM-based Visual Question Answering strategy, we gather detailed information about the environment which is used by the LLM for instruction synthesis. We implement our approach on multiple simulation platforms including Matterport3D, AI Habitat and ThreeDWorld, thereby demonstrating its platform-agnostic nature. We subjectively evaluate our approach via a user study and observe that 83.3% of users find the synthesized instructions accurately capture the details of the environment and show characteristics similar to those of human-generated instructions. Further, we conduct zero-shot navigation with multiple approaches on the REVERIE dataset using the generated instructions, and observe very close correlation with the baseline on standard success metrics (< 1% change in SR), quantifying the viability of generated instructions in replacing human-annotated data. We finally discuss the applicability of our approach in enabling a generalizable evaluation of embodied navigation policies. To the best of our knowledge, ours is the first LLM-driven approach capable of generating "human-like" instructions in a platform-agnostic manner, without training.
APoLLo: Unified Adapter and Prompt Learning for Vision Language Models
Dec 04, 2023The choice of input text prompt plays a critical role in the performance of Vision-Language Pretrained (VLP) models such as CLIP. We present APoLLo, a unified multi-modal approach that combines Adapter and Prompt learning for Vision-Language models. Our method is designed to substantially improve the generalization capabilities of VLP models when they are fine-tuned in a few-shot setting. We introduce trainable cross-attention-based adapter layers in conjunction with vision and language encoders to strengthen the alignment between the two modalities. We enforce consistency between the respective encoder branches (receiving augmented inputs) to prevent overfitting in downstream tasks. Our method is evaluated on three representative tasks: generalization to novel classes, cross-dataset evaluation, and unseen domain shifts. In practice, APoLLo achieves a relative gain up to 6.03% over MaPLe (SOTA) on novel classes for 10 diverse image recognition datasets.