 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Inverse Problems in Protein Space Using Diffusion-Based Priors
Jun 06, 2024The interaction of a protein with its environment can be understood and controlled via its 3D structure. Experimental methods for protein structure determination, such as X-ray crystallography or cryogenic electron microscopy, shed light on biological processes but introduce challenging inverse problems. Learning-based approaches have emerged as accurate and efficient methods to solve these inverse problems for 3D structure determination, but are specialized for a predefined type of measurement. Here, we introduce a versatile framework to turn raw biophysical measurements of varying types into 3D atomic models. Our method combines a physics-based forward model of the measurement process with a pretrained generative model providing a task-agnostic, data-driven prior. Our method outperforms posterior sampling baselines on both linear and non-linear inverse problems. In particular, it is the first diffusion-based method for refining atomic models from cryo-EM density maps.
Single-Shot Implicit Morphable Faces with Consistent Texture Parameterization
May 04, 2023There is a growing demand for the accessible creation of high-quality 3D avatars that are animatable and customizable. Although 3D morphable models provide intuitive control for editing and animation, and robustness for single-view face reconstruction, they cannot easily capture geometric and appearance details. Methods based on neural implicit representations, such as signed distance functions (SDF) or neural radiance fields, approach photo-realism, but are difficult to animate and do not generalize well to unseen data. To tackle this problem, we propose a novel method for constructing implicit 3D morphable face models that are both generalizable and intuitive for editing. Trained from a collection of high-quality 3D scans, our face model is parameterized by geometry, expression, and texture latent codes with a learned SDF and explicit UV texture parameterization. Once trained, we can reconstruct an avatar from a single in-the-wild image by leveraging the learned prior to project the image into the latent space of our model. Our implicit morphable face models can be used to render an avatar from novel views, animate facial expressions by modifying expression codes, and edit textures by directly painting on the learned UV-texture maps. We demonstrate quantitatively and qualitatively that our method improves upon photo-realism, geometry, and expression accuracy compared to state-of-the-art methods.
Real-Time Radiance Fields for Single-Image Portrait View Synthesis
May 03, 2023



We present a one-shot method to infer and render a photorealistic 3D representation from a single unposed image (e.g., face portrait) in real-time. Given a single RGB input, our image encoder directly predicts a canonical triplane representation of a neural radiance field for 3D-aware novel view synthesis via volume rendering. Our method is fast (24 fps) on consumer hardware, and produces higher quality results than strong GAN-inversion baselines that require test-time optimization. To train our triplane encoder pipeline, we use only synthetic data, showing how to distill the knowledge from a pretrained 3D GAN into a feedforward encoder. Technical contributions include a Vision Transformer-based triplane encoder, a camera data augmentation strategy, and a well-designed loss function for synthetic data training. We benchmark against the state-of-the-art methods, demonstrating significant improvements in robustness and image quality in challenging real-world settings. We showcase our results on portraits of faces (FFHQ) and cats (AFHQ), but our algorithm can also be applied in the future to other categories with a 3D-aware image generator.
Generative Novel View Synthesis with 3D-Aware Diffusion Models
Apr 05, 2023We present a diffusion-based model for 3D-aware generative novel view synthesis from as few as a single input image. Our model samples from the distribution of possible renderings consistent with the input and, even in the presence of ambiguity, is capable of rendering diverse and plausible novel views. To achieve this, our method makes use of existing 2D diffusion backbones but, crucially, incorporates geometry priors in the form of a 3D feature volume. This latent feature field captures the distribution over possible scene representations and improves our method's ability to generate view-consistent novel renderings. In addition to generating novel views, our method has the ability to autoregressively synthesize 3D-consistent sequences. We demonstrate state-of-the-art results on synthetic renderings and room-scale scenes; we also show compelling results for challenging, real-world objects.
Diffusion in the Dark: A Diffusion Model for Low-Light Text Recognition
Mar 07, 2023



Images are indispensable for the automation of high-level tasks, such as text recognition. Low-light conditions pose a challenge for these high-level perception stacks, which are often optimized on well-lit, artifact-free images. Reconstruction methods for low-light images can produce well-lit counterparts, but typically at the cost of high-frequency details critical for downstream tasks. We propose Diffusion in the Dark (DiD), a diffusion model for low-light image reconstruction that provides qualitatively competitive reconstructions with that of SOTA, while preserving high-frequency details even in extremely noisy, dark conditions. We demonstrate that DiD, without any task-specific optimization, can outperform SOTA low-light methods in low-light text recognition on real images, bolstering the potential of diffusion models for ill-posed inverse problems.
Generative Neural Articulated Radiance Fields
Jun 28, 2022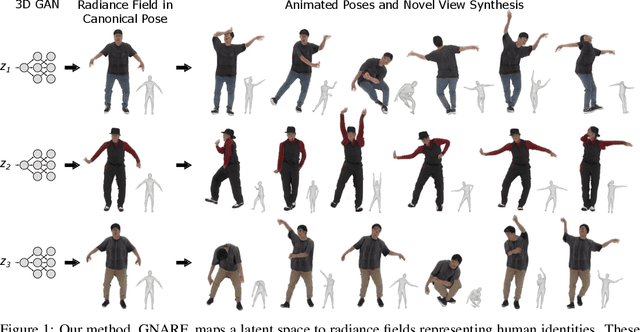
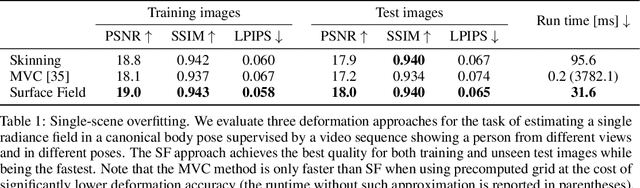
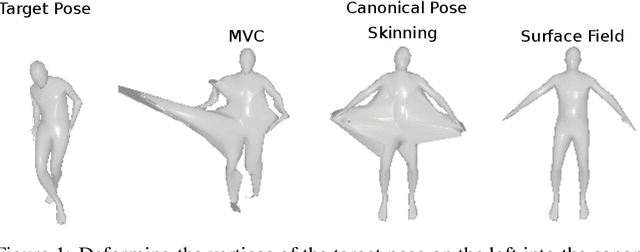
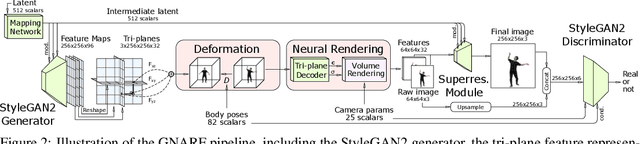
Unsupervised learning of 3D-aware generative adversarial networks (GANs) using only collections of single-view 2D photographs has very recently made much progress. These 3D GANs, however, have not been demonstrated for human bodies and the generated radiance fields of existing frameworks are not directly editable, limiting their applicability in downstream tasks. We propose a solution to these challenges by developing a 3D GAN framework that learns to generate radiance fields of human bodies or faces in a canonical pose and warp them using an explicit deformation field into a desired body pose or facial expression. Using our framework, we demonstrate the first high-quality radiance field generation results for human bodies. Moreover, we show that our deformation-aware training procedure significantly improves the quality of generated bodies or faces when editing their poses or facial expressions compared to a 3D GAN that is not trained with explicit deformations.
3D GAN Inversion for Controllable Portrait Image Animation
Mar 25, 2022
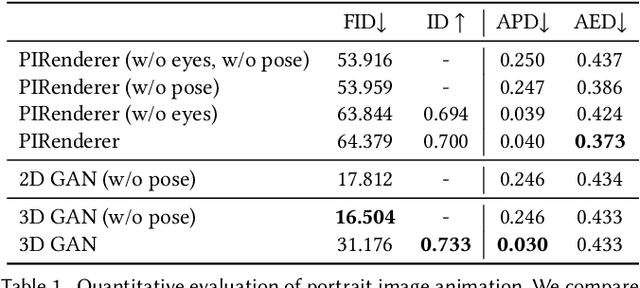


Millions of images of human faces are captured every single day; but these photographs portray the likeness of an individual with a fixed pose, expression, and appearance. Portrait image animation enables the post-capture adjustment of these attributes from a single image while maintaining a photorealistic reconstruction of the subject's likeness or identity. Still, current methods for portrait image animation are typically based on 2D warping operations or manipulations of a 2D generative adversarial network (GAN) and lack explicit mechanisms to enforce multi-view consistency. Thus these methods may significantly alter the identity of the subject, especially when the viewpoint relative to the camera is changed. In this work, we leverage newly developed 3D GANs, which allow explicit control over the pose of the image subject with multi-view consistency. We propose a supervision strategy to flexibly manipulate expressions with 3D morphable models, and we show that the proposed method also supports editing appearance attributes, such as age or hairstyle, by interpolating within the latent space of the GAN. The proposed technique for portrait image animation outperforms previous methods in terms of image quality, identity preservation, and pose transfer while also supporting attribute editing.
Efficient Geometry-aware 3D Generative Adversarial Networks
Dec 15, 2021
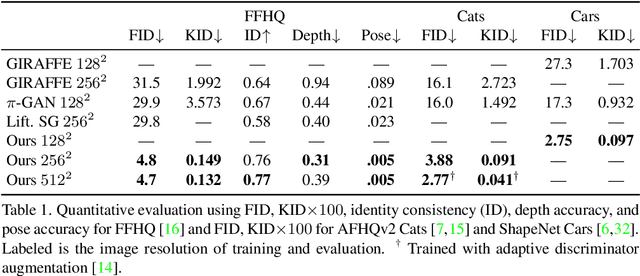
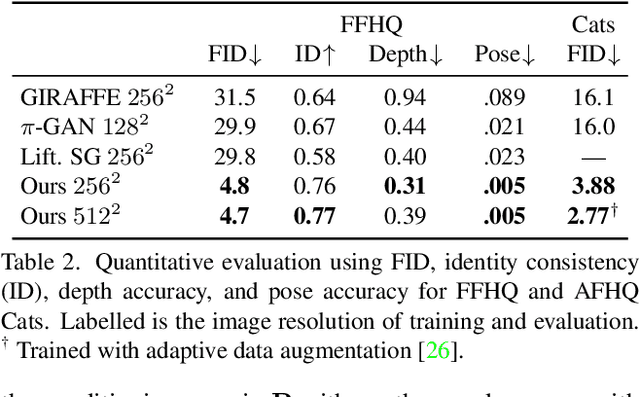
Unsupervised generation of high-quality multi-view-consistent images and 3D shapes using only collections of single-view 2D photographs has been a long-standing challenge. Existing 3D GANs are either compute-intensive or make approximations that are not 3D-consistent; the former limits quality and resolution of the generated images and the latter adversely affects multi-view consistency and shape quality. In this work, we improve the computational efficiency and image quality of 3D GANs without overly relying on these approximations. For this purpose, we introduce an expressive hybrid explicit-implicit network architecture that, together with other design choices, synthesizes not only high-resolution multi-view-consistent images in real time but also produces high-quality 3D geometry. By decoupling feature generation and neural rendering, our framework is able to leverage state-of-the-art 2D CNN generators, such as StyleGAN2, and inherit their efficiency and expressiveness. We demonstrate state-of-the-art 3D-aware synthesis with FFHQ and AFHQ Cats, among other experiments.
ACORN: Adaptive Coordinate Networks for Neural Scene Representation
May 06, 2021
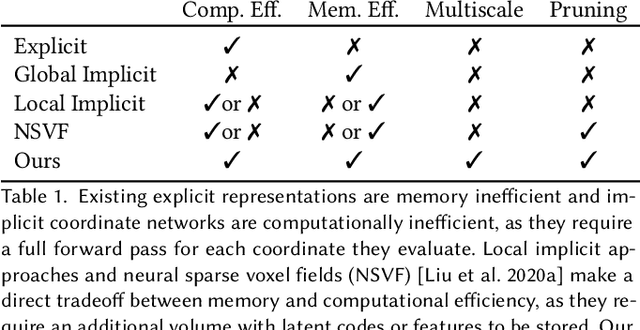
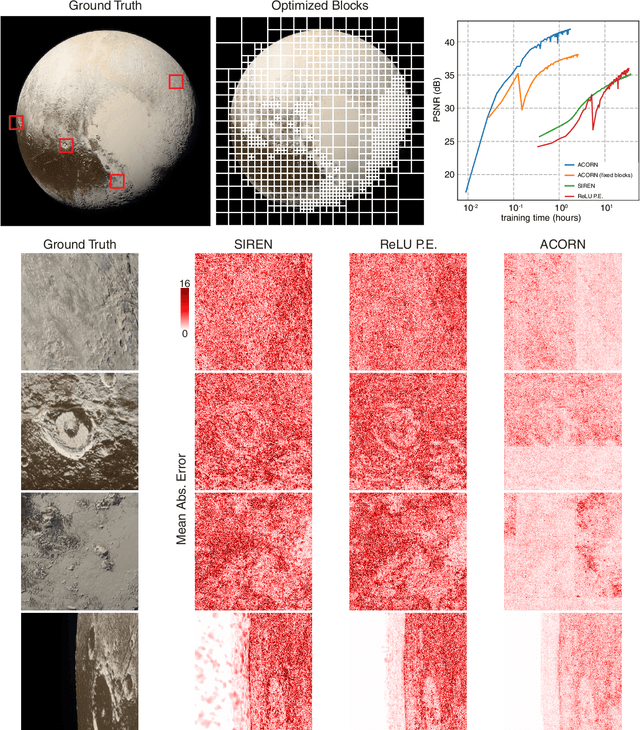
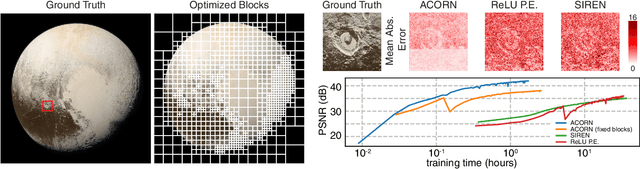
Neural representations have emerged as a new paradigm for applications in rendering, imaging, geometric modeling, and simulation. Compared to traditional representations such as meshes, point clouds, or volumes they can be flexibly incorporated into differentiable learning-based pipelines. While recent improvements to neural representations now make it possible to represent signals with fine details at moderate resolutions (e.g., for images and 3D shapes), adequately representing large-scale or complex scenes has proven a challenge. Current neural representations fail to accurately represent images at resolutions greater than a megapixel or 3D scenes with more than a few hundred thousand polygons. Here, we introduce a new hybrid implicit-explicit network architecture and training strategy that adaptively allocates resources during training and inference based on the local complexity of a signal of interest. Our approach uses a multiscale block-coordinate decomposition, similar to a quadtree or octree, that is optimized during training. The network architecture operates in two stages: using the bulk of the network parameters, a coordinate encoder generates a feature grid in a single forward pass. Then, hundreds or thousands of samples within each block can be efficiently evaluated using a lightweight feature decoder. With this hybrid implicit-explicit network architecture, we demonstrate the first experiments that fit gigapixel images to nearly 40 dB peak signal-to-noise ratio. Notably this represents an increase in scale of over 1000x compared to the resolution of previously demonstrated image-fitting experiments. Moreover, our approach is able to represent 3D shapes significantly faster and better than previous techniques; it reduces training times from days to hours or minutes and memory requirements by over an order of magnitude.
pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis
Dec 02, 2020

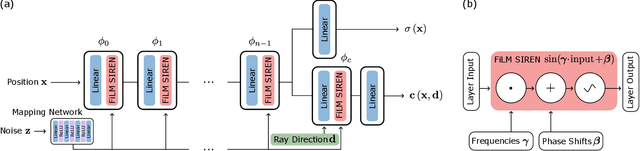

We have witnessed rapid progress on 3D-aware image synthesis, leveraging recent advances in generative visual models and neural rendering. Existing approaches however fall short in two ways: first, they may lack an underlying 3D representation or rely on view-inconsistent rendering, hence synthesizing images that are not multi-view consistent; second, they often depend upon representation network architectures that are not expressive enough, and their results thus lack in image quality. We propose a novel generative model, named Periodic Implicit Generative Adversarial Networks ($\pi$-GAN or pi-GAN), for high-quality 3D-aware image synthesis. $\pi$-GAN leverages neural representations with periodic activation functions and volumetric rendering to represent scenes as view-consistent 3D representations with fine detail. The proposed approach obtains state-of-the-art results for 3D-aware image synthesis with multiple real and synthetic datasets.