 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadarSplat-RIO: Indoor Radar-Inertial Odometry with Gaussian Splatting-Based Radar Bundle Adjustment
Apr 15, 2026Radar is more resilient to adverse weather and lighting conditions than visual and Lidar simultaneous localization and mapping (SLAM). However, most radar SLAM pipelines still rely heavily on frame-to-frame odometry, which leads to substantial drift. While loop closure can correct long-term errors, it requires revisiting places and relies on robust place recognition. In contrast, visual odometry methods typically leverage bundle adjustment (BA) to jointly optimize poses and map within a local window. However, an equivalent BA formulation for radar has remained largely unexplored. We present the first radar BA framework enabled by Gaussian Splatting (GS), a dense and differentiable scene representation. Our method jointly optimizes radar sensor poses and scene geometry using full range-azimuth-Doppler data, bringing the benefits of multi-frame BA to radar for the first time. When integrated with an existing radar-inertial odometry frontend, our approach significantly reduces pose drift and improves robustness. Across multiple indoor scenes, our radar BA achieves substantial gains over the prior radar-inertial odometry, reducing average absolute translational and rotational errors by 90% and 80%, respectively.
LSRM: High-Fidelity Object-Centric Reconstruction via Scaled Context Windows
Apr 06, 2026We introduce the Large Sparse Reconstruction Model to study how scaling transformer context windows impacts feed-forward 3D reconstruction. Although recent object-centric feed-forward methods deliver robust, high-quality reconstruction, they still lag behind dense-view optimization in recovering fine-grained texture and appearance. We show that expanding the context window -- by substantially increasing the number of active object and image tokens -- remarkably narrows this gap and enables high-fidelity 3D object reconstruction and inverse rendering. To scale effectively, we adapt native sparse attention in our architecture design, unlocking its capacity for 3D reconstruction with three key contributions: (1) an efficient coarse-to-fine pipeline that focuses computation on informative regions by predicting sparse high-resolution residuals; (2) a 3D-aware spatial routing mechanism that establishes accurate 2D-3D correspondences using explicit geometric distances rather than standard attention scores; and (3) a custom block-aware sequence parallelism strategy utilizing an All-gather-KV protocol to balance dynamic, sparse workloads across GPUs. As a result, LSRM handles 20x more object tokens and >2x more image tokens than prior state-of-the-art (SOTA) methods. Extensive evaluations on standard novel-view synthesis benchmarks show substantial gains over the current SOTA, yielding 2.5 dB higher PSNR and 40% lower LPIPS. Furthermore, when extending LSRM to inverse rendering tasks, qualitative and quantitative evaluations on widely-used benchmarks demonstrate consistent improvements in texture and geometry details, achieving an LPIPS that matches or exceeds that of SOTA dense-view optimization methods. Code and model will be released on our project page.
Free-Range Gaussians: Non-Grid-Aligned Generative 3D Gaussian Reconstruction
Apr 06, 2026We present Free-Range Gaussians, a multi-view reconstruction method that predicts non-pixel, non-voxel-aligned 3D Gaussians from as few as four images. This is done through flow matching over Gaussian parameters. Our generative formulation of reconstruction allows the model to be supervised with non-grid-aligned 3D data, and enables it to synthesize plausible content in unobserved regions. Thus, it improves on prior methods that produce highly redundant grid-aligned Gaussians, and suffer from holes or blurry conditional means in unobserved regions. To handle the number of Gaussians needed for high-quality results, we introduce a hierarchical patching scheme to group spatially related Gaussians into joint transformer tokens, halving the sequence length while preserving structure. We further propose a timestep-weighted rendering loss during training, and photometric gradient guidance and classifier-free guidance at inference to improve fidelity. Experiments on Objaverse and Google Scanned Objects show consistent improvements over pixel and voxel-aligned methods while using significantly fewer Gaussians, with large gains when input views leave parts of the object unobserved.
ShapeR: Robust Conditional 3D Shape Generation from Casual Captures
Jan 16, 2026Recent advances in 3D shape generation have achieved impressive results, but most existing methods rely on clean, unoccluded, and well-segmented inputs. Such conditions are rarely met in real-world scenarios. We present ShapeR, a novel approach for conditional 3D object shape generation from casually captured sequences. Given an image sequence, we leverage off-the-shelf visual-inertial SLAM, 3D detection algorithms, and vision-language models to extract, for each object, a set of sparse SLAM points, posed multi-view images, and machine-generated captions. A rectified flow transformer trained to effectively condition on these modalities then generates high-fidelity metric 3D shapes. To ensure robustness to the challenges of casually captured data, we employ a range of techniques including on-the-fly compositional augmentations, a curriculum training scheme spanning object- and scene-level datasets, and strategies to handle background clutter. Additionally, we introduce a new evaluation benchmark comprising 178 in-the-wild objects across 7 real-world scenes with geometry annotations. Experiments show that ShapeR significantly outperforms existing approaches in this challenging setting, achieving an improvement of 2.7x in Chamfer distance compared to state of the art.
Flowing from Reasoning to Motion: Learning 3D Hand Trajectory Prediction from Egocentric Human Interaction Videos
Dec 18, 2025Prior works on 3D hand trajectory prediction are constrained by datasets that decouple motion from semantic supervision and by models that weakly link reasoning and action. To address these, we first present the EgoMAN dataset, a large-scale egocentric dataset for interaction stage-aware 3D hand trajectory prediction with 219K 6DoF trajectories and 3M structured QA pairs for semantic, spatial, and motion reasoning. We then introduce the EgoMAN model, a reasoning-to-motion framework that links vision-language reasoning and motion generation via a trajectory-token interface. Trained progressively to align reasoning with motion dynamics, our approach yields accurate and stage-aware trajectories with generalization across real-world scenes.
ART: Articulated Reconstruction Transformer
Dec 16, 2025We introduce ART, Articulated Reconstruction Transformer -- a category-agnostic, feed-forward model that reconstructs complete 3D articulated objects from only sparse, multi-state RGB images. Previous methods for articulated object reconstruction either rely on slow optimization with fragile cross-state correspondences or use feed-forward models limited to specific object categories. In contrast, ART treats articulated objects as assemblies of rigid parts, formulating reconstruction as part-based prediction. Our newly designed transformer architecture maps sparse image inputs to a set of learnable part slots, from which ART jointly decodes unified representations for individual parts, including their 3D geometry, texture, and explicit articulation parameters. The resulting reconstructions are physically interpretable and readily exportable for simulation. Trained on a large-scale, diverse dataset with per-part supervision, and evaluated across diverse benchmarks, ART achieves significant improvements over existing baselines and establishes a new state of the art for articulated object reconstruction from image inputs.
DGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025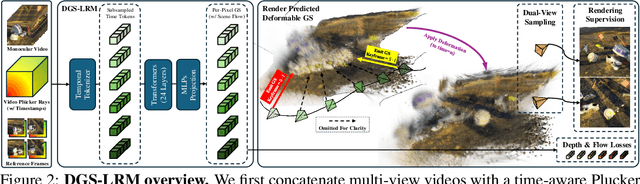
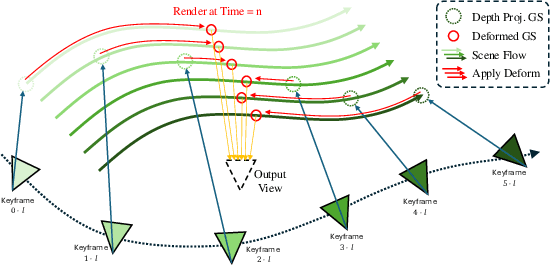
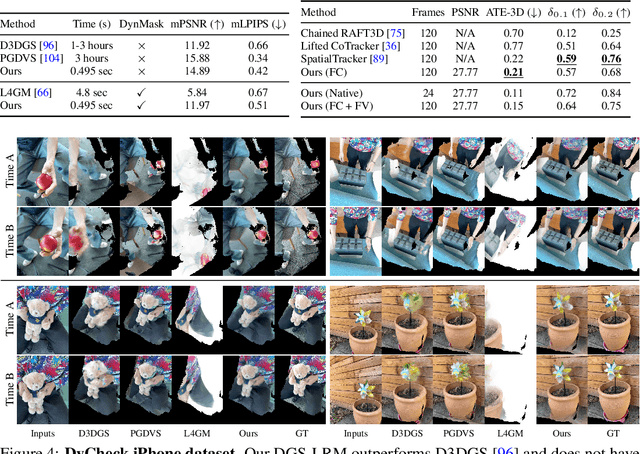

We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
4DGT: Learning a 4D Gaussian Transformer Using Real-World Monocular Videos
Jun 09, 2025
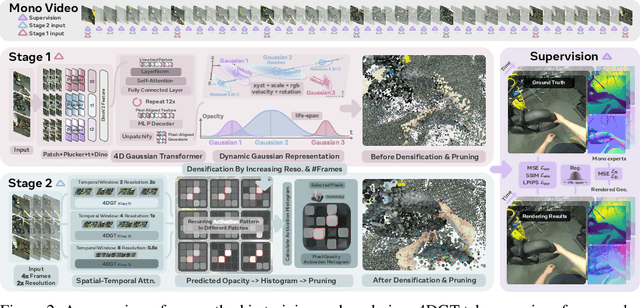


We propose 4DGT, a 4D Gaussian-based Transformer model for dynamic scene reconstruction, trained entirely on real-world monocular posed videos. Using 4D Gaussian as an inductive bias, 4DGT unifies static and dynamic components, enabling the modeling of complex, time-varying environments with varying object lifespans. We proposed a novel density control strategy in training, which enables our 4DGT to handle longer space-time input and remain efficient rendering at runtime. Our model processes 64 consecutive posed frames in a rolling-window fashion, predicting consistent 4D Gaussians in the scene. Unlike optimization-based methods, 4DGT performs purely feed-forward inference, reducing reconstruction time from hours to seconds and scaling effectively to long video sequences. Trained only on large-scale monocular posed video datasets, 4DGT can outperform prior Gaussian-based networks significantly in real-world videos and achieve on-par accuracy with optimization-based methods on cross-domain videos. Project page: https://4dgt.github.io
Monocular Online Reconstruction with Enhanced Detail Preservation
May 14, 2025We propose an online 3D Gaussian-based dense mapping framework for photorealistic details reconstruction from a monocular image stream. Our approach addresses two key challenges in monocular online reconstruction: distributing Gaussians without relying on depth maps and ensuring both local and global consistency in the reconstructed maps. To achieve this, we introduce two key modules: the Hierarchical Gaussian Management Module for effective Gaussian distribution and the Global Consistency Optimization Module for maintaining alignment and coherence at all scales. In addition, we present the Multi-level Occupancy Hash Voxels (MOHV), a structure that regularizes Gaussians for capturing details across multiple levels of granularity. MOHV ensures accurate reconstruction of both fine and coarse geometries and textures, preserving intricate details while maintaining overall structural integrity. Compared to state-of-the-art RGB-only and even RGB-D methods, our framework achieves superior reconstruction quality with high computational efficiency. Moreover, it integrates seamlessly with various tracking systems, ensuring generality and scalability.
LIRM: Large Inverse Rendering Model for Progressive Reconstruction of Shape, Materials and View-dependent Radiance Fields
Apr 28, 2025We present Large Inverse Rendering Model (LIRM), a transformer architecture that jointly reconstructs high-quality shape, materials, and radiance fields with view-dependent effects in less than a second. Our model builds upon the recent Large Reconstruction Models (LRMs) that achieve state-of-the-art sparse-view reconstruction quality. However, existing LRMs struggle to reconstruct unseen parts accurately and cannot recover glossy appearance or generate relightable 3D contents that can be consumed by standard Graphics engines. To address these limitations, we make three key technical contributions to build a more practical multi-view 3D reconstruction framework. First, we introduce an update model that allows us to progressively add more input views to improve our reconstruction. Second, we propose a hexa-plane neural SDF representation to better recover detailed textures, geometry and material parameters. Third, we develop a novel neural directional-embedding mechanism to handle view-dependent effects. Trained on a large-scale shape and material dataset with a tailored coarse-to-fine training scheme, our model achieves compelling results. It compares favorably to optimization-based dense-view inverse rendering methods in terms of geometry and relighting accuracy, while requiring only a fraction of the inference time.