 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Shot Implicit Morphable Faces with Consistent Texture Parameterization
May 04, 2023There is a growing demand for the accessible creation of high-quality 3D avatars that are animatable and customizable. Although 3D morphable models provide intuitive control for editing and animation, and robustness for single-view face reconstruction, they cannot easily capture geometric and appearance details. Methods based on neural implicit representations, such as signed distance functions (SDF) or neural radiance fields, approach photo-realism, but are difficult to animate and do not generalize well to unseen data. To tackle this problem, we propose a novel method for constructing implicit 3D morphable face models that are both generalizable and intuitive for editing. Trained from a collection of high-quality 3D scans, our face model is parameterized by geometry, expression, and texture latent codes with a learned SDF and explicit UV texture parameterization. Once trained, we can reconstruct an avatar from a single in-the-wild image by leveraging the learned prior to project the image into the latent space of our model. Our implicit morphable face models can be used to render an avatar from novel views, animate facial expressions by modifying expression codes, and edit textures by directly painting on the learned UV-texture maps. We demonstrate quantitatively and qualitatively that our method improves upon photo-realism, geometry, and expression accuracy compared to state-of-the-art methods.
Real-Time Radiance Fields for Single-Image Portrait View Synthesis
May 03, 2023



We present a one-shot method to infer and render a photorealistic 3D representation from a single unposed image (e.g., face portrait) in real-time. Given a single RGB input, our image encoder directly predicts a canonical triplane representation of a neural radiance field for 3D-aware novel view synthesis via volume rendering. Our method is fast (24 fps) on consumer hardware, and produces higher quality results than strong GAN-inversion baselines that require test-time optimization. To train our triplane encoder pipeline, we use only synthetic data, showing how to distill the knowledge from a pretrained 3D GAN into a feedforward encoder. Technical contributions include a Vision Transformer-based triplane encoder, a camera data augmentation strategy, and a well-designed loss function for synthetic data training. We benchmark against the state-of-the-art methods, demonstrating significant improvements in robustness and image quality in challenging real-world settings. We showcase our results on portraits of faces (FFHQ) and cats (AFHQ), but our algorithm can also be applied in the future to other categories with a 3D-aware image generator.
RANA: Relightable Articulated Neural Avatars
Dec 06, 2022



We propose RANA, a relightable and articulated neural avatar for the photorealistic synthesis of humans under arbitrary viewpoints, body poses, and lighting. We only require a short video clip of the person to create the avatar and assume no knowledge about the lighting environment. We present a novel framework to model humans while disentangling their geometry, texture, and also lighting environment from monocular RGB videos. To simplify this otherwise ill-posed task we first estimate the coarse geometry and texture of the person via SMPL+D model fitting and then learn an articulated neural representation for photorealistic image generation. RANA first generates the normal and albedo maps of the person in any given target body pose and then uses spherical harmonics lighting to generate the shaded image in the target lighting environment. We also propose to pretrain RANA using synthetic images and demonstrate that it leads to better disentanglement between geometry and texture while also improving robustness to novel body poses. Finally, we also present a new photorealistic synthetic dataset, Relighting Humans, to quantitatively evaluate the performance of the proposed approach.
Learning to Relight Portrait Images via a Virtual Light Stage and Synthetic-to-Real Adaptation
Sep 21, 2022



Given a portrait image of a person and an environment map of the target lighting, portrait relighting aims to re-illuminate the person in the image as if the person appeared in an environment with the target lighting. To achieve high-quality results, recent methods rely on deep learning. An effective approach is to supervise the training of deep neural networks with a high-fidelity dataset of desired input-output pairs, captured with a light stage. However, acquiring such data requires an expensive special capture rig and time-consuming efforts, limiting access to only a few resourceful laboratories. To address the limitation, we propose a new approach that can perform on par with the state-of-the-art (SOTA) relighting methods without requiring a light stage. Our approach is based on the realization that a successful relighting of a portrait image depends on two conditions. First, the method needs to mimic the behaviors of physically-based relighting. Second, the output has to be photorealistic. To meet the first condition, we propose to train the relighting network with training data generated by a virtual light stage that performs physically-based rendering on various 3D synthetic humans under different environment maps. To meet the second condition, we develop a novel synthetic-to-real approach to bring photorealism to the relighting network output. In addition to achieving SOTA results, our approach offers several advantages over the prior methods, including controllable glares on glasses and more temporally-consistent results for relighting videos.
* To appear in ACM Transactions on Graphics (SIGGRAPH Asia 2022). 21 pages, 25 figures, 7 tables. Project page: https://deepimagination.cc/Lumos/
RTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis
May 14, 2022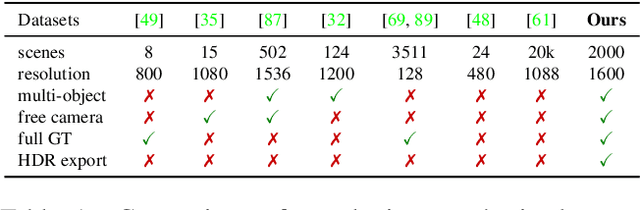


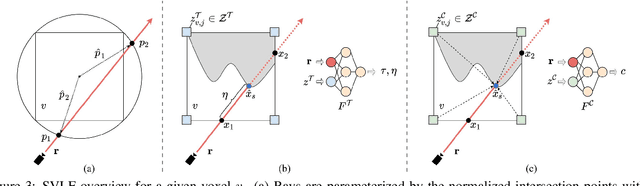
We present a large-scale synthetic dataset for novel view synthesis consisting of ~300k images rendered from nearly 2000 complex scenes using high-quality ray tracing at high resolution (1600 x 1600 pixels). The dataset is orders of magnitude larger than existing synthetic datasets for novel view synthesis, thus providing a large unified benchmark for both training and evaluation. Using 4 distinct sources of high-quality 3D meshes, the scenes of our dataset exhibit challenging variations in camera views, lighting, shape, materials, and textures. Because our dataset is too large for existing methods to process, we propose Sparse Voxel Light Field (SVLF), an efficient voxel-based light field approach for novel view synthesis that achieves comparable performance to NeRF on synthetic data, while being an order of magnitude faster to train and two orders of magnitude faster to render. SVLF achieves this speed by relying on a sparse voxel octree, careful voxel sampling (requiring only a handful of queries per ray), and reduced network structure; as well as ground truth depth maps at training time. Our dataset is generated by NViSII, a Python-based ray tracing renderer, which is designed to be simple for non-experts to use and share, flexible and powerful through its use of scripting, and able to create high-quality and physically-based rendered images. Experiments with a subset of our dataset allow us to compare standard methods like NeRF and mip-NeRF for single-scene modeling, and pixelNeRF for category-level modeling, pointing toward the need for future improvements in this area.
DRaCoN -- Differentiable Rasterization Conditioned Neural Radiance Fields for Articulated Avatars
Mar 29, 2022



Acquisition and creation of digital human avatars is an important problem with applications to virtual telepresence, gaming, and human modeling. Most contemporary approaches for avatar generation can be viewed either as 3D-based methods, which use multi-view data to learn a 3D representation with appearance (such as a mesh, implicit surface, or volume), or 2D-based methods which learn photo-realistic renderings of avatars but lack accurate 3D representations. In this work, we present, DRaCoN, a framework for learning full-body volumetric avatars which exploits the advantages of both the 2D and 3D neural rendering techniques. It consists of a Differentiable Rasterization module, DiffRas, that synthesizes a low-resolution version of the target image along with additional latent features guided by a parametric body model. The output of DiffRas is then used as conditioning to our conditional neural 3D representation module (c-NeRF) which generates the final high-res image along with body geometry using volumetric rendering. While DiffRas helps in obtaining photo-realistic image quality, c-NeRF, which employs signed distance fields (SDF) for 3D representations, helps to obtain fine 3D geometric details. Experiments on the challenging ZJU-MoCap and Human3.6M datasets indicate that DRaCoN outperforms state-of-the-art methods both in terms of error metrics and visual quality.
Efficient Geometry-aware 3D Generative Adversarial Networks
Dec 15, 2021
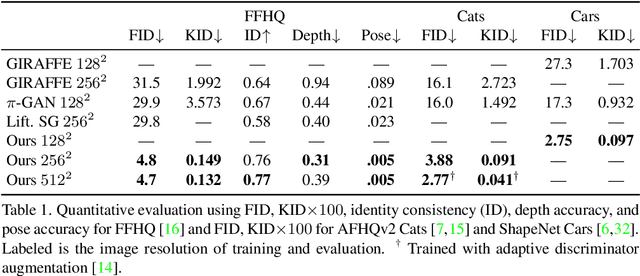
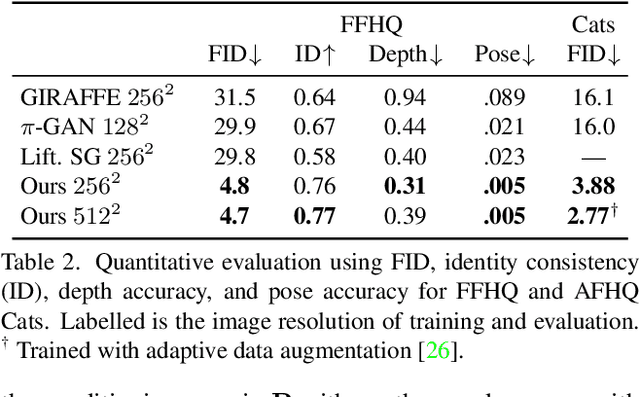
Unsupervised generation of high-quality multi-view-consistent images and 3D shapes using only collections of single-view 2D photographs has been a long-standing challenge. Existing 3D GANs are either compute-intensive or make approximations that are not 3D-consistent; the former limits quality and resolution of the generated images and the latter adversely affects multi-view consistency and shape quality. In this work, we improve the computational efficiency and image quality of 3D GANs without overly relying on these approximations. For this purpose, we introduce an expressive hybrid explicit-implicit network architecture that, together with other design choices, synthesizes not only high-resolution multi-view-consistent images in real time but also produces high-quality 3D geometry. By decoupling feature generation and neural rendering, our framework is able to leverage state-of-the-art 2D CNN generators, such as StyleGAN2, and inherit their efficiency and expressiveness. We demonstrate state-of-the-art 3D-aware synthesis with FFHQ and AFHQ Cats, among other experiments.
Frame Averaging for Equivariant Shape Space Learning
Dec 03, 2021
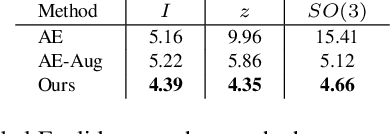

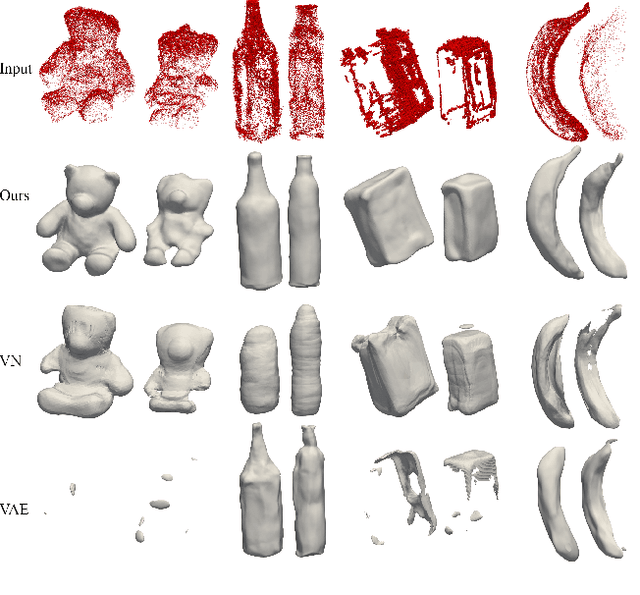
The task of shape space learning involves mapping a train set of shapes to and from a latent representation space with good generalization properties. Often, real-world collections of shapes have symmetries, which can be defined as transformations that do not change the essence of the shape. A natural way to incorporate symmetries in shape space learning is to ask that the mapping to the shape space (encoder) and mapping from the shape space (decoder) are equivariant to the relevant symmetries. In this paper, we present a framework for incorporating equivariance in encoders and decoders by introducing two contributions: (i) adapting the recent Frame Averaging (FA) framework for building generic, efficient, and maximally expressive Equivariant autoencoders; and (ii) constructing autoencoders equivariant to piecewise Euclidean motions applied to different parts of the shape. To the best of our knowledge, this is the first fully piecewise Euclidean equivariant autoencoder construction. Training our framework is simple: it uses standard reconstruction losses and does not require the introduction of new losses. Our architectures are built of standard (backbone) architectures with the appropriate frame averaging to make them equivariant. Testing our framework on both rigid shapes dataset using implicit neural representations, and articulated shape datasets using mesh-based neural networks show state-of-the-art generalization to unseen test shapes, improving relevant baselines by a large margin. In particular, our method demonstrates significant improvement in generalizing to unseen articulated poses.
Hierarchical Neural Implicit Pose Network for Animation and Motion Retargeting
Dec 02, 2021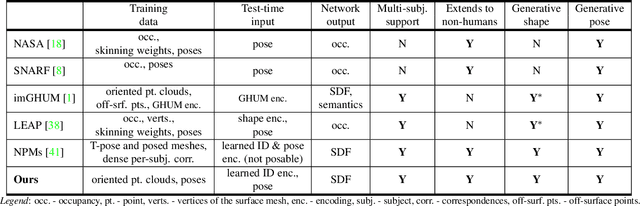
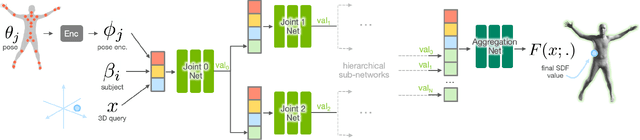
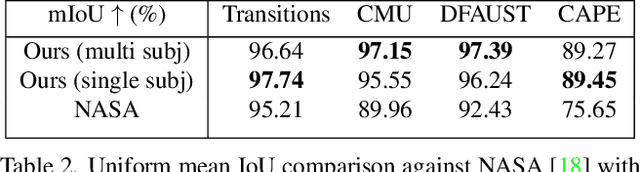
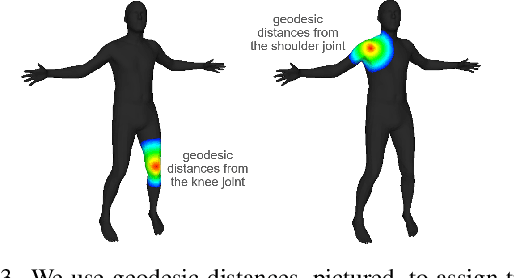
We present HIPNet, a neural implicit pose network trained on multiple subjects across many poses. HIPNet can disentangle subject-specific details from pose-specific details, effectively enabling us to retarget motion from one subject to another or to animate between keyframes through latent space interpolation. To this end, we employ a hierarchical skeleton-based representation to learn a signed distance function on a canonical unposed space. This joint-based decomposition enables us to represent subtle details that are local to the space around the body joint. Unlike previous neural implicit method that requires ground-truth SDF for training, our model we only need a posed skeleton and the point cloud for training, and we have no dependency on a traditional parametric model or traditional skinning approaches. We achieve state-of-the-art results on various single-subject and multi-subject benchmarks.
Neural Fields as Learnable Kernels for 3D Reconstruction
Nov 26, 2021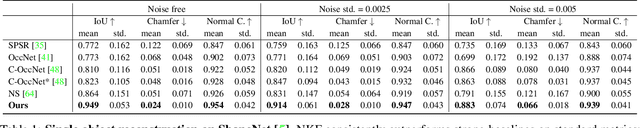

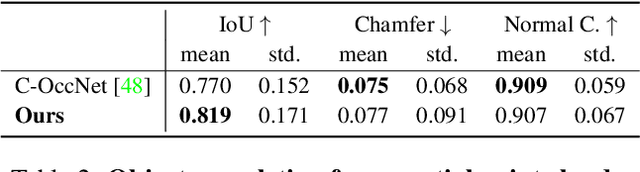
We present Neural Kernel Fields: a novel method for reconstructing implicit 3D shapes based on a learned kernel ridge regression. Our technique achieves state-of-the-art results when reconstructing 3D objects and large scenes from sparse oriented points, and can reconstruct shape categories outside the training set with almost no drop in accuracy. The core insight of our approach is that kernel methods are extremely effective for reconstructing shapes when the chosen kernel has an appropriate inductive bias. We thus factor the problem of shape reconstruction into two parts: (1) a backbone neural network which learns kernel parameters from data, and (2) a kernel ridge regression that fits the input points on-the-fly by solving a simple positive definite linear system using the learned kernel. As a result of this factorization, our reconstruction gains the benefits of data-driven methods under sparse point density while maintaining interpolatory behavior, which converges to the ground truth shape as input sampling density increases. Our experiments demonstrate a strong generalization capability to objects outside the train-set category and scanned scenes. Source code and pretrained models are available at https://nv-tlabs.github.io/nkf.