 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoherent3D: Coherent 3D Portrait Video Reconstruction via Triplane Fusion
Dec 11, 2024


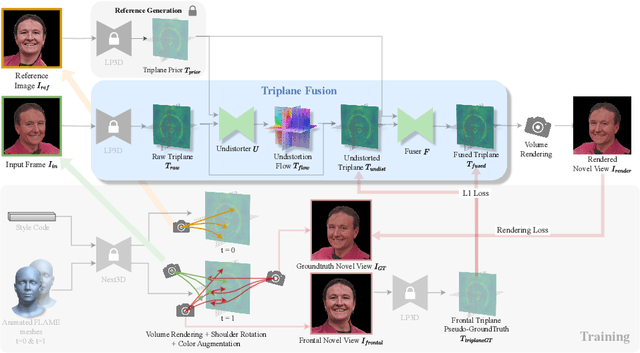
Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user's appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a 3D avatar built from a single reference image, but fail to faithfully preserve the user's per-frame appearance (e.g., instantaneous facial expression and lighting). As a result, none of these two frameworks is an ideal solution for democratized 3D telepresence. In this work, we address this dilemma and propose a novel solution that maintains both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that takes the best of both worlds by fusing a canonical 3D prior from a reference view with dynamic appearance from per-frame input views, producing temporally stable 3D videos with faithful reconstruction of the user's per-frame appearance. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction and temporal consistency on in-studio and in-the-wild datasets. https://research.nvidia.com/labs/amri/projects/coherent3d
Coherent 3D Portrait Video Reconstruction via Triplane Fusion
May 01, 2024Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, potentially democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user's appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a personalized 3D prior, but fail to faithfully reconstruct the user's per-frame appearance (e.g., facial expressions and lighting). In this work, we recognize the need to maintain both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that fuses a personalized 3D subject prior with per-frame information, producing temporally stable 3D videos with faithful reconstruction of the user's per-frame appearances. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction accuracy and temporal consistency on in-studio and in-the-wild datasets.
What You See is What You GAN: Rendering Every Pixel for High-Fidelity Geometry in 3D GANs
Jan 04, 2024



3D-aware Generative Adversarial Networks (GANs) have shown remarkable progress in learning to generate multi-view-consistent images and 3D geometries of scenes from collections of 2D images via neural volume rendering. Yet, the significant memory and computational costs of dense sampling in volume rendering have forced 3D GANs to adopt patch-based training or employ low-resolution rendering with post-processing 2D super resolution, which sacrifices multiview consistency and the quality of resolved geometry. Consequently, 3D GANs have not yet been able to fully resolve the rich 3D geometry present in 2D images. In this work, we propose techniques to scale neural volume rendering to the much higher resolution of native 2D images, thereby resolving fine-grained 3D geometry with unprecedented detail. Our approach employs learning-based samplers for accelerating neural rendering for 3D GAN training using up to 5 times fewer depth samples. This enables us to explicitly "render every pixel" of the full-resolution image during training and inference without post-processing superresolution in 2D. Together with our strategy to learn high-quality surface geometry, our method synthesizes high-resolution 3D geometry and strictly view-consistent images while maintaining image quality on par with baselines relying on post-processing super resolution. We demonstrate state-of-the-art 3D gemetric quality on FFHQ and AFHQ, setting a new standard for unsupervised learning of 3D shapes in 3D GANs.
Snapshot High Dynamic Range Imaging with a Polarization Camera
Aug 16, 2023High dynamic range (HDR) images are important for a range of tasks, from navigation to consumer photography. Accordingly, a host of specialized HDR sensors have been developed, the most successful of which are based on capturing variable per-pixel exposures. In essence, these methods capture an entire exposure bracket sequence at once in a single shot. This paper presents a straightforward but highly effective approach for turning an off-the-shelf polarization camera into a high-performance HDR camera. By placing a linear polarizer in front of the polarization camera, we are able to simultaneously capture four images with varied exposures, which are determined by the orientation of the polarizer. We develop an outlier-robust and self-calibrating algorithm to reconstruct an HDR image (at a single polarity) from these measurements. Finally, we demonstrate the efficacy of our approach with extensive real-world experiments.
Why Don't You Clean Your Glasses? Perception Attacks with Dynamic Optical Perturbations
Jul 27, 2023



Camera-based autonomous systems that emulate human perception are increasingly being integrated into safety-critical platforms. Consequently, an established body of literature has emerged that explores adversarial attacks targeting the underlying machine learning models. Adapting adversarial attacks to the physical world is desirable for the attacker, as this removes the need to compromise digital systems. However, the real world poses challenges related to the "survivability" of adversarial manipulations given environmental noise in perception pipelines and the dynamicity of autonomous systems. In this paper, we take a sensor-first approach. We present EvilEye, a man-in-the-middle perception attack that leverages transparent displays to generate dynamic physical adversarial examples. EvilEye exploits the camera's optics to induce misclassifications under a variety of illumination conditions. To generate dynamic perturbations, we formalize the projection of a digital attack into the physical domain by modeling the transformation function of the captured image through the optical pipeline. Our extensive experiments show that EvilEye's generated adversarial perturbations are much more robust across varying environmental light conditions relative to existing physical perturbation frameworks, achieving a high attack success rate (ASR) while bypassing state-of-the-art physical adversarial detection frameworks. We demonstrate that the dynamic nature of EvilEye enables attackers to adapt adversarial examples across a variety of objects with a significantly higher ASR compared to state-of-the-art physical world attack frameworks. Finally, we discuss mitigation strategies against the EvilEye attack.
Real-Time Radiance Fields for Single-Image Portrait View Synthesis
May 03, 2023



We present a one-shot method to infer and render a photorealistic 3D representation from a single unposed image (e.g., face portrait) in real-time. Given a single RGB input, our image encoder directly predicts a canonical triplane representation of a neural radiance field for 3D-aware novel view synthesis via volume rendering. Our method is fast (24 fps) on consumer hardware, and produces higher quality results than strong GAN-inversion baselines that require test-time optimization. To train our triplane encoder pipeline, we use only synthetic data, showing how to distill the knowledge from a pretrained 3D GAN into a feedforward encoder. Technical contributions include a Vision Transformer-based triplane encoder, a camera data augmentation strategy, and a well-designed loss function for synthetic data training. We benchmark against the state-of-the-art methods, demonstrating significant improvements in robustness and image quality in challenging real-world settings. We showcase our results on portraits of faces (FFHQ) and cats (AFHQ), but our algorithm can also be applied in the future to other categories with a 3D-aware image generator.