 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver++: Generative Video Compositing for Layer Interaction Effects
Dec 22, 2025In professional video compositing workflows, artists must manually create environmental interactions-such as shadows, reflections, dust, and splashes-between foreground subjects and background layers. Existing video generative models struggle to preserve the input video while adding such effects, and current video inpainting methods either require costly per-frame masks or yield implausible results. We introduce augmented compositing, a new task that synthesizes realistic, semi-transparent environmental effects conditioned on text prompts and input video layers, while preserving the original scene. To address this task, we present Over++, a video effect generation framework that makes no assumptions about camera pose, scene stationarity, or depth supervision. We construct a paired effect dataset tailored for this task and introduce an unpaired augmentation strategy that preserves text-driven editability. Our method also supports optional mask control and keyframe guidance without requiring dense annotations. Despite training on limited data, Over++ produces diverse and realistic environmental effects and outperforms existing baselines in both effect generation and scene preservation.
The Aging Multiverse: Generating Condition-Aware Facial Aging Tree via Training-Free Diffusion
Jun 26, 2025We introduce the Aging Multiverse, a framework for generating multiple plausible facial aging trajectories from a single image, each conditioned on external factors such as environment, health, and lifestyle. Unlike prior methods that model aging as a single deterministic path, our approach creates an aging tree that visualizes diverse futures. To enable this, we propose a training-free diffusion-based method that balances identity preservation, age accuracy, and condition control. Our key contributions include attention mixing to modulate editing strength and a Simulated Aging Regularization strategy to stabilize edits. Extensive experiments and user studies demonstrate state-of-the-art performance across identity preservation, aging realism, and conditional alignment, outperforming existing editing and age-progression models, which often fail to account for one or more of the editing criteria. By transforming aging into a multi-dimensional, controllable, and interpretable process, our approach opens up new creative and practical avenues in digital storytelling, health education, and personalized visualization.
MyTimeMachine: Personalized Facial Age Transformation
Nov 21, 2024Facial aging is a complex process, highly dependent on multiple factors like gender, ethnicity, lifestyle, etc., making it extremely challenging to learn a global aging prior to predict aging for any individual accurately. Existing techniques often produce realistic and plausible aging results, but the re-aged images often do not resemble the person's appearance at the target age and thus need personalization. In many practical applications of virtual aging, e.g. VFX in movies and TV shows, access to a personal photo collection of the user depicting aging in a small time interval (20$\sim$40 years) is often available. However, naive attempts to personalize global aging techniques on personal photo collections often fail. Thus, we propose MyTimeMachine (MyTM), which combines a global aging prior with a personal photo collection (using as few as 50 images) to learn a personalized age transformation. We introduce a novel Adapter Network that combines personalized aging features with global aging features and generates a re-aged image with StyleGAN2. We also introduce three loss functions to personalize the Adapter Network with personalized aging loss, extrapolation regularization, and adaptive w-norm regularization. Our approach can also be extended to videos, achieving high-quality, identity-preserving, and temporally consistent aging effects that resemble actual appearances at target ages, demonstrating its superiority over state-of-the-art approaches.
GaNI: Global and Near Field Illumination Aware Neural Inverse Rendering
Mar 22, 2024



In this paper, we present GaNI, a Global and Near-field Illumination-aware neural inverse rendering technique that can reconstruct geometry, albedo, and roughness parameters from images of a scene captured with co-located light and camera. Existing inverse rendering techniques with co-located light-camera focus on single objects only, without modeling global illumination and near-field lighting more prominent in scenes with multiple objects. We introduce a system that solves this problem in two stages; we first reconstruct the geometry powered by neural volumetric rendering NeuS, followed by inverse neural radiosity that uses the previously predicted geometry to estimate albedo and roughness. However, such a naive combination fails and we propose multiple technical contributions that enable this two-stage approach. We observe that NeuS fails to handle near-field illumination and strong specular reflections from the flashlight in a scene. We propose to implicitly model the effects of near-field illumination and introduce a surface angle loss function to handle specular reflections. Similarly, we observe that invNeRad assumes constant illumination throughout the capture and cannot handle moving flashlights during capture. We propose a light position-aware radiance cache network and additional smoothness priors on roughness to reconstruct reflectance. Experimental evaluation on synthetic and real data shows that our method outperforms the existing co-located light-camera-based inverse rendering techniques. Our approach produces significantly better reflectance and slightly better geometry than capture strategies that do not require a dark room.
My3DGen: Building Lightweight Personalized 3D Generative Model
Jul 12, 2023
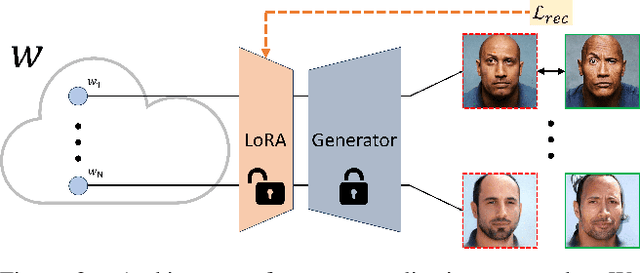

Our paper presents My3DGen, a practical system for creating a personalized and lightweight 3D generative prior using as few as 10 images. My3DGen can reconstruct multi-view consistent images from an input test image, and generate novel appearances by interpolating between any two images of the same individual. While recent studies have demonstrated the effectiveness of personalized generative priors in producing high-quality 2D portrait reconstructions and syntheses, to the best of our knowledge, we are the first to develop a personalized 3D generative prior. Instead of fine-tuning a large pre-trained generative model with millions of parameters to achieve personalization, we propose a parameter-efficient approach. Our method involves utilizing a pre-trained model with fixed weights as a generic prior, while training a separate personalized prior through low-rank decomposition of the weights in each convolution and fully connected layer. However, parameter-efficient few-shot fine-tuning on its own often leads to overfitting. To address this, we introduce a regularization technique based on symmetry of human faces. This regularization enforces that novel view renderings of a training sample, rendered from symmetric poses, exhibit the same identity. By incorporating this symmetry prior, we enhance the quality of reconstruction and synthesis, particularly for non-frontal (profile) faces. Our final system combines low-rank fine-tuning with symmetry regularization and significantly surpasses the performance of pre-trained models, e.g. EG3D. It introduces only approximately 0.6 million additional parameters per identity compared to 31 million for full finetuning of the original model. As a result, our system achieves a 50-fold reduction in model size without sacrificing the quality of the generated 3D faces. Code will be available at our project page: https://luchaoqi.github.io/my3dgen.
Measured Albedo in the Wild: Filling the Gap in Intrinsics Evaluation
Jun 29, 2023



Intrinsic image decomposition and inverse rendering are long-standing problems in computer vision. To evaluate albedo recovery, most algorithms report their quantitative performance with a mean Weighted Human Disagreement Rate (WHDR) metric on the IIW dataset. However, WHDR focuses only on relative albedo values and often fails to capture overall quality of the albedo. In order to comprehensively evaluate albedo, we collect a new dataset, Measured Albedo in the Wild (MAW), and propose three new metrics that complement WHDR: intensity, chromaticity and texture metrics. We show that existing algorithms often improve WHDR metric but perform poorly on other metrics. We then finetune different algorithms on our MAW dataset to significantly improve the quality of the reconstructed albedo both quantitatively and qualitatively. Since the proposed intensity, chromaticity, and texture metrics and the WHDR are all complementary we further introduce a relative performance measure that captures average performance. By analysing existing algorithms we show that there is significant room for improvement. Our dataset and evaluation metrics will enable researchers to develop algorithms that improve albedo reconstruction. Code and Data available at: https://measuredalbedo.github.io/
Shape and Material Capture at Home
Apr 13, 2021

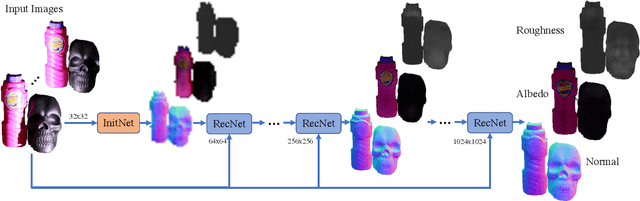

In this paper, we present a technique for estimating the geometry and reflectance of objects using only a camera, flashlight, and optionally a tripod. We propose a simple data capture technique in which the user goes around the object, illuminating it with a flashlight and capturing only a few images. Our main technical contribution is the introduction of a recursive neural architecture, which can predict geometry and reflectance at 2^{k}*2^{k} resolution given an input image at 2^{k}*2^{k} and estimated geometry and reflectance from the previous step at 2^{k-1}*2^{k-1}. This recursive architecture, termed RecNet, is trained with 256x256 resolution but can easily operate on 1024x1024 images during inference. We show that our method produces more accurate surface normal and albedo, especially in regions of specular highlights and cast shadows, compared to previous approaches, given three or fewer input images. For the video and code, please visit the project website http://dlichy.github.io/ShapeAndMaterialAtHome/.
Floor-SP: Inverse CAD for Floorplans by Sequential Room-wise Shortest Path
Aug 19, 2019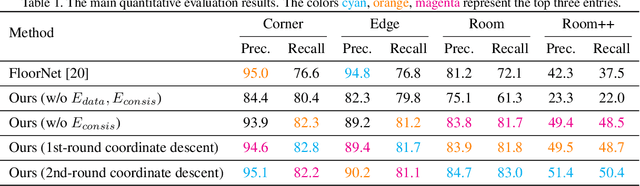
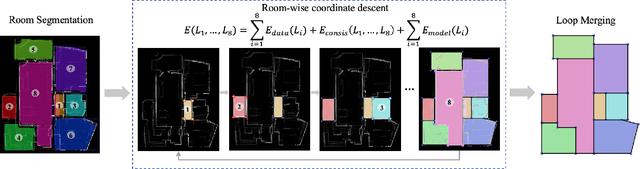
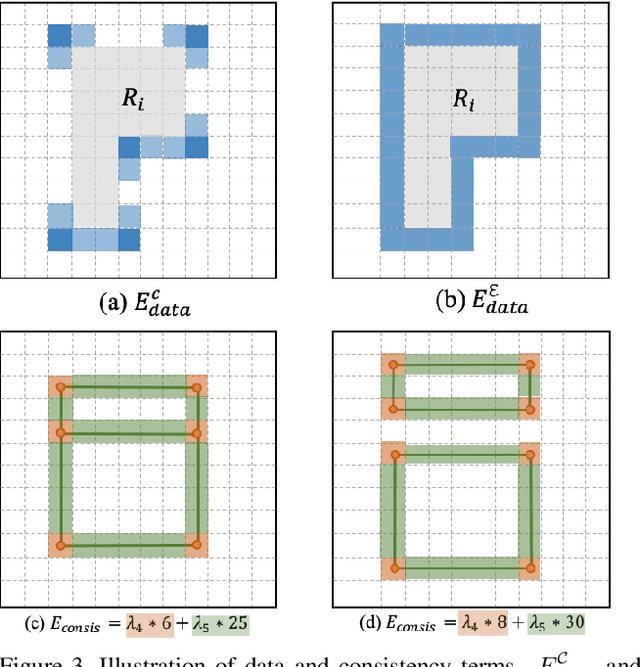
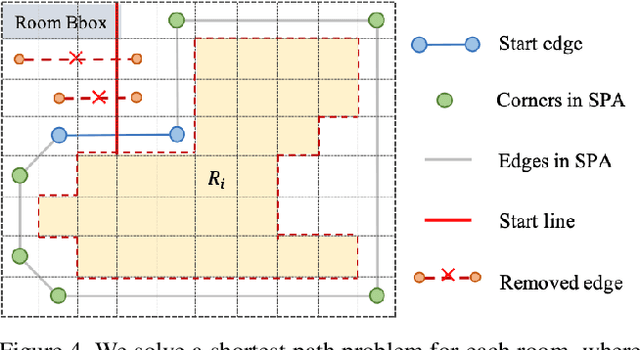
This paper proposes a new approach for automated floorplan reconstruction from RGBD scans, a major milestone in indoor mapping research. The approach, dubbed Floor-SP, formulates a novel optimization problem, where room-wise coordinate descent sequentially solves dynamic programming to optimize the floorplan graph structure. The objective function consists of data terms guided by deep neural networks, consistency terms encouraging adjacent rooms to share corners and walls, and the model complexity term. The approach does not require corner/edge detection with thresholds, unlike most other methods. We have evaluated our system on production-quality RGBD scans of 527 apartments or houses, including many units with non-Manhattan structures. Qualitative and quantitative evaluations demonstrate a significant performance boost over the current state-of-the-art. Please refer to our project website http://jcchen.me/floor-sp/ for code and data.
FloorNet: A Unified Framework for Floorplan Reconstruction from 3D Scans
Mar 31, 2018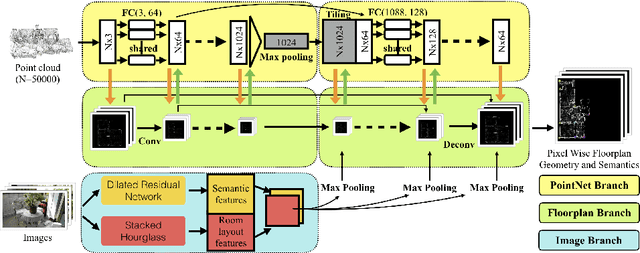

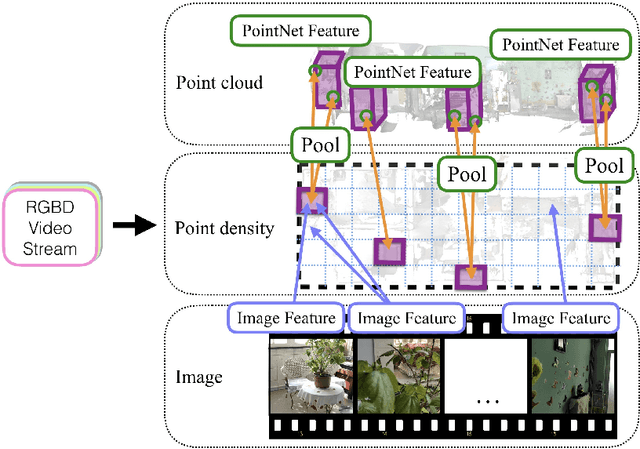
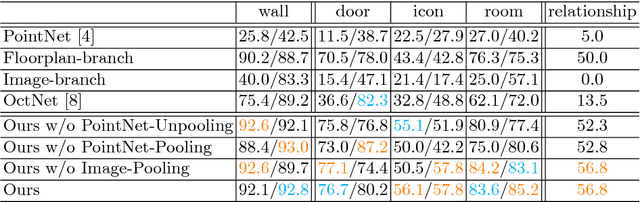
The ultimate goal of this indoor mapping research is to automatically reconstruct a floorplan simply by walking through a house with a smartphone in a pocket. This paper tackles this problem by proposing FloorNet, a novel deep neural architecture. The challenge lies in the processing of RGBD streams spanning a large 3D space. FloorNet effectively processes the data through three neural network branches: 1) PointNet with 3D points, exploiting the 3D information; 2) CNN with a 2D point density image in a top-down view, enhancing the local spatial reasoning; and 3) CNN with RGB images, utilizing the full image information. FloorNet exchanges intermediate features across the branches to exploit the best of all the architectures. We have created a benchmark for floorplan reconstruction by acquiring RGBD video streams for 155 residential houses or apartments with Google Tango phones and annotating complete floorplan information. Our qualitative and quantitative evaluations demonstrate that the fusion of three branches effectively improves the reconstruction quality. We hope that the paper together with the benchmark will be an important step towards solving a challenging vector-graphics reconstruction problem. Code and data are available at https://github.com/art-programmer/FloorNet.