 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyaPlex: Full-Duplex Speech-Motion Model for Dyadic Interaction
Jun 02, 2026We present DyaPlex, a streaming, full-duplex speech-and-motion model designed for dyadic interaction. To capture the continuous and reciprocal nature of human communication, this full-duplex capability empowers the agent to simultaneously perceive and generate both speech and physical motion in a streaming fashion. At its core, our method leverages the strong priors of a foundational full-duplex speech model and integrates a novel motion pathway, thereby achieving fully synchronized multi-modal interaction. Specifically, we design a dual-tower Transformer architecture that preserves the zero-shot conversational reasoning of a frozen base speech model while constructing a deeply coupled, streaming motion pathway. By introducing a unified dyadic token interleaving mechanism and guiding cross-attention via a time-aligned speech-motion RoPE, our model effectively aligns autoregressive motions with rich latent speech features. Trained on the 4,000-hour Seamless Interaction dataset, our model effectively captures cross-speaker dependencies and establishes new state-of-the-art performance across both monadic and dyadic human interaction benchmarks.
VideoFDB: Evaluating Full-Duplex Vision-Speech Capabilities in Conversational Agents
May 28, 2026Natural human conversation is full-duplex and audio-visual: people simultaneously speak and listen while continuously interpreting and producing nonverbal cues, such as nods, smiles, and gestures. To support successful human-agent interaction, agents must model full-duplex audiovisual conversation; however, existing full-duplex benchmarks evaluate only speech. In this work, we present VideoFDB, the first benchmark to evaluate full-duplex audio-visual-to-audio-visual (AV2AV) conversational agents. VideoFDB contributes (i) 237 dyadic clips spanning 11 nonverbal conversational dynamics from real-world video calls, (ii) a taxonomy separating perception from generation behaviors, and (iii) a rubric-based LM-as-judge evaluation framework with interpretable axes for assessing conversational quality with respect to nonverbal conversational dynamics. Across open- and closed-source vision-speech agents, we find systematic failure modes: captioning collapse and visual-stream ignorance, and we show that current systems exploit vision for explicit visual question answering but not for the streaming joint audiovisual grounding required in natural conversation. We further evaluate cascaded speech-to-avatar systems and find that their architecture fundamentally precludes the production of full-duplex nonverbal cues. As the first benchmark for full-duplex AV2AV interaction, VideoFDB establishes a foundation for systematic evaluation and, we hope, will accelerate the advancement and development of next-generation multimodal conversational agents.
GenTorrent: Scaling Large Language Model Serving with An Overley Network
Apr 30, 2025While significant progress has been made in research and development on open-source and cost-efficient large-language models (LLMs), serving scalability remains a critical challenge, particularly for small organizations and individuals seeking to deploy and test their LLM innovations. Inspired by peer-to-peer networks that leverage decentralized overlay nodes to increase throughput and availability, we propose GenTorrent, an LLM serving overlay that harnesses computing resources from decentralized contributors. We identify four key research problems inherent to enabling such a decentralized infrastructure: 1) overlay network organization; 2) LLM communication privacy; 3) overlay forwarding for resource efficiency; and 4) verification of serving quality. This work presents the first systematic study of these fundamental problems in the context of decentralized LLM serving. Evaluation results from a prototype implemented on a set of decentralized nodes demonstrate that GenTorrent achieves a latency reduction of over 50% compared to the baseline design without overlay forwarding. Furthermore, the security features introduce minimal overhead to serving latency and throughput. We believe this work pioneers a new direction for democratizing and scaling future AI serving capabilities.
BLADE: Single-view Body Mesh Learning through Accurate Depth Estimation
Dec 11, 2024



Single-image human mesh recovery is a challenging task due to the ill-posed nature of simultaneous body shape, pose, and camera estimation. Existing estimators work well on images taken from afar, but they break down as the person moves close to the camera. Moreover, current methods fail to achieve both accurate 3D pose and 2D alignment at the same time. Error is mainly introduced by inaccurate perspective projection heuristically derived from orthographic parameters. To resolve this long-standing challenge, we present our method BLADE which accurately recovers perspective parameters from a single image without heuristic assumptions. We start from the inverse relationship between perspective distortion and the person's Z-translation Tz, and we show that Tz can be reliably estimated from the image. We then discuss the important role of Tz for accurate human mesh recovery estimated from close-range images. Finally, we show that, once Tz and the 3D human mesh are estimated, one can accurately recover the focal length and full 3D translation. Extensive experiments on standard benchmarks and real-world close-range images show that our method is the first to accurately recover projection parameters from a single image, and consequently attain state-of-the-art accuracy on 3D pose estimation and 2D alignment for a wide range of images. https://research.nvidia.com/labs/amri/projects/blade/
Coherent3D: Coherent 3D Portrait Video Reconstruction via Triplane Fusion
Dec 11, 2024


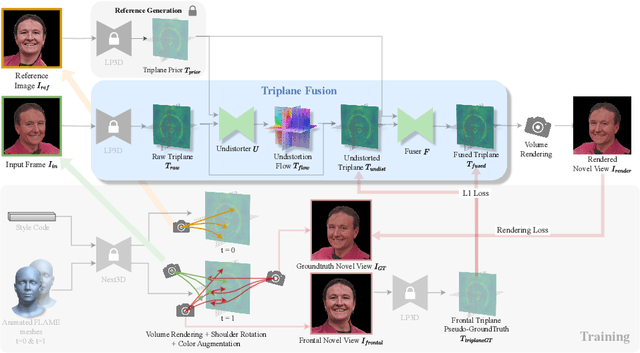
Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user's appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a 3D avatar built from a single reference image, but fail to faithfully preserve the user's per-frame appearance (e.g., instantaneous facial expression and lighting). As a result, none of these two frameworks is an ideal solution for democratized 3D telepresence. In this work, we address this dilemma and propose a novel solution that maintains both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that takes the best of both worlds by fusing a canonical 3D prior from a reference view with dynamic appearance from per-frame input views, producing temporally stable 3D videos with faithful reconstruction of the user's per-frame appearance. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction and temporal consistency on in-studio and in-the-wild datasets. https://research.nvidia.com/labs/amri/projects/coherent3d
Coherent 3D Portrait Video Reconstruction via Triplane Fusion
May 01, 2024Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, potentially democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user's appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a personalized 3D prior, but fail to faithfully reconstruct the user's per-frame appearance (e.g., facial expressions and lighting). In this work, we recognize the need to maintain both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that fuses a personalized 3D subject prior with per-frame information, producing temporally stable 3D videos with faithful reconstruction of the user's per-frame appearances. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction accuracy and temporal consistency on in-studio and in-the-wild datasets.
My3DGen: Building Lightweight Personalized 3D Generative Model
Jul 12, 2023
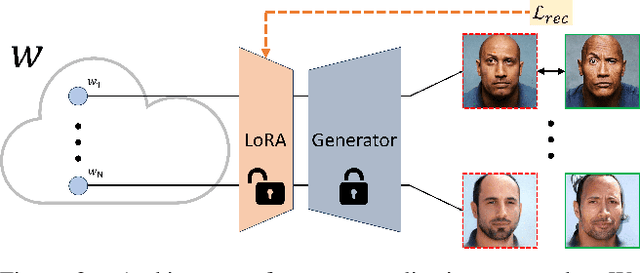
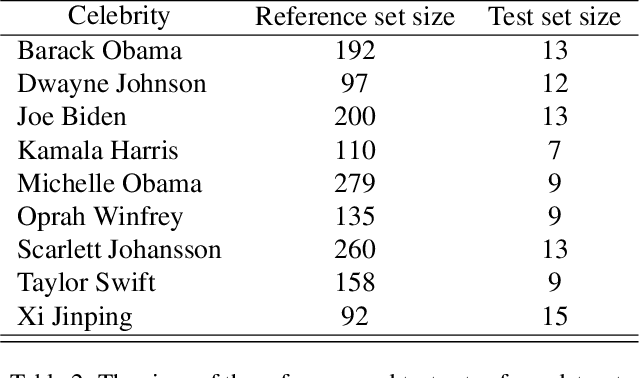

Our paper presents My3DGen, a practical system for creating a personalized and lightweight 3D generative prior using as few as 10 images. My3DGen can reconstruct multi-view consistent images from an input test image, and generate novel appearances by interpolating between any two images of the same individual. While recent studies have demonstrated the effectiveness of personalized generative priors in producing high-quality 2D portrait reconstructions and syntheses, to the best of our knowledge, we are the first to develop a personalized 3D generative prior. Instead of fine-tuning a large pre-trained generative model with millions of parameters to achieve personalization, we propose a parameter-efficient approach. Our method involves utilizing a pre-trained model with fixed weights as a generic prior, while training a separate personalized prior through low-rank decomposition of the weights in each convolution and fully connected layer. However, parameter-efficient few-shot fine-tuning on its own often leads to overfitting. To address this, we introduce a regularization technique based on symmetry of human faces. This regularization enforces that novel view renderings of a training sample, rendered from symmetric poses, exhibit the same identity. By incorporating this symmetry prior, we enhance the quality of reconstruction and synthesis, particularly for non-frontal (profile) faces. Our final system combines low-rank fine-tuning with symmetry regularization and significantly surpasses the performance of pre-trained models, e.g. EG3D. It introduces only approximately 0.6 million additional parameters per identity compared to 31 million for full finetuning of the original model. As a result, our system achieves a 50-fold reduction in model size without sacrificing the quality of the generated 3D faces. Code will be available at our project page: https://luchaoqi.github.io/my3dgen.
Bringing Telepresence to Every Desk
Apr 03, 2023



In this paper, we work to bring telepresence to every desktop. Unlike commercial systems, personal 3D video conferencing systems must render high-quality videos while remaining financially and computationally viable for the average consumer. To this end, we introduce a capturing and rendering system that only requires 4 consumer-grade RGBD cameras and synthesizes high-quality free-viewpoint videos of users as well as their environments. Experimental results show that our system renders high-quality free-viewpoint videos without using object templates or heavy pre-processing. While not real-time, our system is fast and does not require per-video optimizations. Moreover, our system is robust to complex hand gestures and clothing, and it can generalize to new users. This work provides a strong basis for further optimization, and it will help bring telepresence to every desk in the near future. The code and dataset will be made available on our website https://mcmvmc.github.io/PersonalTelepresence/.
INV: Towards Streaming Incremental Neural Videos
Feb 03, 2023Recent works in spatiotemporal radiance fields can produce photorealistic free-viewpoint videos. However, they are inherently unsuitable for interactive streaming scenarios (e.g. video conferencing, telepresence) because have an inevitable lag even if the training is instantaneous. This is because these approaches consume videos and thus have to buffer chunks of frames (often seconds) before processing. In this work, we take a step towards interactive streaming via a frame-by-frame approach naturally free of lag. Conventional wisdom believes that per-frame NeRFs are impractical due to prohibitive training costs and storage. We break this belief by introducing Incremental Neural Videos (INV), a per-frame NeRF that is efficiently trained and streamable. We designed INV based on two insights: (1) Our main finding is that MLPs naturally partition themselves into Structure and Color Layers, which store structural and color/texture information respectively. (2) We leverage this property to retain and improve upon knowledge from previous frames, thus amortizing training across frames and reducing redundant learning. As a result, with negligible changes to NeRF, INV can achieve good qualities (>28.6db) in 8min/frame. It can also outperform prior SOTA in 19% less training time. Additionally, our Temporal Weight Compression reduces the per-frame size to 0.3MB/frame (6.6% of NeRF). More importantly, INV is free from buffer lag and is naturally fit for streaming. While this work does not achieve real-time training, it shows that incremental approaches like INV present new possibilities in interactive 3D streaming. Moreover, our discovery of natural information partition leads to a better understanding and manipulation of MLPs. Code and dataset will be released soon.
Learning Dynamic View Synthesis With Few RGBD Cameras
Apr 22, 2022
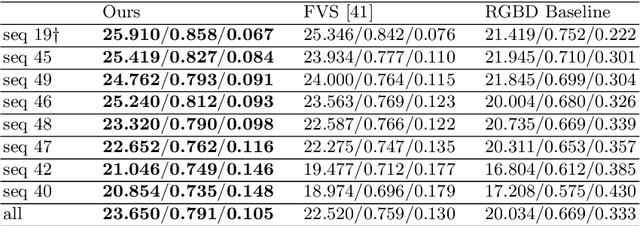
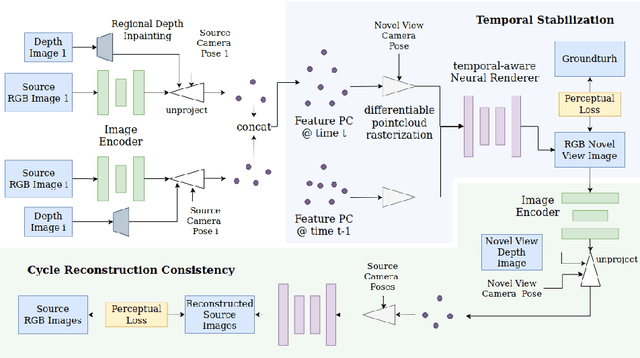

There have been significant advancements in dynamic novel view synthesis in recent years. However, current deep learning models often require (1) prior models (e.g., SMPL human models), (2) heavy pre-processing, or (3) per-scene optimization. We propose to utilize RGBD cameras to remove these limitations and synthesize free-viewpoint videos of dynamic indoor scenes. We generate feature point clouds from RGBD frames and then render them into free-viewpoint videos via a neural renderer. However, the inaccurate, unstable, and incomplete depth measurements induce severe distortions, flickering, and ghosting artifacts. We enforce spatial-temporal consistency via the proposed Cycle Reconstruction Consistency and Temporal Stabilization module to reduce these artifacts. We introduce a simple Regional Depth-Inpainting module that adaptively inpaints missing depth values to render complete novel views. Additionally, we present a Human-Things Interactions dataset to validate our approach and facilitate future research. The dataset consists of 43 multi-view RGBD video sequences of everyday activities, capturing complex interactions between human subjects and their surroundings. Experiments on the HTI dataset show that our method outperforms the baseline per-frame image fidelity and spatial-temporal consistency. We will release our code, and the dataset on the website soon.