 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoRelight: Learning Joint Geometrical Relighting and Reconstruction with Flexible Multi-Modal Diffusion Transformers
Apr 22, 2026Relighting a person from a single photo is an attractive but ill-posed task, as a 2D image ambiguously entangles 3D geometry, intrinsic appearance, and illumination. Current methods either use sequential pipelines that suffer from error accumulation, or they do not explicitly leverage 3D geometry during relighting, which limits physical consistency. Since relighting and estimation of 3D geometry are mutually beneficial tasks, we propose a unified Multi-Modal Diffusion Transformer (DiT) that jointly solves for both: GeoRelight. We make this possible through two key technical contributions: isotropic NDC-Orthographic Depth (iNOD), a distortion-free 3D representation compatible with latent diffusion models; and a strategic mixed-data training method that combines synthetic and auto-labeled real data. By solving geometry and relighting jointly, GeoRelight achieves better performance than both sequential models and previous systems that ignored geometry.
GenLCA: 3D Diffusion for Full-Body Avatars from In-the-Wild Videos
Apr 09, 2026We present GenLCA, a diffusion-based generative model for generating and editing photorealistic full-body avatars from text and image inputs. The generated avatars are faithful to the inputs, while supporting high-fidelity facial and full-body animations. The core idea is a novel paradigm that enables training a full-body 3D diffusion model from partially observable 2D data, allowing the training dataset to scale to millions of real-world videos. This scalability contributes to the superior photorealism and generalizability of GenLCA. Specifically, we scale up the dataset by repurposing a pretrained feed-forward avatar reconstruction model as an animatable 3D tokenizer, which encodes unstructured video frames into structured 3D tokens. However, most real-world videos only provide partial observations of body parts, resulting in excessive blurring or transparency artifacts in the 3D tokens. To address this, we propose a novel visibility-aware diffusion training strategy that replaces invalid regions with learnable tokens and computes losses only over valid regions. We then train a flow-based diffusion model on the token dataset, inherently maintaining the photorealism and animatability provided by the pretrained avatar reconstruction model. Our approach effectively enables the use of large-scale real-world video data to train a diffusion model natively in 3D. We demonstrate the efficacy of our method through diverse and high-fidelity generation and editing results, outperforming existing solutions by a large margin. The project page is available at https://onethousandwu.com/GenLCA-Page.
CamLit: Unified Video Diffusion with Explicit Camera and Lighting Control
Mar 15, 2026We present CamLit, the first unified video diffusion model that jointly performs novel view synthesis (NVS) and relighting from a single input image. Given one reference image, a user-defined camera trajectory, and an environment map, CamLit synthesizes a video of the scene from new viewpoints under the specified illumination. Within a single generative process, our model produces temporally coherent and spatially aligned outputs, including relit novel-view frames and corresponding albedo frames, enabling high-quality control of both camera pose and lighting. Qualitative and quantitative experiments demonstrate that CamLit achieves high-fidelity outputs on par with state-of-the-art methods in both novel view synthesis and relighting, without sacrificing visual quality in either task. We show that a single generative model can effectively integrate camera and lighting control, simplifying the video generation pipeline while maintaining competitive performance and consistent realism.
FactorPortrait: Controllable Portrait Animation via Disentangled Expression, Pose, and Viewpoint
Dec 12, 2025We introduce FactorPortrait, a video diffusion method for controllable portrait animation that enables lifelike synthesis from disentangled control signals of facial expressions, head movement, and camera viewpoints. Given a single portrait image, a driving video, and camera trajectories, our method animates the portrait by transferring facial expressions and head movements from the driving video while simultaneously enabling novel view synthesis from arbitrary viewpoints. We utilize a pre-trained image encoder to extract facial expression latents from the driving video as control signals for animation generation. Such latents implicitly capture nuanced facial expression dynamics with identity and pose information disentangled, and they are efficiently injected into the video diffusion transformer through our proposed expression controller. For camera and head pose control, we employ Plücker ray maps and normal maps rendered from 3D body mesh tracking. To train our model, we curate a large-scale synthetic dataset containing diverse combinations of camera viewpoints, head poses, and facial expression dynamics. Extensive experiments demonstrate that our method outperforms existing approaches in realism, expressiveness, control accuracy, and view consistency.
Pippo: High-Resolution Multi-View Humans from a Single Image
Feb 11, 2025
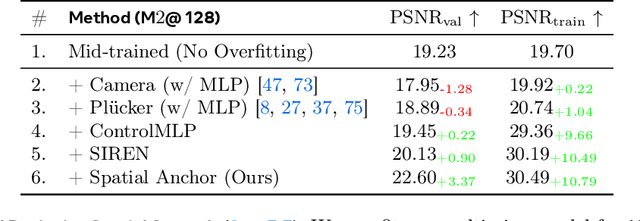
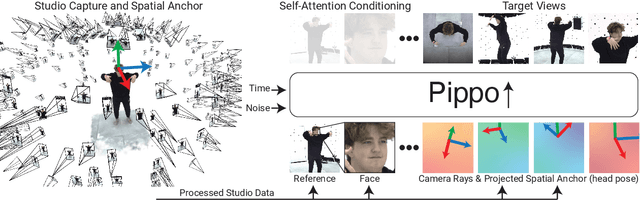

We present Pippo, a generative model capable of producing 1K resolution dense turnaround videos of a person from a single casually clicked photo. Pippo is a multi-view diffusion transformer and does not require any additional inputs - e.g., a fitted parametric model or camera parameters of the input image. We pre-train Pippo on 3B human images without captions, and conduct multi-view mid-training and post-training on studio captured humans. During mid-training, to quickly absorb the studio dataset, we denoise several (up to 48) views at low-resolution, and encode target cameras coarsely using a shallow MLP. During post-training, we denoise fewer views at high-resolution and use pixel-aligned controls (e.g., Spatial anchor and Plucker rays) to enable 3D consistent generations. At inference, we propose an attention biasing technique that allows Pippo to simultaneously generate greater than 5 times as many views as seen during training. Finally, we also introduce an improved metric to evaluate 3D consistency of multi-view generations, and show that Pippo outperforms existing works on multi-view human generation from a single image.
Relightable Full-Body Gaussian Codec Avatars
Jan 24, 2025



We propose Relightable Full-Body Gaussian Codec Avatars, a new approach for modeling relightable full-body avatars with fine-grained details including face and hands. The unique challenge for relighting full-body avatars lies in the large deformations caused by body articulation and the resulting impact on appearance caused by light transport. Changes in body pose can dramatically change the orientation of body surfaces with respect to lights, resulting in both local appearance changes due to changes in local light transport functions, as well as non-local changes due to occlusion between body parts. To address this, we decompose the light transport into local and non-local effects. Local appearance changes are modeled using learnable zonal harmonics for diffuse radiance transfer. Unlike spherical harmonics, zonal harmonics are highly efficient to rotate under articulation. This allows us to learn diffuse radiance transfer in a local coordinate frame, which disentangles the local radiance transfer from the articulation of the body. To account for non-local appearance changes, we introduce a shadow network that predicts shadows given precomputed incoming irradiance on a base mesh. This facilitates the learning of non-local shadowing between the body parts. Finally, we use a deferred shading approach to model specular radiance transfer and better capture reflections and highlights such as eye glints. We demonstrate that our approach successfully models both the local and non-local light transport required for relightable full-body avatars, with a superior generalization ability under novel illumination conditions and unseen poses.
Sapiens: Foundation for Human Vision Models
Aug 22, 2024



We present Sapiens, a family of models for four fundamental human-centric vision tasks - 2D pose estimation, body-part segmentation, depth estimation, and surface normal prediction. Our models natively support 1K high-resolution inference and are extremely easy to adapt for individual tasks by simply fine-tuning models pretrained on over 300 million in-the-wild human images. We observe that, given the same computational budget, self-supervised pretraining on a curated dataset of human images significantly boosts the performance for a diverse set of human-centric tasks. The resulting models exhibit remarkable generalization to in-the-wild data, even when labeled data is scarce or entirely synthetic. Our simple model design also brings scalability - model performance across tasks improves as we scale the number of parameters from 0.3 to 2 billion. Sapiens consistently surpasses existing baselines across various human-centric benchmarks. We achieve significant improvements over the prior state-of-the-art on Humans-5K (pose) by 7.6 mAP, Humans-2K (part-seg) by 17.1 mIoU, Hi4D (depth) by 22.4% relative RMSE, and THuman2 (normal) by 53.5% relative angular error.
Score Distillation via Reparametrized DDIM
May 24, 2024While 2D diffusion models generate realistic, high-detail images, 3D shape generation methods like Score Distillation Sampling (SDS) built on these 2D diffusion models produce cartoon-like, over-smoothed shapes. To help explain this discrepancy, we show that the image guidance used in Score Distillation can be understood as the velocity field of a 2D denoising generative process, up to the choice of a noise term. In particular, after a change of variables, SDS resembles a high-variance version of Denoising Diffusion Implicit Models (DDIM) with a differently-sampled noise term: SDS introduces noise i.i.d. randomly at each step, while DDIM infers it from the previous noise predictions. This excessive variance can lead to over-smoothing and unrealistic outputs. We show that a better noise approximation can be recovered by inverting DDIM in each SDS update step. This modification makes SDS's generative process for 2D images almost identical to DDIM. In 3D, it removes over-smoothing, preserves higher-frequency detail, and brings the generation quality closer to that of 2D samplers. Experimentally, our method achieves better or similar 3D generation quality compared to other state-of-the-art Score Distillation methods, all without training additional neural networks or multi-view supervision, and providing useful insights into relationship between 2D and 3D asset generation with diffusion models.
From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations
Jan 03, 2024



We present a framework for generating full-bodied photorealistic avatars that gesture according to the conversational dynamics of a dyadic interaction. Given speech audio, we output multiple possibilities of gestural motion for an individual, including face, body, and hands. The key behind our method is in combining the benefits of sample diversity from vector quantization with the high-frequency details obtained through diffusion to generate more dynamic, expressive motion. We visualize the generated motion using highly photorealistic avatars that can express crucial nuances in gestures (e.g. sneers and smirks). To facilitate this line of research, we introduce a first-of-its-kind multi-view conversational dataset that allows for photorealistic reconstruction. Experiments show our model generates appropriate and diverse gestures, outperforming both diffusion- and VQ-only methods. Furthermore, our perceptual evaluation highlights the importance of photorealism (vs. meshes) in accurately assessing subtle motion details in conversational gestures. Code and dataset available online.
Drivable 3D Gaussian Avatars
Nov 14, 2023We present Drivable 3D Gaussian Avatars (D3GA), the first 3D controllable model for human bodies rendered with Gaussian splats. Current photorealistic drivable avatars require either accurate 3D registrations during training, dense input images during testing, or both. The ones based on neural radiance fields also tend to be prohibitively slow for telepresence applications. This work uses the recently presented 3D Gaussian Splatting (3DGS) technique to render realistic humans at real-time framerates, using dense calibrated multi-view videos as input. To deform those primitives, we depart from the commonly used point deformation method of linear blend skinning (LBS) and use a classic volumetric deformation method: cage deformations. Given their smaller size, we drive these deformations with joint angles and keypoints, which are more suitable for communication applications. Our experiments on nine subjects with varied body shapes, clothes, and motions obtain higher-quality results than state-of-the-art methods when using the same training and test data.