 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteepest Descent Density Control for Compact 3D Gaussian Splatting
May 08, 20253D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time, high-resolution novel view synthesis. By representing scenes as a mixture of Gaussian primitives, 3DGS leverages GPU rasterization pipelines for efficient rendering and reconstruction. To optimize scene coverage and capture fine details, 3DGS employs a densification algorithm to generate additional points. However, this process often leads to redundant point clouds, resulting in excessive memory usage, slower performance, and substantial storage demands - posing significant challenges for deployment on resource-constrained devices. To address this limitation, we propose a theoretical framework that demystifies and improves density control in 3DGS. Our analysis reveals that splitting is crucial for escaping saddle points. Through an optimization-theoretic approach, we establish the necessary conditions for densification, determine the minimal number of offspring Gaussians, identify the optimal parameter update direction, and provide an analytical solution for normalizing off-spring opacity. Building on these insights, we introduce SteepGS, incorporating steepest density control, a principled strategy that minimizes loss while maintaining a compact point cloud. SteepGS achieves a ~50% reduction in Gaussian points without compromising rendering quality, significantly enhancing both efficiency and scalability.
TextureDreamer: Image-guided Texture Synthesis through Geometry-aware Diffusion
Jan 17, 2024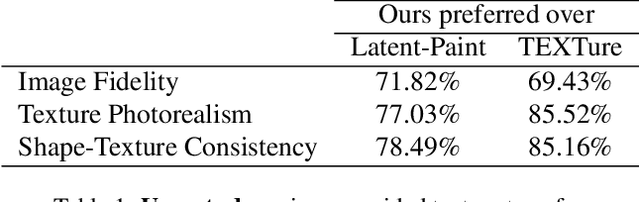


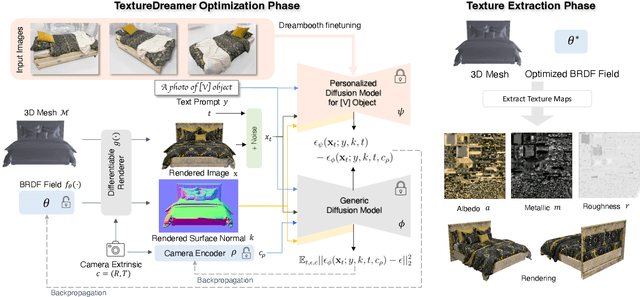
We present TextureDreamer, a novel image-guided texture synthesis method to transfer relightable textures from a small number of input images (3 to 5) to target 3D shapes across arbitrary categories. Texture creation is a pivotal challenge in vision and graphics. Industrial companies hire experienced artists to manually craft textures for 3D assets. Classical methods require densely sampled views and accurately aligned geometry, while learning-based methods are confined to category-specific shapes within the dataset. In contrast, TextureDreamer can transfer highly detailed, intricate textures from real-world environments to arbitrary objects with only a few casually captured images, potentially significantly democratizing texture creation. Our core idea, personalized geometry-aware score distillation (PGSD), draws inspiration from recent advancements in diffuse models, including personalized modeling for texture information extraction, variational score distillation for detailed appearance synthesis, and explicit geometry guidance with ControlNet. Our integration and several essential modifications substantially improve the texture quality. Experiments on real images spanning different categories show that TextureDreamer can successfully transfer highly realistic, semantic meaningful texture to arbitrary objects, surpassing the visual quality of previous state-of-the-art.
Learning to Relight Portrait Images via a Virtual Light Stage and Synthetic-to-Real Adaptation
Sep 21, 2022



Given a portrait image of a person and an environment map of the target lighting, portrait relighting aims to re-illuminate the person in the image as if the person appeared in an environment with the target lighting. To achieve high-quality results, recent methods rely on deep learning. An effective approach is to supervise the training of deep neural networks with a high-fidelity dataset of desired input-output pairs, captured with a light stage. However, acquiring such data requires an expensive special capture rig and time-consuming efforts, limiting access to only a few resourceful laboratories. To address the limitation, we propose a new approach that can perform on par with the state-of-the-art (SOTA) relighting methods without requiring a light stage. Our approach is based on the realization that a successful relighting of a portrait image depends on two conditions. First, the method needs to mimic the behaviors of physically-based relighting. Second, the output has to be photorealistic. To meet the first condition, we propose to train the relighting network with training data generated by a virtual light stage that performs physically-based rendering on various 3D synthetic humans under different environment maps. To meet the second condition, we develop a novel synthetic-to-real approach to bring photorealism to the relighting network output. In addition to achieving SOTA results, our approach offers several advantages over the prior methods, including controllable glares on glasses and more temporally-consistent results for relighting videos.
* To appear in ACM Transactions on Graphics (SIGGRAPH Asia 2022). 21 pages, 25 figures, 7 tables. Project page: https://deepimagination.cc/Lumos/
PhotoScene: Photorealistic Material and Lighting Transfer for Indoor Scenes
Jul 02, 2022

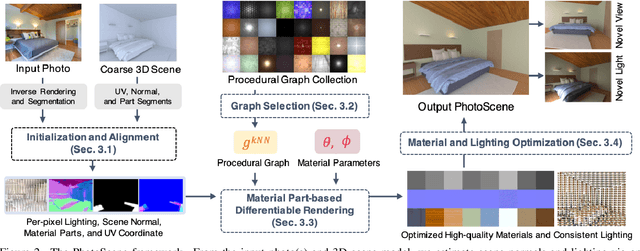
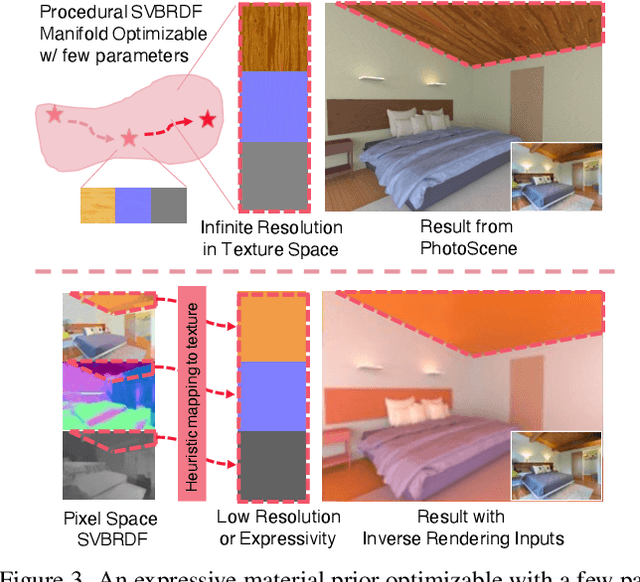
Most indoor 3D scene reconstruction methods focus on recovering 3D geometry and scene layout. In this work, we go beyond this to propose PhotoScene, a framework that takes input image(s) of a scene along with approximately aligned CAD geometry (either reconstructed automatically or manually specified) and builds a photorealistic digital twin with high-quality materials and similar lighting. We model scene materials using procedural material graphs; such graphs represent photorealistic and resolution-independent materials. We optimize the parameters of these graphs and their texture scale and rotation, as well as the scene lighting to best match the input image via a differentiable rendering layer. We evaluate our technique on objects and layout reconstructions from ScanNet, SUN RGB-D and stock photographs, and demonstrate that our method reconstructs high-quality, fully relightable 3D scenes that can be re-rendered under arbitrary viewpoints, zooms and lighting.
Through the Looking Glass: Neural 3D Reconstruction of Transparent Shapes
Apr 22, 2020
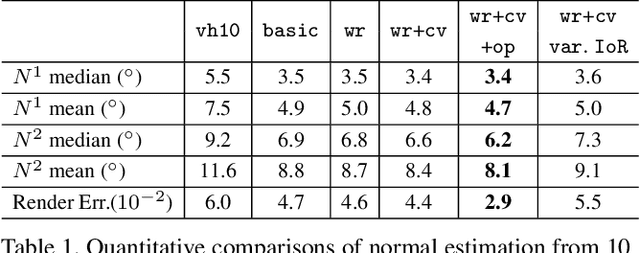

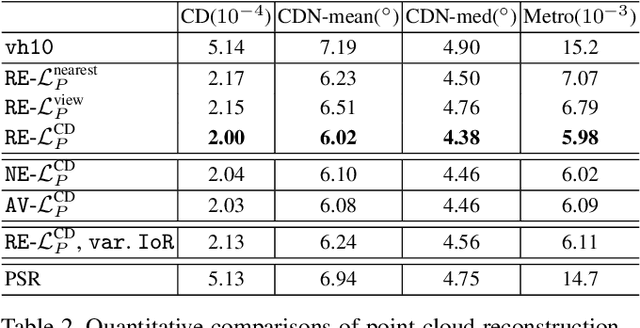
Recovering the 3D shape of transparent objects using a small number of unconstrained natural images is an ill-posed problem. Complex light paths induced by refraction and reflection have prevented both traditional and deep multiview stereo from solving this challenge. We propose a physically-based network to recover 3D shape of transparent objects using a few images acquired with a mobile phone camera, under a known but arbitrary environment map. Our novel contributions include a normal representation that enables the network to model complex light transport through local computation, a rendering layer that models refractions and reflections, a cost volume specifically designed for normal refinement of transparent shapes and a feature mapping based on predicted normals for 3D point cloud reconstruction. We render a synthetic dataset to encourage the model to learn refractive light transport across different views. Our experiments show successful recovery of high-quality 3D geometry for complex transparent shapes using as few as 5-12 natural images. Code and data are publicly released.
A Unified Feature Disentangler for Multi-Domain Image Translation and Manipulation
Oct 28, 2018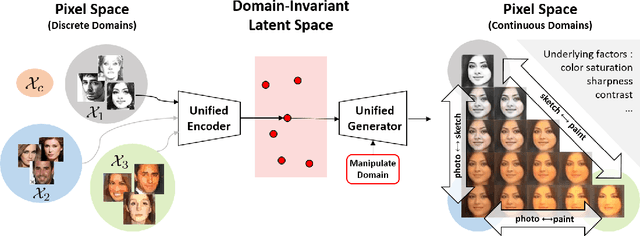

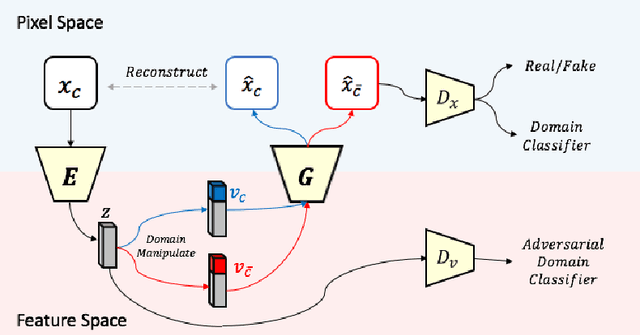
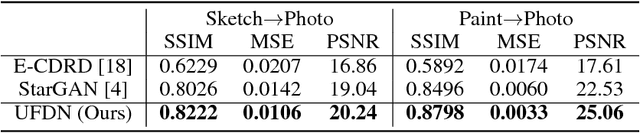
We present a novel and unified deep learning framework which is capable of learning domain-invariant representation from data across multiple domains. Realized by adversarial training with additional ability to exploit domain-specific information, the proposed network is able to perform continuous cross-domain image translation and manipulation, and produces desirable output images accordingly. In addition, the resulting feature representation exhibits superior performance of unsupervised domain adaptation, which also verifies the effectiveness of the proposed model in learning disentangled features for describing cross-domain data.
Detach and Adapt: Learning Cross-Domain Disentangled Deep Representation
May 01, 2018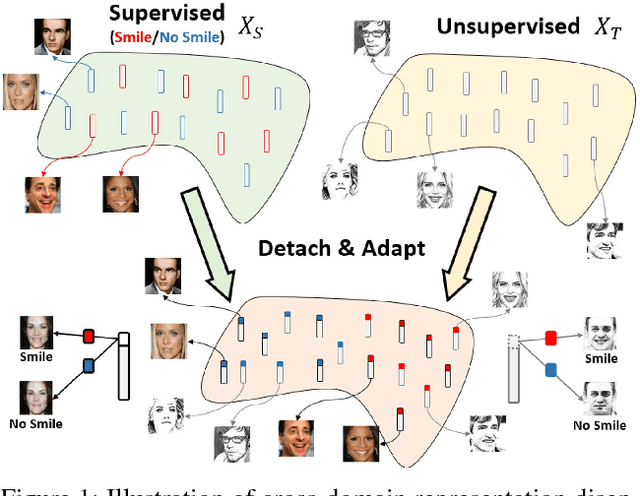
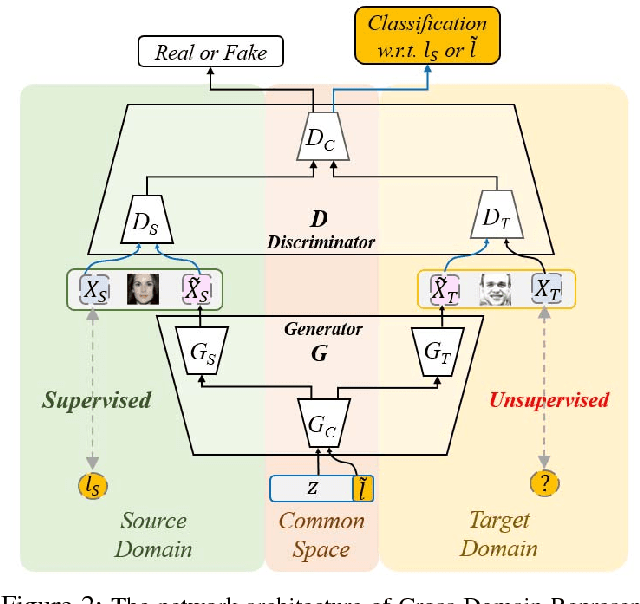


While representation learning aims to derive interpretable features for describing visual data, representation disentanglement further results in such features so that particular image attributes can be identified and manipulated. However, one cannot easily address this task without observing ground truth annotation for the training data. To address this problem, we propose a novel deep learning model of Cross-Domain Representation Disentangler (CDRD). By observing fully annotated source-domain data and unlabeled target-domain data of interest, our model bridges the information across data domains and transfers the attribute information accordingly. Thus, cross-domain joint feature disentanglement and adaptation can be jointly performed. In the experiments, we provide qualitative results to verify our disentanglement capability. Moreover, we further confirm that our model can be applied for solving classification tasks of unsupervised domain adaptation, and performs favorably against state-of-the-art image disentanglement and translation methods.
Adaptation and Re-Identification Network: An Unsupervised Deep Transfer Learning Approach to Person Re-Identification
Apr 25, 2018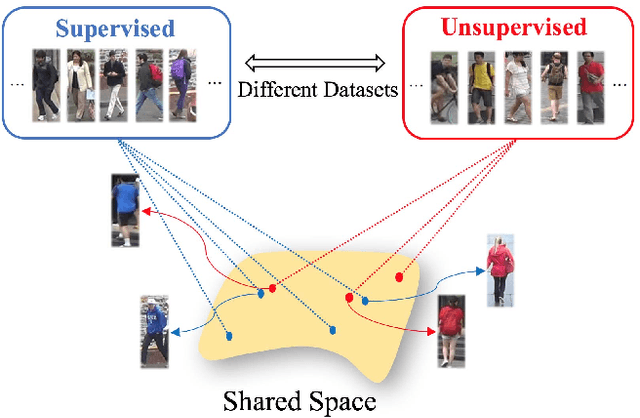
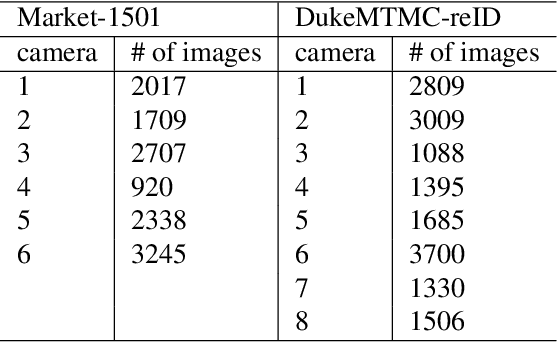
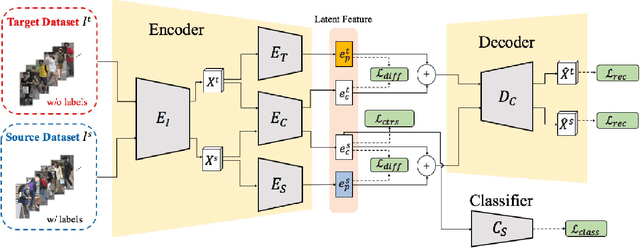

Person re-identification (Re-ID) aims at recognizing the same person from images taken across different cameras. To address this task, one typically requires a large amount labeled data for training an effective Re-ID model, which might not be practical for real-world applications. To alleviate this limitation, we choose to exploit a sufficient amount of pre-existing labeled data from a different (auxiliary) dataset. By jointly considering such an auxiliary dataset and the dataset of interest (but without label information), our proposed adaptation and re-identification network (ARN) performs unsupervised domain adaptation, which leverages information across datasets and derives domain-invariant features for Re-ID purposes. In our experiments, we verify that our network performs favorably against state-of-the-art unsupervised Re-ID approaches, and even outperforms a number of baseline Re-ID methods which require fully supervised data for training.