 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperBones: Realtime Bone-driven Neural Garment Simulation with Hypernetwork Conditioning
May 19, 2026Recent advances in garment simulation have brought high-quality results closer to real-time performance. Physics-based simulators can produce accurate motion, but remain too computationally expensive for interactive applications. In contrast, linear blend skinning is efficient, but cannot capture the complex dynamics of loose-fitting garments, often leading to unrealistic motion and visual artifacts. Neural methods offer a promising alternative, yet they still struggle to animate loose clothing plausibly under strict runtime constraints. We present a fast and physically plausible approach for dynamic garment simulation. Our method trains a reduced-space neural dynamics simulator composed of independent coarse- and fine-level components. At the coarse level, the garment is driven by a set of virtual bones integrated with a lightweight neural network. Fine-scale wrinkle details are then recovered using a trained convolutional neural map. By decoupling identity-specific computation from real-time neural integration, our architecture maintains high performance while supporting diverse body shapes and motions. We further introduce an effective physics-supervision scheme that enables accurate results without relying on an external simulator. Experiments show that our method produces physically plausible garment dynamics, generalizes across a range of motions and body shapes, and supports a fixed set of garments. Our simulator runs at 300+ FPS on a commodity GPU, making it suitable for real-time applications.
RigidFormer: Learning Rigid Dynamics using Transformers
May 09, 2026Learning-based simulation of multi-object rigid-body dynamics remains difficult because contact is discontinuous and errors compound over long horizons. Most existing methods remain tied to mesh connectivity and vertex-level message passing, which limits their applicability to mesh-free inputs such as point clouds and leads to high computational cost. Efficiently modeling high-fidelity rigid-body dynamics from mesh-free representations, therefore, remains challenging. We introduce RigidFormer, an object-centric Transformer-based model that learns mesh-free rigid-body dynamics with controllable integration step sizes. RigidFormer reasons at the object level and advances each object through compact anchors; Anchor-Vertex Pooling enriches these anchors with local vertex features, retaining contact-relevant geometry without dense vertex-level interaction. We propose Anchor-based RoPE to inject anchor geometry into attention while respecting the unordered nature of objects and anchors: object-token processing is permutation-equivariant, and the mean-pooled anchor descriptor is invariant to anchor reindexing while preserving shape extent. RigidFormer further enforces rigidity by projecting updates onto the rigid-body manifold using differentiable Kabsch alignment. On standard benchmarks, RigidFormer outperforms or matches mesh-based baselines using point inputs, runs faster, generalizes to unseen point resolutions and across datasets, and scales to 200+ objects; we also show a preliminary extension to command-conditioned articulated bodies by treating body parts as interacting object-level components.
HairWeaver: Few-Shot Photorealistic Hair Motion Synthesis with Sim-to-Real Guided Video Diffusion
Feb 11, 2026We present HairWeaver, a diffusion-based pipeline that animates a single human image with realistic and expressive hair dynamics. While existing methods successfully control body pose, they lack specific control over hair, and as a result, fail to capture the intricate hair motions, resulting in stiff and unrealistic animations. HairWeaver overcomes this limitation using two specialized modules: a Motion-Context-LoRA to integrate motion conditions and a Sim2Real-Domain-LoRA to preserve the subject's photoreal appearance across different data domains. These lightweight components are designed to guide a video diffusion backbone while maintaining its core generative capabilities. By training on a specialized dataset of dynamic human motion generated from a CG simulator, HairWeaver affords fine control over hair motion and ultimately learns to produce highly realistic hair that responds naturally to movement. Comprehensive evaluations demonstrate that our approach sets a new state of the art, producing lifelike human hair animations with dynamic details.
Neural Modular Physics for Elastic Simulation
Dec 17, 2025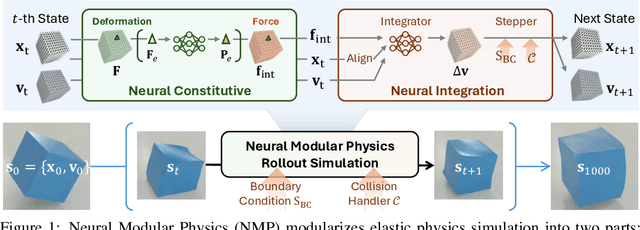
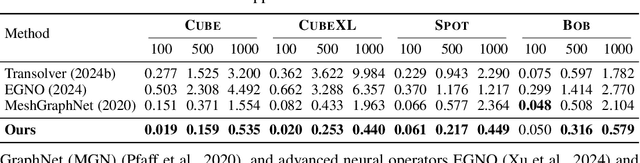
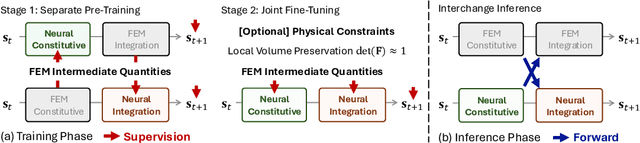
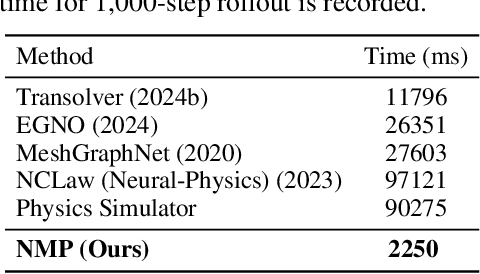
Learning-based methods have made significant progress in physics simulation, typically approximating dynamics with a monolithic end-to-end optimized neural network. Although these models offer an effective way to simulation, they may lose essential features compared to traditional numerical simulators, such as physical interpretability and reliability. Drawing inspiration from classical simulators that operate in a modular fashion, this paper presents Neural Modular Physics (NMP) for elastic simulation, which combines the approximation capacity of neural networks with the physical reliability of traditional simulators. Beyond the previous monolithic learning paradigm, NMP enables direct supervision of intermediate quantities and physical constraints by decomposing elastic dynamics into physically meaningful neural modules connected through intermediate physical quantities. With a specialized architecture and training strategy, our method transforms the numerical computation flow into a modular neural simulator, achieving improved physical consistency and generalizability. Experimentally, NMP demonstrates superior generalization to unseen initial conditions and resolutions, stable long-horizon simulation, better preservation of physical properties compared to other neural simulators, and greater feasibility in scenarios with unknown underlying dynamics than traditional simulators.
Quaffure: Real-Time Quasi-Static Neural Hair Simulation
Dec 13, 2024



Realistic hair motion is crucial for high-quality avatars, but it is often limited by the computational resources available for real-time applications. To address this challenge, we propose a novel neural approach to predict physically plausible hair deformations that generalizes to various body poses, shapes, and hairstyles. Our model is trained using a self-supervised loss, eliminating the need for expensive data generation and storage. We demonstrate our method's effectiveness through numerous results across a wide range of pose and shape variations, showcasing its robust generalization capabilities and temporally smooth results. Our approach is highly suitable for real-time applications with an inference time of only a few milliseconds on consumer hardware and its ability to scale to predicting the drape of 1000 grooms in 0.3 seconds.
3D Mesh Editing using Masked LRMs
Dec 11, 2024We present a novel approach to mesh shape editing, building on recent progress in 3D reconstruction from multi-view images. We formulate shape editing as a conditional reconstruction problem, where the model must reconstruct the input shape with the exception of a specified 3D region, in which the geometry should be generated from the conditional signal. To this end, we train a conditional Large Reconstruction Model (LRM) for masked reconstruction, using multi-view consistent masks rendered from a randomly generated 3D occlusion, and using one clean viewpoint as the conditional signal. During inference, we manually define a 3D region to edit and provide an edited image from a canonical viewpoint to fill in that region. We demonstrate that, in just a single forward pass, our method not only preserves the input geometry in the unmasked region through reconstruction capabilities on par with SoTA, but is also expressive enough to perform a variety of mesh edits from a single image guidance that past works struggle with, while being 10x faster than the top-performing competing prior work.
Garment3DGen: 3D Garment Stylization and Texture Generation
Mar 27, 2024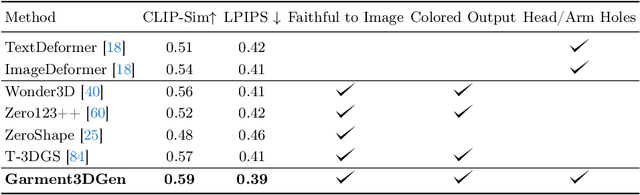
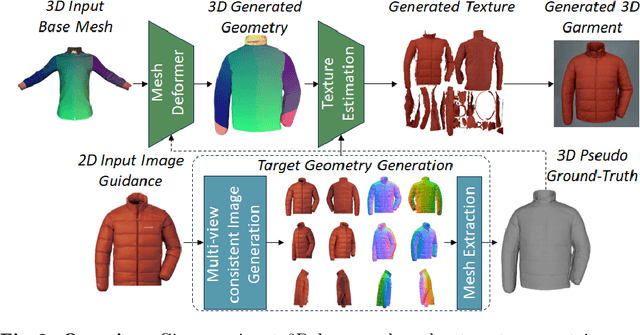


We introduce Garment3DGen a new method to synthesize 3D garment assets from a base mesh given a single input image as guidance. Our proposed approach allows users to generate 3D textured clothes based on both real and synthetic images, such as those generated by text prompts. The generated assets can be directly draped and simulated on human bodies. First, we leverage the recent progress of image to 3D diffusion methods to generate 3D garment geometries. However, since these geometries cannot be utilized directly for downstream tasks, we propose to use them as pseudo ground-truth and set up a mesh deformation optimization procedure that deforms a base template mesh to match the generated 3D target. Second, we introduce carefully designed losses that allow the input base mesh to freely deform towards the desired target, yet preserve mesh quality and topology such that they can be simulated. Finally, a texture estimation module generates high-fidelity texture maps that are globally and locally consistent and faithfully capture the input guidance, allowing us to render the generated 3D assets. With Garment3DGen users can generate the textured 3D garment of their choice without the need of artist intervention. One can provide a textual prompt describing the garment they desire to generate a simulation-ready 3D asset. We present a plethora of quantitative and qualitative comparisons on various assets both real and generated and provide use-cases of how one can generate simulation-ready 3D garments.
DiffAvatar: Simulation-Ready Garment Optimization with Differentiable Simulation
Nov 20, 2023



The realism of digital avatars is crucial in enabling telepresence applications with self-expression and customization. A key aspect of this realism originates from the physical accuracy of both a true-to-life body shape and clothing. While physical simulations can produce high-quality, realistic motions for clothed humans, they require precise estimation of body shape and high-quality garment assets with associated physical parameters for cloth simulations. However, manually creating these assets and calibrating their parameters is labor-intensive and requires specialized expertise. To address this gap, we propose DiffAvatar, a novel approach that performs body and garment co-optimization using differentiable simulation. By integrating physical simulation into the optimization loop and accounting for the complex nonlinear behavior of cloth and its intricate interaction with the body, our framework recovers body and garment geometry and extracts important material parameters in a physically plausible way. Our experiments demonstrate that our approach generates realistic clothing and body shape that can be easily used in downstream applications.
PhysGraph: Physics-Based Integration Using Graph Neural Networks
Jan 27, 2023Physics-based simulation of mesh based domains remains a challenging task. State-of-the-art techniques can produce realistic results but require expert knowledge. A major bottleneck in many approaches is the step of integrating a potential energy in order to compute velocities or displacements. Recently, learning based method for physics-based simulation have sparked interest with graph based approaches being a promising research direction. One of the challenges for these methods is to generate models that are mesh independent and generalize to different material properties. Moreover, the model should also be able to react to unforeseen external forces like ubiquitous collisions. Our contribution is based on a simple observation: evaluating forces is computationally relatively cheap for traditional simulation methods and can be computed in parallel in contrast to their integration. If we learn how a system reacts to forces in general, irrespective of their origin, we can learn an integrator that can predict state changes due to the total forces with high generalization power. We effectively factor out the physical model behind resulting forces by relying on an opaque force module. We demonstrate that this idea leads to a learnable module that can be trained on basic internal forces of small mesh patches and generalizes to different mesh typologies, resolutions, material parameters and unseen forces like collisions at inference time. Our proposed paradigm is general and can be used to model a variety of physical phenomena. We focus our exposition on the detail enhancement of coarse clothing geometry which has many applications including computer games, virtual reality and virtual try-on.
NeuWigs: A Neural Dynamic Model for Volumetric Hair Capture and Animation
Dec 08, 2022



The capture and animation of human hair are two of the major challenges in the creation of realistic avatars for the virtual reality. Both problems are highly challenging, because hair has complex geometry and appearance, as well as exhibits challenging motion. In this paper, we present a two-stage approach that models hair independently from the head to address these challenges in a data-driven manner. The first stage, state compression, learns a low-dimensional latent space of 3D hair states containing motion and appearance, via a novel autoencoder-as-a-tracker strategy. To better disentangle the hair and head in appearance learning, we employ multi-view hair segmentation masks in combination with a differentiable volumetric renderer. The second stage learns a novel hair dynamics model that performs temporal hair transfer based on the discovered latent codes. To enforce higher stability while driving our dynamics model, we employ the 3D point-cloud autoencoder from the compression stage for de-noising of the hair state. Our model outperforms the state of the art in novel view synthesis and is capable of creating novel hair animations without having to rely on hair observations as a driving signal. Project page is here https://ziyanw1.github.io/neuwigs/.