 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarment Avatars: Realistic Cloth Driving using Pattern Registration
Paper and Code
Jun 07, 2022

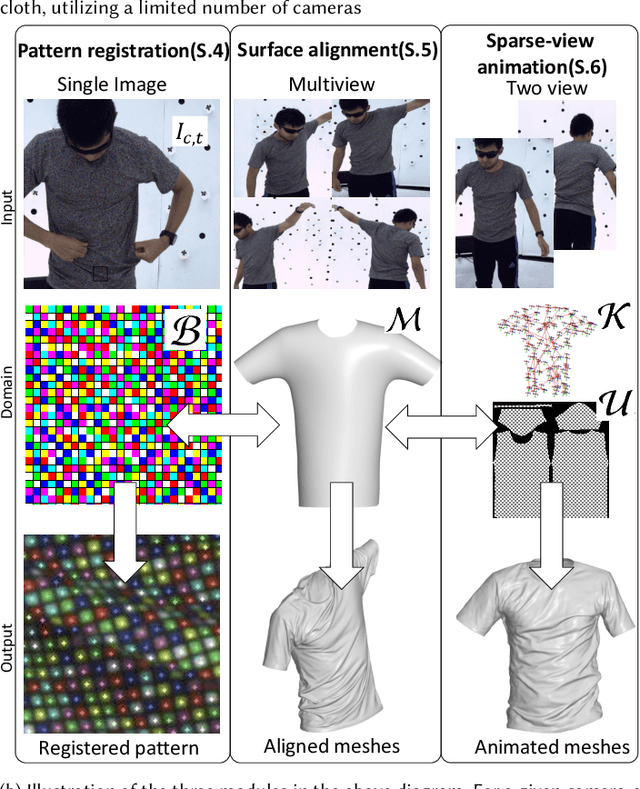

Virtual telepresence is the future of online communication. Clothing is an essential part of a person's identity and self-expression. Yet, ground truth data of registered clothes is currently unavailable in the required resolution and accuracy for training telepresence models for realistic cloth animation. Here, we propose an end-to-end pipeline for building drivable representations for clothing. The core of our approach is a multi-view patterned cloth tracking algorithm capable of capturing deformations with high accuracy. We further rely on the high-quality data produced by our tracking method to build a Garment Avatar: an expressive and fully-drivable geometry model for a piece of clothing. The resulting model can be animated using a sparse set of views and produces highly realistic reconstructions which are faithful to the driving signals. We demonstrate the efficacy of our pipeline on a realistic virtual telepresence application, where a garment is being reconstructed from two views, and a user can pick and swap garment design as they wish. In addition, we show a challenging scenario when driven exclusively with body pose, our drivable garment avatar is capable of producing realistic cloth geometry of significantly higher quality than the state-of-the-art.